分布式并行计算MapReduce
作业要求来自:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3319
1.用自己的话阐明Hadoop平台上HDFS和MapReduce的功能、工作原理和工作过程。
HDFS(Hadoop Distributed File System,Hadoop分布式文件系统),它是一个高度容错性的系统,适合部署在廉价的机器上。HDFS能提供高吞吐量的数据访问,适合那些有着超大数据集(large data set)的应用程序。
易于扩展的分布式文件系统
运行在大量普通廉价机器上,提供容错机制
为大量用户提供性能不错的文件存取服务
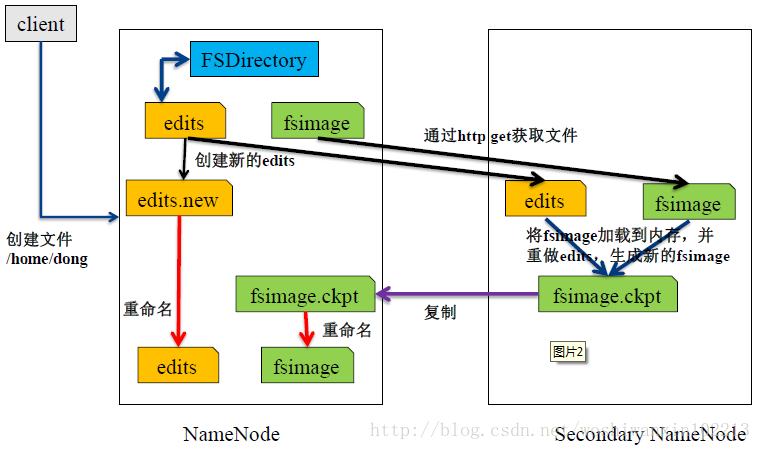
MapReduce是并行处理框架,实现任务分解和调度。
其实原理说通俗一点就是分而治之的思想,将一个大任务分解成多个小任务(map),小任务执行完了之后,合并计算结果(reduce)。
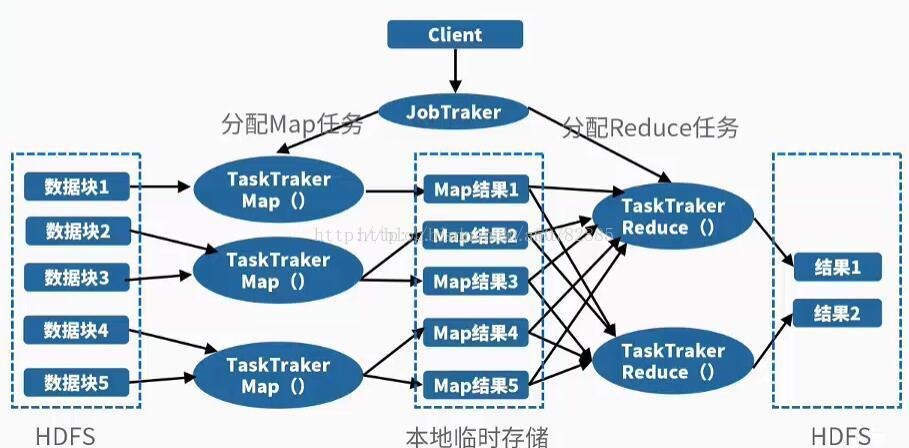
也就是说,JobTracker拿到job之后,会把job分成很多个maptask和reducetask,交给他们执行。 MapTask、ReduceTask函数的输入、输出都是<key,value>的形式。HDFS存储的输入数据经过解析后,以键值对的形式,输入到MapReduce()函数中进行处理,输出一系列键值对作为中间结果,在Reduce阶段,对拥有同样Key值的中间数据进行合并形成最后结果。
2.HDFS上运行MapReduce
1)查看是否已经安装python:
1)准备文本文件,放在本地/home/hadoop/wc

2)编写map函数和reduce函数,在本地运行测试通过


3)启动Hadoop:HDFS, JobTracker, TaskTracker
4)把文本文件上传到hdfs文件系统上 user/hadoop/input

5)streaming的jar文件的路径写入环境变量,让环境变量生效

6)source run.sh来执行mapreduce

分布式并行计算MapReduce的更多相关文章
- 作业——11 分布式并行计算MapReduce
作业的要求来自于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3319 1.用自己的话阐明Hadoop平台上HDFS和MapRedu ...
- 【大数据】分布式并行计算MapReduce
作业来源于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3319 1. 用自己的话阐明Hadoop平台上HDFS和MapReduc ...
- 【大数据作业十一】分布式并行计算MapReduce
作业要求:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3319 1.用自己的话阐明Hadoop平台上HDFS和MapReduce的功 ...
- 【大数据应用技术】作业十一|分布式并行计算MapReduce
本次作业在要求来自:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3319 1.用自己的话阐明Hadoop平台上HDFS和MapRe ...
- Hadoop平台K-Means聚类算法分布式实现+MapReduce通俗讲解
Hadoop平台K-Means聚类算法分布式实现+MapReduce通俗讲解 在Hadoop分布式环境下实现K-Means聚类算法的伪代码如下: 输入:参数0--存储样本数据的文本文件inpu ...
- #研发解决方案#分布式并行计算调度和管理系统Summoner
郑昀 创建于2015/11/10 最后更新于2015/11/12 关键词:佣金计算.定时任务.数据抽取.数据清洗.数据计算.Java.Redis.MySQL.Zookeeper.azkaban2.oo ...
- 利用 MessageRPC 和 ShareMemory 来实现 分布式并行计算
可以利用 MessageRPC + ShareMemory 来实现 分布式并行计算 . MessageRPC : https://www.cnblogs.com/KSongKing/p/945541 ...
- hadoop基础----hadoop理论(四)-----hadoop分布式并行计算模型MapReduce具体解释
我们在前一章已经学习了HDFS: hadoop基础----hadoop理论(三)-----hadoop分布式文件系统HDFS详细解释 我们已经知道Hadoop=HDFS(文件系统,数据存储技术相关)+ ...
- cdh版本的hadoop安装及配置(伪分布式模式) MapReduce配置 yarn配置
安装hadoop需要jdk依赖,我这里是用jdk8 jdk版本:jdk1.8.0_151 hadoop版本:hadoop-2.5.0-cdh5.3.6 hadoop下载地址:链接:https://pa ...
随机推荐
- js数组【续】(相关方法)
一.数组的栈,队列方法[调用这些方法原数组会发生改变]var arr = [2,3,4,5,6];1.栈 LIFO (Last-In-First-Out)a.push() 可接受任意类型的参数,将它们 ...
- Node.js实现用户评论社区(体验前后端开发的乐趣)
前面 接着上一节的内容来,今天我们要完成一个用Node开发后台服务器,实现一个简单的用户评论社区.可以先看下效果图: 开始 建立项目文件夹comment-list,在里面新建一个public文件夹,p ...
- C#-使用GoogleAPI读写spreadsheets
https://docs.google.com/spreadsheets/在线使用一些常用办公工具,比如excel. 如需要C#代码自动读写这些excel,则需要使用GoogleAPI. 封装的公用类 ...
- 【转】SetWindowText 的用法
SetWindowTextW表示设置的字符串是WCHAR (双字节字符 )SetWindowTextA表示设置的字符串是CHAR (单字节字符 )SetWindowText表示设置的字符串是自动匹配当 ...
- 微信小程序转义解析渲染html
今天开发小程序时,想调用商品详情字段,发现大部分是用编辑器编辑的html原生标签,无法在小程序直接使用. 后面自己使用正则和字符串替换,效果也不佳. 最后在网上找到了wx-mina-html-view ...
- 泛微 e-cology OA 远程代码执行漏洞复现
0x00 前言 Poc已在github公开,由于环境搭建较为复杂,所以我在空间搜索引擎中找了国外的网站进行复现 如果有想自行搭建环境复现的可以在公众号内回复“泛微环境”即可获取源码及搭建方式 0x01 ...
- 剑指Offer(二十):包含min函数的栈
剑指Offer(二十):包含min函数的栈 搜索微信公众号:'AI-ming3526'或者'计算机视觉这件小事' 获取更多算法.机器学习干货 csdn:https://blog.csdn.net/ba ...
- 解决 Vue 刷新页面后 store 数据丢失的问题
原来的状态(页面刷新数据会重置) state: { teamA: '主队' }, mutations: { data_teamA(state, x) { state.teamA = x } }, ...
- 2019年牛客多校第一场 I题Points Division 线段树+DP
题目链接 传送门 题意 给你\(n\)个点,每个点的坐标为\((x_i,y_i)\),有两个权值\(a_i,b_i\). 现在要你将它分成\(\mathbb{A},\mathbb{B}\)两部分,使得 ...
- 摘:J2EE开发环境搭建(1)——安装JDK、Tomcat、Eclipse
J2EE开发环境搭建(1)——安装JDK.Tomcat.Eclipse 1:背景 进公司用SSH(Struts,spring和hibernate)开发已经有两个月了,但由于一 直要么只负责表示层的开发 ...