作业——11 分布式并行计算MapReduce
作业的要求来自于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3319
1.用自己的话阐明Hadoop平台上HDFS和MapReduce的功能、工作原理和工作过程。
HDFS
功能
分布式文件系统,用来存储海量数据。
工作原理
1、HDFS集群分为两大角色:NameNode、DataNode (Secondary Namenode)
2、NameNode负责管理整个文件系统的元数据
3、 DataNode 负责管理用户的文件数据块
4、 文件会按照固定的大小(blocksize)切成若干块后分布式存储在若干台datanode上
5、 每一个文件块可以有多个副本,并存放在不同的datanode上
6、Datanode会定期向Namenode汇报自身所保存的文件block信息,而namenode则会负责保持文件的副本数量
7、HDFS的内部工作机制对客户端保持透明,客户端请求访问HDFS都是通过向namenode申请来进行
工作过程
写操作
1、根namenode通信请求上传文件,namenode检查目标文件是否已存在,父目录是否存在
2、namenode返回是否可以上传
3、client请求第一个 block该传输到哪些datanode服务器上
4、namenode返回3个datanode服务器ABC
5、client请求3台dn中的一台A上传数据(本质上是一个RPC调用,建立pipeline),A收到请求会继续调用B,然后B调用C,将真个pipeline建立完成,逐级返回客户端
6、client开始往A上传第一个block(先从磁盘读取数据放到一个本地内存缓存),以packet为单位,A收到一个packet就会传给B,B传给C;A每传一个packet会放入一个应答队列等待应答
7、当一个block传输完成之后,client再次请求namenode上传第二个block的服务器。
读操作
1、跟namenode通信查询元数据,找到文件块所在的datanode服务器
2、挑选一台datanode(就近原则,然后随机)服务器,请求建立socket流
3、datanode开始发送数据(从磁盘里面读取数据放入流,以packet为单位来做校验)
4、客户端以packet为单位接收,现在本地缓存,然后写入目标文件
MapReduce
功能
并行处理框架,实现任务分解和调度。
工作原理
1、通过Job的submit()方法创建一个JobSummiter实例,并且调用其submitJobInternal()方法。
2、作业提交给ResourceManager,从ResourceMananger处得到一个ApplicationID
3、JobClien检查Job的输出说明,计算输入分片,并将Job资源(包括运行的Jar包、配置和分片信息)复制到HDFS
4、通过ResourceManager上的submitApplications进行作业提交
5、ResourceManager收到submitApplication()消息后,便将请求传递给调度器(scheduler)。调度器为其分配一个容器(Container),然后资源管理器在节点管理器(NodeManger)的管理下在Container中启动应用程序的master
6、初始化Job:通过创建多个簿记录对象以保持对作业进度的跟踪,因为它将接受来自任务的进度和完成报告
7、接受HDFS在Client端计算的输入分片信息
8、连接ResourceManager,向ResourceManager进行资源申请
9、Application master 通过与节点管理器(NodeManager)进行通信启动Container,该任务有主类为YarnChiled的Java程序执行。
10、在第9步之前,需要将任务需要的资源本地化,包括运行的Jar包、配置和分片信息和HDFS的文件
11、最后运行map任务或reduce任务。
工作过程
MapReduce的工作过程分为两个步骤:map和reduce。每个阶段的输入输出都是key-value的形式,key和value的类型可以自行指定。map阶段对切分好的数据进行并行处理,处理结果传输给reduce,由reduce函数完成最后的汇总。
2.HDFS上运行MapReduce
1)准备文本文件,放在本地/home/hadoop/wc

2)编写map函数和reduce函数,在本地运行测试通过
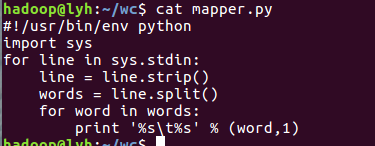

3)启动Hadoop:HDFS, JobTracker, TaskTracker
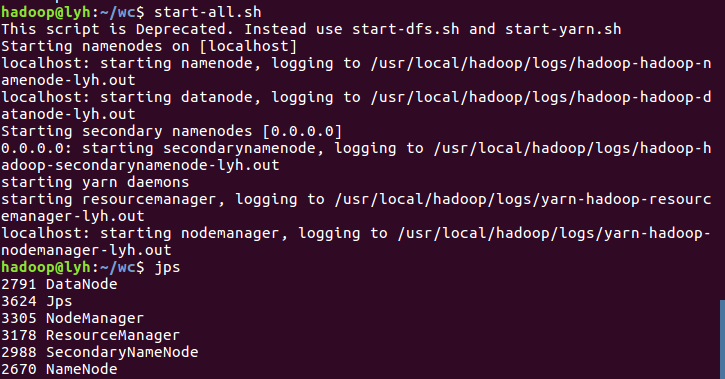
4)把文本文件上传到hdfs文件系统上 user/hadoop/input
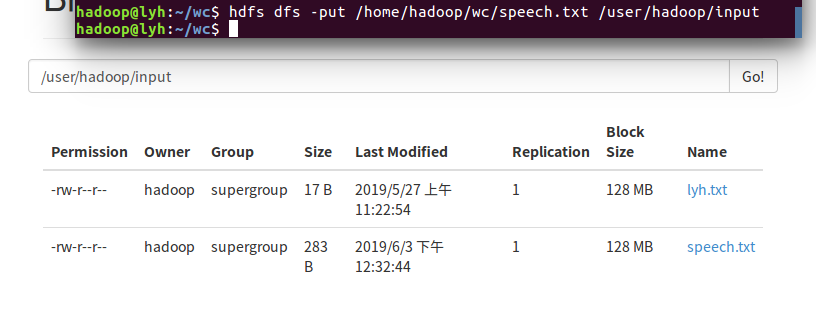
5)streaming的jar文件的路径写入环境变量,让环境变量生效

6)建立一个shell脚本文件:streaming接口运行的脚本,名称为run.sh

7)source run.sh来执行mapreduce
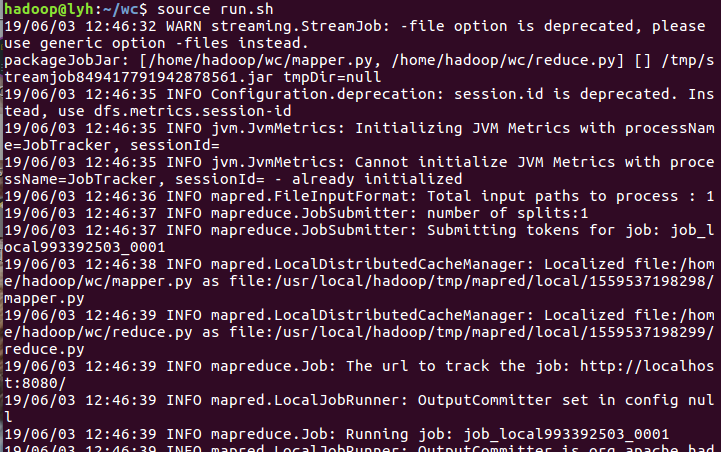
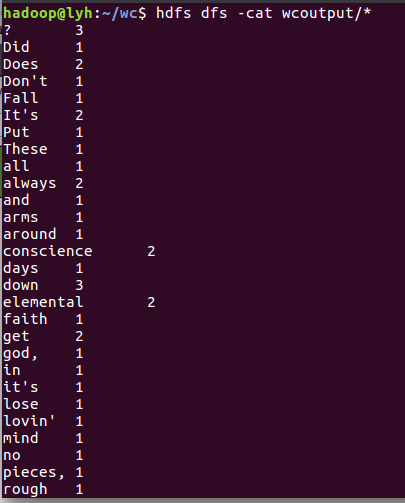
8)查看运行结果
作业——11 分布式并行计算MapReduce的更多相关文章
- 【大数据作业十一】分布式并行计算MapReduce
作业要求:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3319 1.用自己的话阐明Hadoop平台上HDFS和MapReduce的功 ...
- 【大数据应用技术】作业十一|分布式并行计算MapReduce
本次作业在要求来自:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3319 1.用自己的话阐明Hadoop平台上HDFS和MapRe ...
- 分布式并行计算MapReduce
作业要求来自:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3319 1.用自己的话阐明Hadoop平台上HDFS和MapReduce ...
- 【大数据】分布式并行计算MapReduce
作业来源于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3319 1. 用自己的话阐明Hadoop平台上HDFS和MapReduc ...
- Hadoop平台K-Means聚类算法分布式实现+MapReduce通俗讲解
Hadoop平台K-Means聚类算法分布式实现+MapReduce通俗讲解 在Hadoop分布式环境下实现K-Means聚类算法的伪代码如下: 输入:参数0--存储样本数据的文本文件inpu ...
- 经典MapReduce作业和Yarn上MapReduce作业运行机制
一.经典MapReduce的作业运行机制 如下图是经典MapReduce作业的工作原理: 1.1 经典MapReduce作业的实体 经典MapReduce作业运行过程包含的实体: 客户端,提交MapR ...
- #研发解决方案#分布式并行计算调度和管理系统Summoner
郑昀 创建于2015/11/10 最后更新于2015/11/12 关键词:佣金计算.定时任务.数据抽取.数据清洗.数据计算.Java.Redis.MySQL.Zookeeper.azkaban2.oo ...
- 利用 MessageRPC 和 ShareMemory 来实现 分布式并行计算
可以利用 MessageRPC + ShareMemory 来实现 分布式并行计算 . MessageRPC : https://www.cnblogs.com/KSongKing/p/945541 ...
- C语言I作业11
C语言 博客作业11 问题 回答 C语言程序设计II 博客作业11 这个作业要求在哪里 作业要求 我在这个课程的目标是 理解和弄懂局部变量和全局变量,静态变量和动态变量 这个作业在哪个具体方面帮助我实 ...
随机推荐
- 旋转图像 给定一个 n × n 的二维矩阵表示一个图像。
给定一个 n × n 的二维矩阵表示一个图像. 将图像顺时针旋转 90 度. 说明: 你必须在原地旋转图像,这意味着你需要直接修改输入的二维矩阵.请不要使用另一个矩阵来旋转图像. 示例 : 给定 ma ...
- 继 首次使用DoNetCore EFCore DbFirst 更新数据实体
//EFCore DB First 步骤 //第一步:Install-Package Microsoft.EntityFrameworkCore.SqlServer -version 2.1.1 // ...
- Swagger Liunx环境搭建(亲测百分百可用)
一.安装nodejs 下载编译好的nodejs安装包,下载地址: https://nodejs.org/dist/v10.10.0/ (作者下载的10.10.0,可根据自己需要下载不同版本) 将下载好 ...
- Mac FFmpeg编译和解决nasm/yasm not found or too old错误
FFmpeg编译下载代码:git clone https://git.ffmpeg.org/ffmpeg.git然后输入命令进行编译:找到下载的目录下,然后用命令进入这个文件夹下cd ffmpeg,然 ...
- 前端框架 Vue.js 概述
Vue.js 是什么 图片 Vue (读音 /vjuː/,类似于 view) 是一套用于构建用户界面的渐进式框架.与其它大型框架不同的是,Vue 被设计为可以自底向上逐层应用.Vue 的核心库只关注视 ...
- Python并发编程-线程同步(线程安全)
Python并发编程-线程同步(线程安全) 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 线程同步,线程间协调,通过某种技术,让一个线程访问某些数据时,其它线程不能访问这些数据,直 ...
- GTID主从与传统主从复制
目录 1.主从复制 2.靠什么同步 3.pos与GTID的什么区别 4.GTID的工作原理 5.GTID参数配置 5.1 在主数据库里创建一个同步账号授权给从数据库使用 5.2 配置主数据库 5.3配 ...
- 【转】GnuPG使用介绍
一.什么是 GPG 要了解什么是 GPG,就要先了解 PGP. 1991 年,程序员 Phil Zimmermann 为了避开政府监视,开发了加密软件 PGP.这个软件非常好用,迅速流传开来,成了许多 ...
- 《TensorFlow2深度学习》学习笔记(四)对笔记二中的模型增加正确率展示
全部代码如下:(红色部分为与笔记二不同之处) #1.Import the neccessary libraries needed import numpy as np import tensorflo ...
- git上传者姓名修改
只需要两个指令 git config user.name 和 git config –global user.name 在控制台中输入git config user.name获取当前的操作名称 修改名 ...