论文阅读笔记六十:Squeeze-and-Excitation Networks(SENet CVPR2017)

论文原址:https://arxiv.org/abs/1709.01507
github:https://github.com/hujie-frank/SENet
摘要
卷积网络的关键构件是卷积操作,在每层感受野的范围内通过融合局部及channel-wise信息可以使网络构建特征。一些研究关注空间组件,通过增强空间特征等级的编码能力在增强表示力。本文重点在于通道之间的联系,提出了SENet block,通过对通道之间的独立性建模来自适应的调整通道之间的响应。可以将这些block进行堆叠得到SENet的结构。
介绍
在卷积网络的每一层,一些卷积核沿着输入通道方向表示相邻特征模式,在局部感受野的范围内融合空间及channel-wise特征信息。通过交错的组合卷积,下采样,非线性层等构建网络。CNN可以得到粗略的表示能力从而可以获得分级的模式,同时具有一定的感受野。一些实验发现可以通过将可以捕捉特征之间信息的一些学习机制融合到网路中进而可以提高网络的表示能力。Inception系列的网络通过结合多个尺寸的卷积核来提高性能。
本文不同于以前的网络,重点放在特征通道之间的联系上,本文引入了一个新的结构单元SE block,通过对卷积特征之间的联系进行建模来增强表示能力,最后,本文提出了一种特征校准机制,通过学习全局信息进而可以选择一些有用的特征,而压制作用较小的特征。
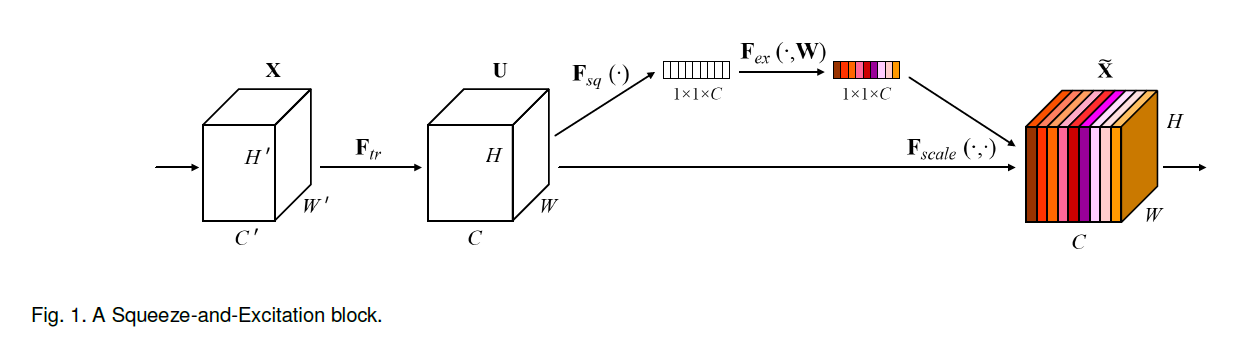
SE building block的结构如下图所示,对于任意的特征变换,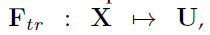
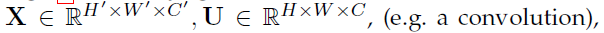 本文都可以构建SE block进行特征校准。特征U首先会进行一个squeeze操作,产生一个通道描述器,其在对应空间维度上(HxW)融合feature maps。描述器函数的作用是channel-wise响应的全局分布的编码,可以使来自全局感受野的信息可以被所有层利用。Squeeze操纵后面跟着一个excetion操作。采用一个简单的门机制,将编码的信息作为输入,同时产生每个通道调制的权重。这些权重又反过来作用于feature map U用于产生SE的输出进而送入到后续处理中。
本文都可以构建SE block进行特征校准。特征U首先会进行一个squeeze操作,产生一个通道描述器,其在对应空间维度上(HxW)融合feature maps。描述器函数的作用是channel-wise响应的全局分布的编码,可以使来自全局感受野的信息可以被所有层利用。Squeeze操纵后面跟着一个excetion操作。采用一个简单的门机制,将编码的信息作为输入,同时产生每个通道调制的权重。这些权重又反过来作用于feature map U用于产生SE的输出进而送入到后续处理中。
可以通过简单的堆叠SE block进行构建SENet。SE block可以作为网络的一部分插入到网络的某一层中。虽然block整体相似,但是在网络中的不同深度,其性能也是不同的。在较前层,以类别不可知的情形激发信息特征。在网络的后层,SE block增长的较为明确,以类别可分的模式对不同的输入产生响应。
总之,SE 特征校准得到的性能可以在网络中进行累计。新的CNN网络的搭建十分复杂,涉及到新参数及层的配置等。而SE模块简单,可以直接替换网络中的模型。
相关工作
更深的网络:VGG及Inception表明,增加网络的深度可以提高模型的表示能力及学习能力。对输入分布进行正则化处理。在每层添加固定的BN层,同时,产生更平滑的外形边界。ResNet通过identity-based的跳跃结构可以实现更深的网络。Highways 网络对短连接中的信息流进行正则化处理。
一些工作着眼于改进网络中包含的函数的计算形式。分组卷积已经成功应用于增加学习变换基数的方法。交叉通道相关性映射到一个新的特征组合,与空间结构无关,或者通过1x1的卷积进行联合处理。大部分研究工作聚焦于减少模型及计算复杂度上。这里折射出一个假设就是通道关系可以看作是在局部感受野下与实例无关的函数组合。本文提出一种机制可以通过全局信息直接对通道之间的动态以及非线性依赖性进行建模。
算法结构搜索:该部分工作主要位于神经进化领域,基于进化算法对网络的拓扑结构进行搜索。然而,需要消耗大量的计算力。该方法在连续模型中找到记忆单元及分类模型中学习固定结构取得较大的成功。为了减少计算力,基于Lamarckian inheritance及不同的结构的高效的可替代算法被提出。通过将结构搜索看作是参数优化问题,随机搜索及其他传统的优化技术可以用于处理该问题。SE 可以基于搜索算法自动的进行build block。
注意力及门机制:注意力机制可以看作是将计算资源分配信息量最重要的部分。其后接一个或者多个操作来表示更抽象的特征信息。本文SE block为轻量级门机制,通过对通道进行建模来提高模型的表示能力。
Squeeze and excitation block
SE为计算单元,可以由任意输入变换构建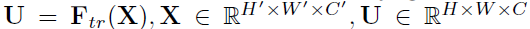 为方便起见,本文将Ftr看作是卷积操作。
为方便起见,本文将Ftr看作是卷积操作。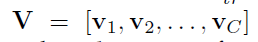 代表可学习的卷积核集合。其中,vc代表第c个卷积核的参数。Ftr的输出表示如下,*代表卷积,
代表可学习的卷积核集合。其中,vc代表第c个卷积核的参数。Ftr的输出表示如下,*代表卷积,

其中,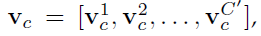 X =
X = 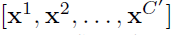 ,
, 为一个2D核,表示vc的一个通道与对应的x的通道进行卷积。由于结果是所有通道相加和。vc中存在潜在的依赖关系,但其与由卷积核得到的局部空间相关性纠缠在一起。因此,由卷积形成的通道关系是局部的。由于本文的目的是为了提高模型对信息特征的敏感性,以便后续的变换能够更有效的利用这写信息特征。本文增加了其获得全局信息的能力。本文通过两步来对通道的独立性进行建模进而重新校准filter 响应,即Squeeze及Excetitation。SE block的结构如上图所示。
为一个2D核,表示vc的一个通道与对应的x的通道进行卷积。由于结果是所有通道相加和。vc中存在潜在的依赖关系,但其与由卷积核得到的局部空间相关性纠缠在一起。因此,由卷积形成的通道关系是局部的。由于本文的目的是为了提高模型对信息特征的敏感性,以便后续的变换能够更有效的利用这写信息特征。本文增加了其获得全局信息的能力。本文通过两步来对通道的独立性进行建模进而重新校准filter 响应,即Squeeze及Excetitation。SE block的结构如上图所示。
Squeeze: Global Information Embeding
为了解决利用channel 依赖性的如何利用的问题,本文首先考虑输出特征的每个通道。每个可学习的卷积核都是在局部感受野内进行操作,因此,区域外的上下文信息无法被后续的变换单元U利用。
为此,本文提出将全局空间信息进行压缩得到一个单通道描述器。通过一个全局的平均池化操作来实现通道级别的统计。一般,一个统计量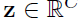 ,通过在空间维度HxW上压缩U实现。z中的第c个单元计算如下
,通过在空间维度HxW上压缩U实现。z中的第c个单元计算如下
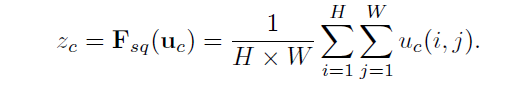
变换U的输出可以解释为,一些局部描述器的统计信息可以表示整个图像。
Excetitation: Adaptive Recalibration
为了利用由Squeeze聚合得到的信息。后面接了一些操作用于捕捉通道的独立信息。其操作函数必须满足两个标准,I.具有灵活性。其必须能够学习通道之间的非线性。II.能够学习非互斥关系。这是由于需要对多个通道的特征信息进行强调,而不是类似one-hot表示那样。本文选择了一个简单的sigmoid激活函数作为gating 机制。

为了限制模型的计算量,及有利于泛化,本文在非线性部分,比如,降维层W及减少比率r,ReLU+升维层添加两层全连接层来构建bootleneck进而对gating机制进行参数化。block的最终输出如下
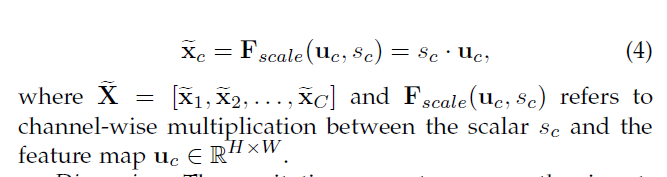
Excetitation通过将输入明确的描述器映射为一系列通道确定的权重。SEblock提高了特征的辨别性。
实例
SE block可以整合到常规的卷积网络中,一般在插入非线性区域后增加几个卷积层。本文以Inception网络为例如下。
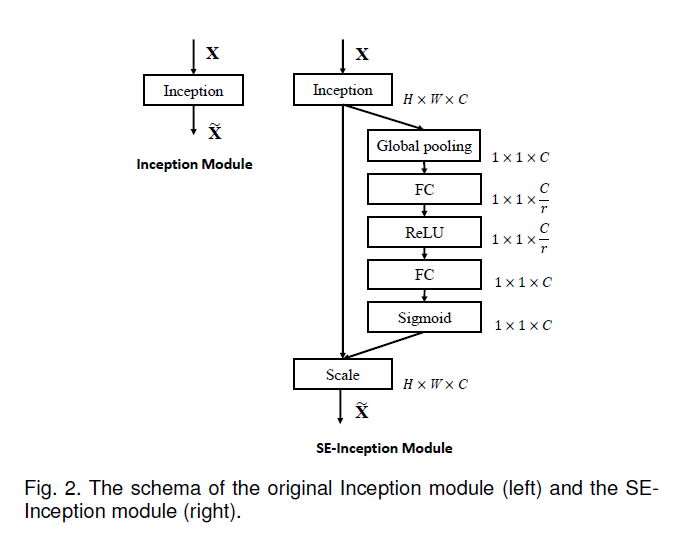
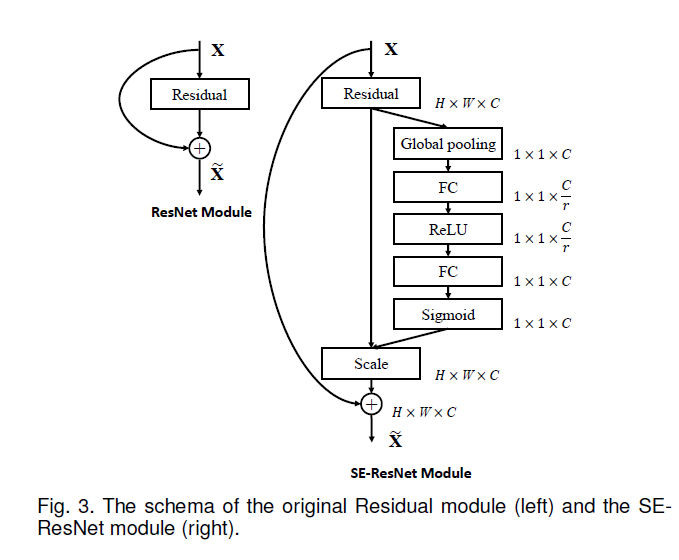
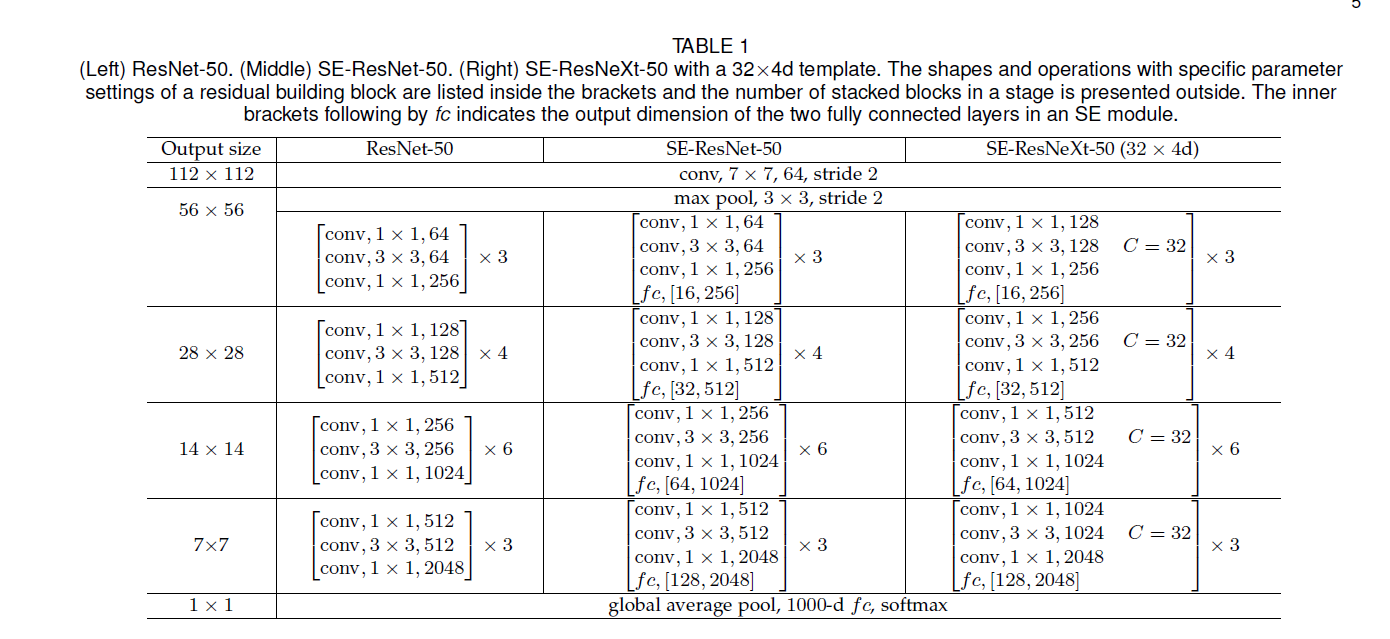

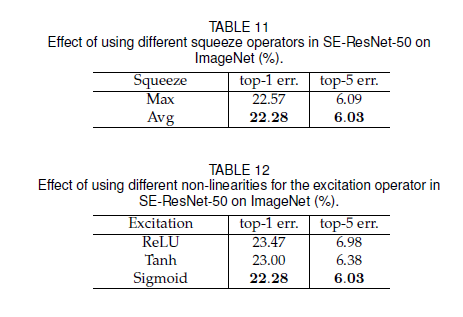
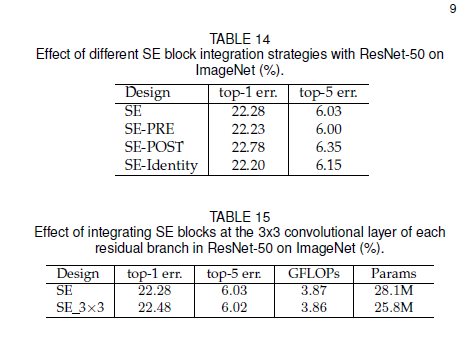
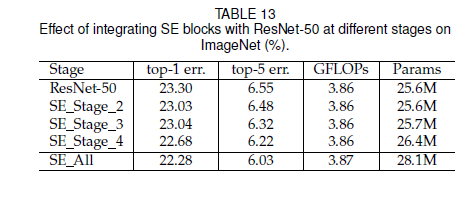
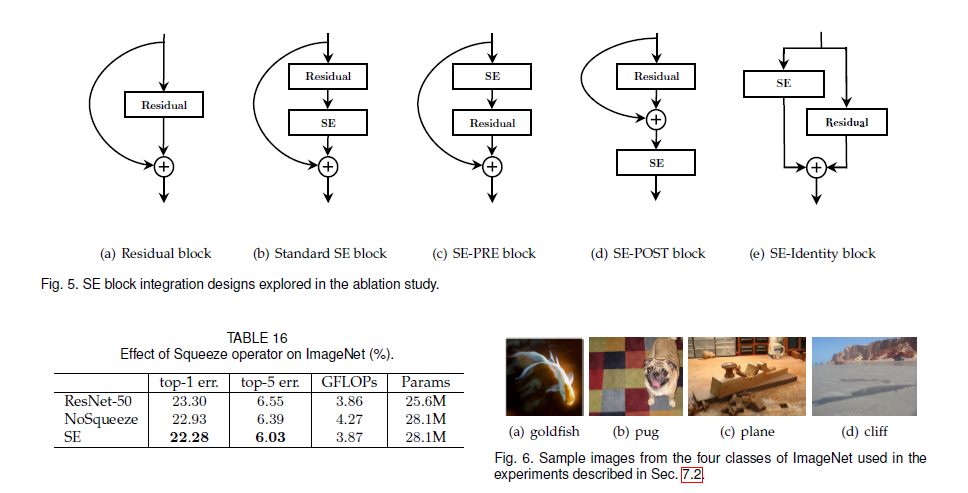
实验
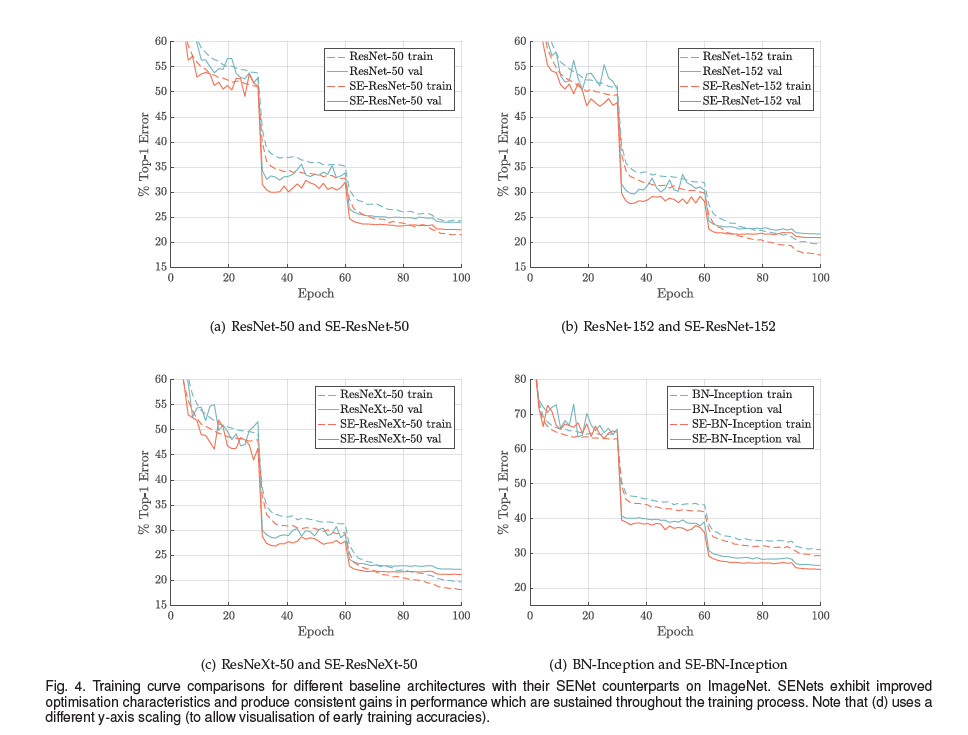
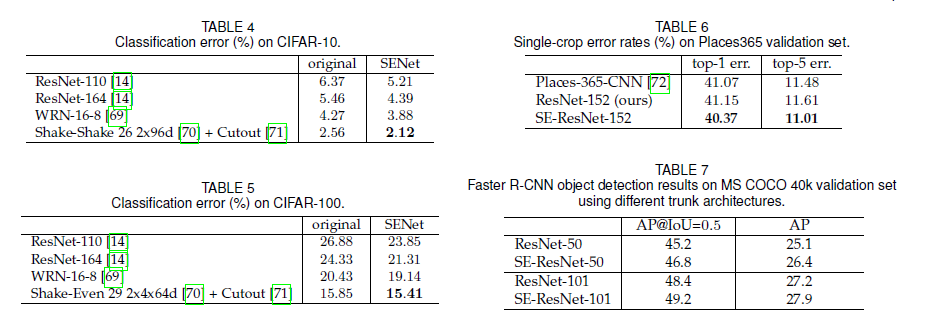
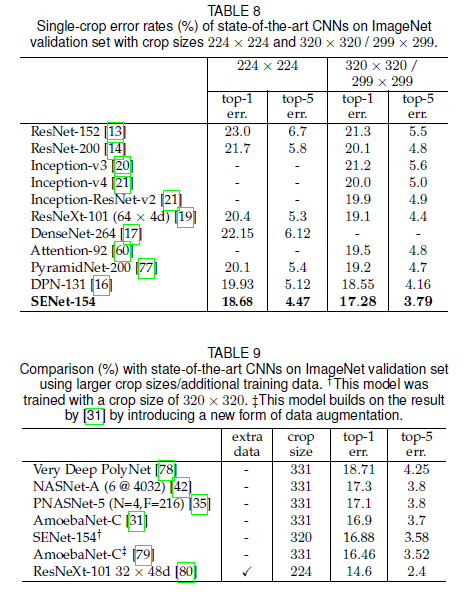

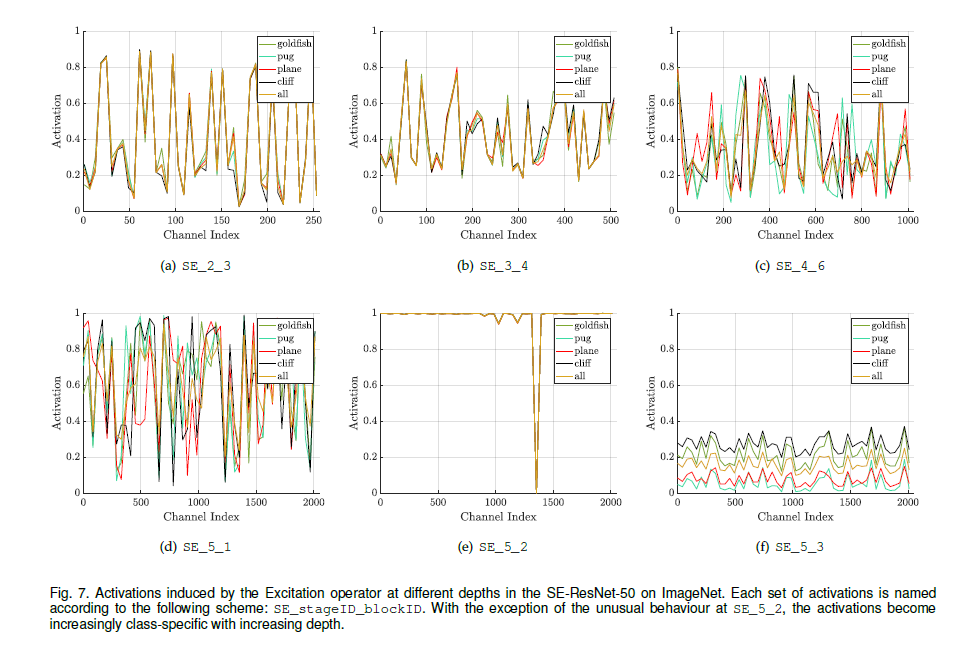
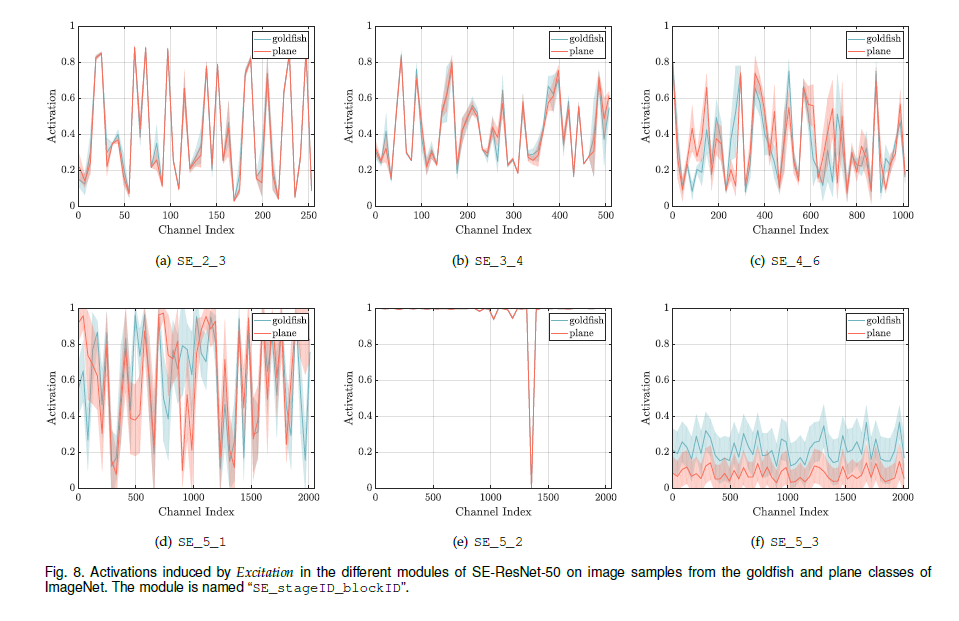
Reference
[1] A. Krizhevsky, I. Sutskever, and G. E. Hinton, “ImageNet classification with deep convolutional neural networks,” in NIPS, 2012.
[2] A. Toshev and C. Szegedy, “DeepPose: Human pose estimation via deep neural networks,” in CVPR, 2014.
[3] J. Long, E. Shelhamer, and T. Darrell, “Fully convolutional networks for semantic segmentation,” in CVPR, 2015.
[4] S. Ren, K. He, R. Girshick, and J. Sun, “Faster R-CNN: Towards real-time object detection with region proposal networks,” in
NIPS, 2015.
[5] C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Anguelov,D. Erhan, V. Vanhoucke, and A. Rabinovich, “Going deeper with
convolutions,” in CVPR, 2015.
[6] S. Ioffe and C. Szegedy, “Batch normalization: Accelerating deep network training by reducing internal covariate shift,” in ICML,
2015.
论文阅读笔记六十:Squeeze-and-Excitation Networks(SENet CVPR2017)的更多相关文章
- 论文阅读笔记六十四: Architectures for deep neural network based acoustic models defined over windowed speech waveforms(INTERSPEECH 2015)
论文原址:https://pdfs.semanticscholar.org/eeb7/c037e6685923c76cafc0a14c5e4b00bcf475.pdf 摘要 本文研究了利用深度神经网络 ...
- 论文阅读笔记六十六:Wide Activation for Efficient and Accurate Image Super-Resolution(CVPR2018)
论文原址:https://arxiv.org/abs/1808.08718 代码:https://github.com/JiahuiYu/wdsr_ntire2018 摘要 本文证明在SISR中在Re ...
- 论文阅读笔记六十五:Enhanced Deep Residual Networks for Single Image Super-Resolution(CVPR2017)
论文原址:https://arxiv.org/abs/1707.02921 代码: https://github.com/LimBee/NTIRE2017 摘要 以DNN进行超分辨的研究比较流行,其中 ...
- 论文阅读笔记六十二:RePr: Improved Training of Convolutional Filters(CVPR2019)
论文原址:https://arxiv.org/abs/1811.07275 摘要 一个训练好的网络模型由于其模型捕捉的特征中存在大量的重叠,可以在不过多的降低其性能的条件下进行压缩剪枝.一些skip/ ...
- [论文阅读笔记] Adversarial Learning on Heterogeneous Information Networks
[论文阅读笔记] Adversarial Learning on Heterogeneous Information Networks 本文结构 解决问题 主要贡献 算法原理 参考文献 (1) 解决问 ...
- 论文阅读笔记(十八)【ITIP2019】:Dynamic Graph Co-Matching for Unsupervised Video-Based Person Re-Identification
论文阅读笔记(十七)ICCV2017的扩刊(会议论文[传送门]) 改进部分: (1)惩罚函数:原本由两部分组成的惩罚函数,改为只包含 Sequence Cost 函数: (2)对重新权重改进: ① P ...
- [论文阅读笔记] node2vec Scalable Feature Learning for Networks
[论文阅读笔记] node2vec:Scalable Feature Learning for Networks 本文结构 解决问题 主要贡献 算法原理 参考文献 (1) 解决问题 由于DeepWal ...
- 论文阅读笔记六:FCN:Fully Convolutional Networks for Semantic Segmentation(CVPR2015)
今天来看一看一个比较经典的语义分割网络,那就是FCN,全称如题,原英文论文网址:https://people.eecs.berkeley.edu/~jonlong/long_shelhamer_fcn ...
- 论文阅读笔记(十二)【CVPR2018】:Exploit the Unknown Gradually: One-Shot Video-Based Person Re-Identification by Stepwise Learning
Introduction (1)Motivation: 大量标记数据成本过高,采用半监督的方式只标注一部分的行人,且采用单样本学习,每个行人只标注一个数据. (2)Method: 对没有标记的数据生成 ...
随机推荐
- vbs与其他语言进行交互编程(外存传参)
vbs没有自定义排序函数.无需自己造轮子,可以用其他语言来完成这个任务(在传递数据比较简单的情况下,例如只传递数组). 首先用5分钟写一个C++排序的代码.命名为“mysort.cpp”: #incl ...
- Sharding-JDBC:查询量大如何优化?
主人公小王入职了一家刚起步的创业公司,公司正在研发一款App.为了快速开发出能够投入市场进行宣传的版本,小王可是天天加班到很晚,忙了一段时间后终于把第一个版本赶出来了. 初期功能不多,表也不多,用的M ...
- Web端即时通讯基础知识补课:一文搞懂跨域的所有问题!
本文原作者: Wizey,作者博客:http://wenshixin.gitee.io,即时通讯网收录时有改动,感谢原作者的无私分享. 1.引言 典型的Web端即时通讯技术应用场景,主要有以下两种形式 ...
- GV900 Political Explanation
GV900 Political Explanation, 2017/201830 October, 2018Homework assignment 2Due Week 7 (13 November)W ...
- VMware 中安装kvm虚拟机
环境准备: 安装vmware时需要自定义安装-开启虚拟化技术 安装成功之后就可以继续进行了. 1 查看CPU是否支持KVM egrep 'vmx|svm' /proc/cpuinfo --colo ...
- 【08】Nginx:安全优化 / 信息隐藏 / 请求限制 / 白名单
写在前面的话 nginx 中主要的内容在前面的章节其实已经差不多了,接下都是一些小功能的实现以及关于 nginx 的优化问题.我们一起来探讨以下,如何把我们的 nginx 打造成为企业级应用. 安全优 ...
- 《 .NET并发编程实战》扩展阅读 - 元胞自动机 - 1 - 为什么要学元胞自动机
先发表生成URL以印在书里面.等书籍正式出版销售后会公开内容.
- mvc5 源码解析1:UrlRoutingModule
注册在C:\Windows\Microsoft.NET\Framework\v2.0.50727\CONFIG \webconfig中 在该module源码中 我们可以看出注册了application ...
- js、jquery、css属性及出错集合
*)注意使用jquery设置css的语法 css("propertyname","value");#单个时时逗号 css({"propertyname ...
- Winform中设置多条Y轴时新增的Y轴刻度不显示问题解决
场景 Winform中实现ZedGraph的多条Y轴(附源码下载): https://blog.csdn.net/BADAO_LIUMANG_QIZHI/article/details/1001322 ...