python爬取盘搜的有效链接
因为盘搜搜索出来的链接有很多已经失效了,影响找数据的效率,因此想到了用爬虫来过滤出有效的链接,顺便练练手~
这是本次爬取的目标网址http://www.pansou.com,首先先搜索个python,之后打开开发者工具,
可以发现这个链接下的json数据就是我们要爬取的数据了,把多余的参数去掉,
剩下的链接格式为http://106.15.195.249:8011/search_new?q=python&p=1,q为搜索内容,p为页码
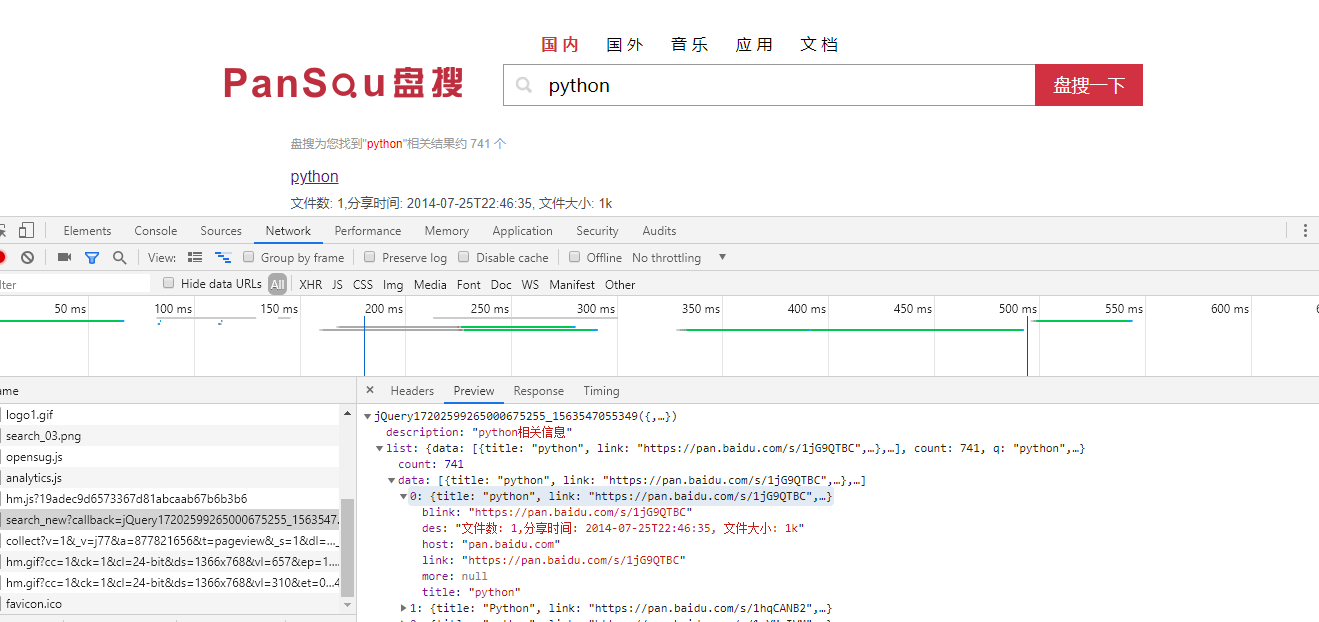
以下是代码实现:
import requests
import json
from multiprocessing.dummy import Pool as ThreadPool
from multiprocessing import Queue
import sys headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36"
}
q1 = Queue()
q2 = Queue()
urls = [] # 存取url列表 # 读取url
def get_urls(query):
# 遍历50页
for i in range(1,51):
# 要爬取的url列表,返回值是json数据,q参数是搜索内容,p参数是页码
url = "http://106.15.195.249:8011/search_new?&q=%s&p=%d" % (query,i)
urls.append(url) # 获取数据
def get_data(url):
print("开始加载,请等待...")
# 获取json数据并把json数据转换为字典
resp = requests.get(url, headers=headers).content.decode("utf-8")
resp = json.loads(resp) # 如果搜素数据为空就抛出异常停止程序
if resp['list']['data'] == []:
raise Exception # 遍历每一页数据的长度
for num in range(len(resp['list']['data'])):
# 获取百度云链接
link = resp['list']['data'][num]['link']
# 获取标题
title = resp['list']['data'][num]['title']
# 访问百度云链接,判断如果页面源代码中有“失效时间:”这段话的话就表明链接有效,链接无效的页面是没有这段话的
link_content = requests.get(link, headers=headers).content.decode("utf-8")
if "失效时间:" in link_content:
# 把标题放进队列1
q1.put(title)
# 把链接放进队列2
q2.put(link)
# 写入csv文件
with open("wangpanziyuan.csv", "a+", encoding="utf-8") as file:
file.write(q1.get()+","+q2.get() + "\n")
print("ok") if __name__ == '__main__':
# 括号内填写搜索内容
get_urls("python")
# 创建线程池
pool = ThreadPool(3)
try:
results = pool.map(get_data, urls)
except Exception as e:
print(e)
pool.close()
pool.join()
print("退出")
python爬取盘搜的有效链接的更多相关文章
- Python爬取热搜存入数据库并且还能定时发送邮件!!!
一.前言 微博热搜榜每天都会更新一些新鲜事,但是自己处于各种原因,肯定不能时刻关注着微博,为了与时代接轨,接受最新资讯,就寻思着用Python写个定时爬取微博热搜的并且发送QQ邮件的程序,这样每天可以 ...
- Python 爬虫实战—盘搜搜
近期公司给了个任务:根据关键搜索百度网盘共享文件并下载. 琢磨了几天写下了一段简单的demo代码,后期优化没有处理. 主要的思路:(1)根据关键字爬取盘搜搜的相关信息 (2)解析并获取盘搜搜跳转到百度 ...
- python爬取博客圆首页文章链接+标题
新人一枚,初来乍到,请多关照 来到博客园,不知道写点啥,那就去瞄一瞄大家都在干什么好了. 使用python 爬取博客园首页文章链接和标题. 首先当然是环境了,爬虫在window10系统下,python ...
- Python爬取网易云音乐歌手歌曲和歌单
仅供学习参考 Python爬取网易云音乐网易云音乐歌手歌曲和歌单,并下载到本地 很多人学习python,不知道从何学起.很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手.很多已经做 ...
- 使用python爬取MedSci上的期刊信息
使用python爬取medsci上的期刊信息,通过设定条件,然后获取相应的期刊的的影响因子排名,期刊名称,英文全称和影响因子.主要过程如下: 首先,通过分析网站http://www.medsci.cn ...
- 使用python爬取百度贴吧内的图片
1. 首先通过urllib获取网页的源码 # 定义一个getHtml()函数 def getHtml(url): try: page = urllib.urlopen(url) # urllib.ur ...
- Python爬取南京市往年天气预报,使用pyecharts进行分析
上一次分享了使用matplotlib对爬取的豆瓣书籍排行榜进行分析,但是发现python本身自带的这个绘图分析库还是有一些局限,绘图不够美观等,在网上搜索了一波,发现现在有很多的支持python的绘图 ...
- python 爬取历史天气
python 爬取历史天气 官网:http://lishi.tianqi.com/luozhuangqu/201802.html # encoding:utf-8 import requests fr ...
- python爬取人民币汇率中间价
python爬取人民币汇率中间价,从最权威的网站中国外汇交易中心. 首先找到相关网页,解析链接,这中间需要经验和耐心,在此不多说. 以人民币兑美元的汇率为例(CNY/USD),脚本详情如下: wind ...
随机推荐
- postman上传excel,java后台读取excel生成到指定位置进行备份,并且把excel中的数据添加到数据库
最近要做个前端网页上传excel,数据直接添加到数据库的功能..在此写个读取excel的demo. 首先新建springboot的web项目 导包,读取excel可以用poi也可以用jxl,这里本文用 ...
- MySql的动态语句foreach各种用法比较
1.单参数List的类型: 上述collection的值为list,对应的Mapper是这样的 2.单参数array数组的类型: 上述collection为array,对应的Mapper代码: 3.自 ...
- [Linux] scp指令用法
scp 指令用法 # scp usage: scp [-12346BCpqrv] [-c cipher] [-F ssh_config] [-i identity_file] [-l limit] [ ...
- Oracle语法 及 SQL题目(三)
目录 SQL题目六 第一个问题思路(查询酒类商品的总点击量) 第二个问题思路(查询每个类别所属商品的总点击量,并按降序排列) 第三个问题思路(查询所有类别中最热门的品种(点击量最高),并按点击量降顺序 ...
- 在 delphi (Object Pascal 语言)中,使用 array 关键字进行数组定义。
如果需要定义二维数组可以采取以下定义形式: 一.静态数组定义 静态数组定义,通常用于数组元素的数目确定的情况.定义形式如下: 示例: 1 2 3 4 5 6 7 8 9 10 11 type // ...
- useReducer代替Redux小案例-2(八)
通过上节课的学习,用useContext实现了Redux状态共享的能力,这节课看一下如何使用useReducer来实现业务逻辑的控制.需要注意的是这节课的内容是接着上节课的,需要你把上节课的代码部分完 ...
- storcli64和smartctl定位硬盘的故障信息
storcli64可对LSIRAID卡基本操作进行管理,本文主要是对LSIRAID卡常使用到的命令进行介绍 https://www.cnblogs.com/wangl-blog/archive/201 ...
- 005 Spring和SpringBoot中的@Component 和@ComponentScan注解
今天在看@ComponentScan,感觉不是太理解,下面做一个说明. 1.说明 ComponentScan做的事情就是告诉Spring从哪里找到bean 2.细节说明 如果你的其他包都在使用了@Sp ...
- Tomcat redis session manager connect redis show: ERR Client sent AUTH, but no password is set
解决问题redis问题:ERR Client sent AUTH, but no password is set - 东篱煮酒 - 博客园https://www.cnblogs.com/niepeis ...
- AndoridSQLite数据库开发基础教程(9)
AndoridSQLite数据库开发基础教程(9) 添加视图 视图是从一个或几个基本表(或视图)中导出的虚拟的表.通过视图可以看到表的内容.下面为数据库添加视图,操作步骤如下: (1)打开的数据库,单 ...