python爬取盘搜的有效链接
因为盘搜搜索出来的链接有很多已经失效了,影响找数据的效率,因此想到了用爬虫来过滤出有效的链接,顺便练练手~
这是本次爬取的目标网址http://www.pansou.com,首先先搜索个python,之后打开开发者工具,
可以发现这个链接下的json数据就是我们要爬取的数据了,把多余的参数去掉,
剩下的链接格式为http://106.15.195.249:8011/search_new?q=python&p=1,q为搜索内容,p为页码
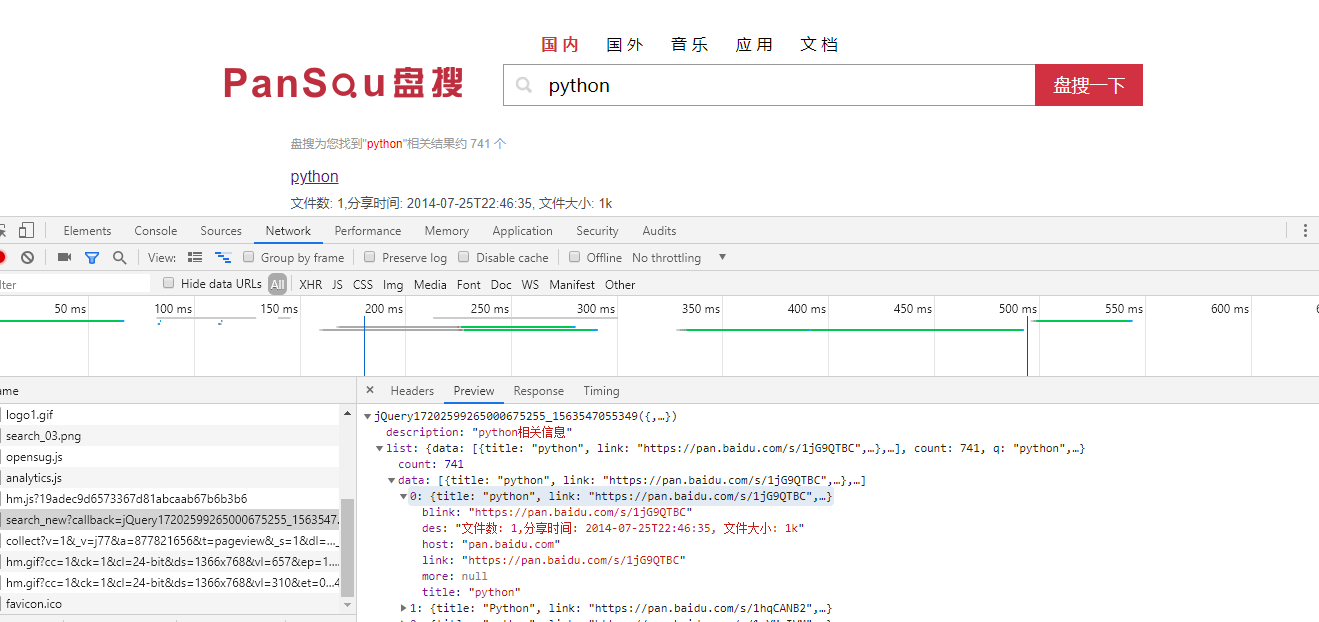
以下是代码实现:
import requests
import json
from multiprocessing.dummy import Pool as ThreadPool
from multiprocessing import Queue
import sys headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36"
}
q1 = Queue()
q2 = Queue()
urls = [] # 存取url列表 # 读取url
def get_urls(query):
# 遍历50页
for i in range(1,51):
# 要爬取的url列表,返回值是json数据,q参数是搜索内容,p参数是页码
url = "http://106.15.195.249:8011/search_new?&q=%s&p=%d" % (query,i)
urls.append(url) # 获取数据
def get_data(url):
print("开始加载,请等待...")
# 获取json数据并把json数据转换为字典
resp = requests.get(url, headers=headers).content.decode("utf-8")
resp = json.loads(resp) # 如果搜素数据为空就抛出异常停止程序
if resp['list']['data'] == []:
raise Exception # 遍历每一页数据的长度
for num in range(len(resp['list']['data'])):
# 获取百度云链接
link = resp['list']['data'][num]['link']
# 获取标题
title = resp['list']['data'][num]['title']
# 访问百度云链接,判断如果页面源代码中有“失效时间:”这段话的话就表明链接有效,链接无效的页面是没有这段话的
link_content = requests.get(link, headers=headers).content.decode("utf-8")
if "失效时间:" in link_content:
# 把标题放进队列1
q1.put(title)
# 把链接放进队列2
q2.put(link)
# 写入csv文件
with open("wangpanziyuan.csv", "a+", encoding="utf-8") as file:
file.write(q1.get()+","+q2.get() + "\n")
print("ok") if __name__ == '__main__':
# 括号内填写搜索内容
get_urls("python")
# 创建线程池
pool = ThreadPool(3)
try:
results = pool.map(get_data, urls)
except Exception as e:
print(e)
pool.close()
pool.join()
print("退出")
python爬取盘搜的有效链接的更多相关文章
- Python爬取热搜存入数据库并且还能定时发送邮件!!!
一.前言 微博热搜榜每天都会更新一些新鲜事,但是自己处于各种原因,肯定不能时刻关注着微博,为了与时代接轨,接受最新资讯,就寻思着用Python写个定时爬取微博热搜的并且发送QQ邮件的程序,这样每天可以 ...
- Python 爬虫实战—盘搜搜
近期公司给了个任务:根据关键搜索百度网盘共享文件并下载. 琢磨了几天写下了一段简单的demo代码,后期优化没有处理. 主要的思路:(1)根据关键字爬取盘搜搜的相关信息 (2)解析并获取盘搜搜跳转到百度 ...
- python爬取博客圆首页文章链接+标题
新人一枚,初来乍到,请多关照 来到博客园,不知道写点啥,那就去瞄一瞄大家都在干什么好了. 使用python 爬取博客园首页文章链接和标题. 首先当然是环境了,爬虫在window10系统下,python ...
- Python爬取网易云音乐歌手歌曲和歌单
仅供学习参考 Python爬取网易云音乐网易云音乐歌手歌曲和歌单,并下载到本地 很多人学习python,不知道从何学起.很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手.很多已经做 ...
- 使用python爬取MedSci上的期刊信息
使用python爬取medsci上的期刊信息,通过设定条件,然后获取相应的期刊的的影响因子排名,期刊名称,英文全称和影响因子.主要过程如下: 首先,通过分析网站http://www.medsci.cn ...
- 使用python爬取百度贴吧内的图片
1. 首先通过urllib获取网页的源码 # 定义一个getHtml()函数 def getHtml(url): try: page = urllib.urlopen(url) # urllib.ur ...
- Python爬取南京市往年天气预报,使用pyecharts进行分析
上一次分享了使用matplotlib对爬取的豆瓣书籍排行榜进行分析,但是发现python本身自带的这个绘图分析库还是有一些局限,绘图不够美观等,在网上搜索了一波,发现现在有很多的支持python的绘图 ...
- python 爬取历史天气
python 爬取历史天气 官网:http://lishi.tianqi.com/luozhuangqu/201802.html # encoding:utf-8 import requests fr ...
- python爬取人民币汇率中间价
python爬取人民币汇率中间价,从最权威的网站中国外汇交易中心. 首先找到相关网页,解析链接,这中间需要经验和耐心,在此不多说. 以人民币兑美元的汇率为例(CNY/USD),脚本详情如下: wind ...
随机推荐
- python 两个字典对比
def commir_two_dict(dictone,dicttwo): pass_num=0 fail_num=0 try: for i in dictone.keys(): if i in di ...
- IntelliJ IDEA配置Tomcat运行web项目
小白一枚,借鉴了好多人的博客,然后自己总结了一些图,尽量的详细.在配置的过程中,有许多疑问.如果读者看到后能给我解答的,请留言.Idea请各位自己安装好,还需要安装Maven和Tomcat,各自配置好 ...
- ubuntu之路——day10.6 如何理解人类表现和超过人类表现
从某种角度来说,已知的人类最佳表现其实可以被当做贝叶斯最优错误,对于医学图像分类可以参见下图中的例子. 那么如何理解超过人类表现,在哪些领域机器已经做到了超越人类呢?
- Set详解
Set集合: 元素不可重复 hashCode 特点:速度快,数组->链表->红黑树 set集合报错元素唯一: 存储元素(String,Interger,....Student,Person ...
- T-MAX--冲刺合集
目录 设想和目标 计划 资源 变更管理 设计/实现 测试/发布 团队的角色,管理,合作 总结 照片 各组员对于最终项目成果的贡献度 这个作业属于哪个课程 2019秋福大软件工程实践Z班 (福州大学) ...
- python 二维码
pip3 install Pillow pip3 install qrcode import qrcode text ="gisoracle我爱你呀" #input("输 ...
- Java HashSet介绍
HashSet底层使用HashMap实现.当使用add方法将对象添加到Set当中时,实际上是将该对象作为底层所维护的Map对象的key,而value则都是同一个Object对象(该对象我们用不上). ...
- MD5与SHA1
一.MD5 MD5消息摘要算法(英语:MD5 Message-Digest Algorithm),一种被广泛使用的密码散列函数,可以产生出一个128位(16字节)的散列值(hash value),用于 ...
- Perf -- Linux下的系统性能调优工具,第 1 部分 应用程序调优的使用和示例 Tracepoint 是散落在内核源代码中的一些 hook,一旦使能,它们便可以在特定的代码被运行到时被触发,这一特性可以被各种 trace/debug 工具所使用。Perf 就是该特性的用户之一。
Perf -- Linux下的系统性能调优工具,第 1 部分 应用程序调优的使用和示例 https://www.ibm.com/developerworks/cn/linux/l-cn-perf1/i ...
- C++提示没有与这些操作数匹配的<<运算符
应该是忘了#include.#include<string>