XGBoost 原理及应用
xgboost原理及应用--转
1.背景
关于xgboost的原理网络上的资源很少,大多数还停留在应用层面,本文通过学习陈天奇博士的PPT地址和xgboost导读和实战 地址,希望对xgboost原理进行深入理解。
2.xgboost vs gbdt
说到xgboost,不得不说gbdt。了解gbdt可以看我这篇文章 地址,gbdt无论在理论推导还是在应用场景实践都是相当完美的,但有一个问题:第n颗树训练时,需要用到第n-1颗树的(近似)残差。从这个角度来看,gbdt比较难以实现分布式(ps:虽然难,依然是可以的,换个角度思考就行),而xgboost从下面这个角度着手
注:红色箭头指向的l即为损失函数;红色方框为正则项,包括L1、L2;红色圆圈为常数项。
利用泰勒展开三项,做一个近似,我们可以很清晰地看到,最终的目标函数只依赖于每个数据点的在误差函数上的一阶导数和二阶导数。

3.原理
(1)定义树的复杂度
对于f的定义做一下细化,把树拆分成结构部分q和叶子权重部分w。下图是一个具体的例子。结构函数q把输入映射到叶子的索引号上面去,而w给定了每个索引号对应的叶子分数是什么。
定义这个复杂度包含了一棵树里面节点的个数,以及每个树叶子节点上面输出分数的L2模平方。当然这不是唯一的一种定义方式,不过这一定义方式学习出的树效果一般都比较不错。下图还给出了复杂度计算的一个例子。
注:方框部分在最终的模型公式中控制这部分的比重
在这种新的定义下,我们可以把目标函数进行如下改写,其中I被定义为每个叶子上面样本集合



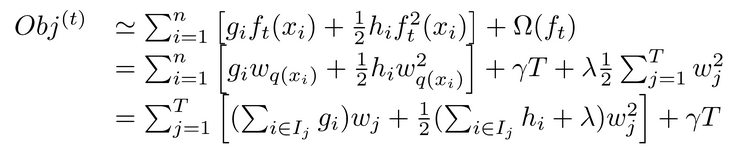
这一个目标包含了TT个相互独立的单变量二次函数。我们可以定义

最终公式可以化简为

通过对

然后把

(2)打分函数计算示例
Obj代表了当我们指定一个树的结构的时候,我们在目标上面最多减少多少。我们可以把它叫做结构分数(structure score)

(3)枚举不同树结构的贪心法
贪心法:每一次尝试去对已有的叶子加入一个分割

对于每次扩展,我们还是要枚举所有可能的分割方案,如何高效地枚举所有的分割呢?我假设我们要枚举所有x < a 这样的条件,对于某个特定的分割a我们要计算a左边和右边的导数和。

我们可以发现对于所有的a,我们只要做一遍从左到右的扫描就可以枚举出所有分割的梯度和GL和GR。然后用上面的公式计算每个分割方案的分数就可以了。
观察这个目标函数,大家会发现第二个值得注意的事情就是引入分割不一定会使得情况变好,因为我们有一个引入新叶子的惩罚项。优化这个目标对应了树的剪枝, 当引入的分割带来的增益小于一个阀值的时候,我们可以剪掉这个分割。大家可以发现,当我们正式地推导目标的时候,像计算分数和剪枝这样的策略都会自然地出现,而不再是一种因为heuristic(启发式)而进行的操作了。
4.自定义损失函数
在实际的业务场景下,我们往往需要自定义损失函数。这里给出一个官方的 链接 地址
5.Xgboost调参
由于Xgboost的参数过多,使用GridSearch特别费时。这里可以学习下这篇文章,教你如何一步一步去调参。地址
6.python、R对于xgboost的简单使用
任务:二分类,存在样本不均衡问题(scale_pos_weight可以一定程度上解读此问题)
【Python】
【R】


7.xgboost中比较重要的参数介绍
(1)objective [ default=reg:linear ] 定义学习任务及相应的学习目标,可选的目标函数如下:
- “reg:linear” –线性回归。
- “reg:logistic” –逻辑回归。
- “binary:logistic” –二分类的逻辑回归问题,输出为概率。
- “binary:logitraw” –二分类的逻辑回归问题,输出的结果为wTx。
- “count:poisson” –计数问题的poisson回归,输出结果为poisson分布。 在poisson回归中,max_delta_step的缺省值为0.7。(used to safeguard optimization)
- “multi:softmax” –让XGBoost采用softmax目标函数处理多分类问题,同时需要设置参数num_class(类别个数)
- “multi:softprob” –和softmax一样,但是输出的是ndata * nclass的向量,可以将该向量reshape成ndata行nclass列的矩阵。没行数据表示样本所属于每个类别的概率。
- “rank:pairwise” –set XGBoost to do ranking task by minimizing the pairwise loss
(2)’eval_metric’ The choices are listed below,评估指标:
- “rmse”: root mean square error
- “logloss”: negative log-likelihood
- “error”: Binary classification error rate. It is calculated as #(wrong cases)/#(all cases). For the predictions, the evaluation will regard the instances with prediction value larger than 0.5 as positive instances, and the others as negative instances.
- “merror”: Multiclass classification error rate. It is calculated as #(wrong cases)/#(all cases).
- “mlogloss”: Multiclass logloss
- “auc”: Area under the curve for ranking evaluation.
- “ndcg”:Normalized Discounted Cumulative Gain
- “map”:Mean average precision
- “ndcg@n”,”map@n”: n can be assigned as an integer to cut off the top positions in the lists for evaluation.
- “ndcg-“,”map-“,”ndcg@n-“,”map@n-“: In XGBoost, NDCG and MAP will evaluate the score of a list without any positive samples as 1. By adding “-” in the evaluation metric XGBoost will evaluate these score as 0 to be consistent under some conditions.
(3)lambda [default=0] L2 正则的惩罚系数
(4)alpha [default=0] L1 正则的惩罚系数
(5)lambda_bias 在偏置上的L2正则。缺省值为0(在L1上没有偏置项的正则,因为L1时偏置不重要)
(6)eta [default=0.3]
为了防止过拟合,更新过程中用到的收缩步长。在每次提升计算之后,算法会直接获得新特征的权重。 eta通过缩减特征的权重使提升计算过程更加保守。缺省值为0.3
取值范围为:[0,1]
(7)max_depth [default=6] 数的最大深度。缺省值为6 ,取值范围为:[1,∞]
(8)min_child_weight [default=1]
孩子节点中最小的样本权重和。如果一个叶子节点的样本权重和小于min_child_weight则拆分过程结束。在现行回归模型中,这个参数是指建立每个模型所需要的最小样本数。该成熟越大算法越conservative
取值范围为: [0,∞]
更多关于Xgboost学习地址
XGBoost 原理及应用的更多相关文章
- xgboost原理及应用
1.背景 关于xgboost的原理网络上的资源很少,大多数还停留在应用层面,本文通过学习陈天奇博士的PPT 地址和xgboost导读和实战 地址,希望对xgboost原理进行深入理解. 2.xgboo ...
- 一文读懂机器学习大杀器XGBoost原理
http://blog.itpub.net/31542119/viewspace-2199549/ XGBoost是boosting算法的其中一种.Boosting算法的思想是将许多弱分类器集成在一起 ...
- xgboost原理
出处http://blog.csdn.net/a819825294 1.序 距离上一次编辑将近10个月,幸得爱可可老师(微博)推荐,访问量陡增.最近毕业论文与xgboost相关,于是重新写一下这篇文章 ...
- xgboost原理及应用--转
1.背景 关于xgboost的原理网络上的资源很少,大多数还停留在应用层面,本文通过学习陈天奇博士的PPT地址和xgboost导读和实战 地址,希望对xgboost原理进行深入理解. 2.xgboos ...
- XGBoost原理简介
XGBoost是GBDT的改进和重要实现,主要在于: 提出稀疏感知(sparsity-aware)算法. 加权分位数快速近似学习算法. 缓存访问模式,数据压缩和分片上的实现上的改进. 加入了Shrin ...
- xgboost原理与实战
目录 xgboost原理 xgboost和gbdt的区别 xgboost安装 实战 xgboost原理 xgboost是一个提升模型,即训练多个分类器,然后将这些分类器串联起来,达到最终的预测效果.每 ...
- XGBoost原理学习总结
XGBoost原理学习总结 前言 XGBoost是一个上限提别高的机器学习算法,和Adaboost.GBDT等都属于Boosting类集成算法.虽然现在深度学习算法大行其道,但很多数据量往往没有太 ...
- XGBoost原理介绍
XGBoost原理介绍 1. 什么是XGBoost XGBoost是一个开源机器学习项目,实现了GBDT算法,进行了算法和工程上的许多改进,广泛应用在Kaggle竞赛及许多机器学习竞赛中. 说到XGB ...
- 【Python机器学习实战】决策树与集成学习(六)——集成学习(4)XGBoost原理篇
XGBoost是陈天奇等人开发的一个开源项目,前文提到XGBoost是GBDT的一种提升和变异形式,其本质上还是一个GBDT,但力争将GBDT的性能发挥到极致,因此这里的X指代的"Extre ...
随机推荐
- 解决ie6下png背景不能透明bug
/*第一种方法:通过滤镜 使用css解决的办法. 注意滤镜下的1像素透明gif的覆盖图片的路径是相对页面写的*/ /*注意:这个方法不适合处理img标签引入的png图片,代码太冗余了*/ .banne ...
- 强大的接口调试工具-Postman图文详解
前言 在前后端分离开发时,后端工作人员完成系统接口开发后,需要与前端人员对接,测试调试接口,验证接口的正确性可用性.而这要求前端开发进度和后端进度保持基本一致,任何一方的进度跟不上,都无法及时完成功能 ...
- JS回调函数怎么写的?
相信每个做前端的同学都用过太多太多的回调函数, 接下来就看看回调函数是怎么来的. 这玩意儿也没那么神秘,直接看代码: 声明函数的时候,把回调函数用作参数,并且在函数内调用它 function getD ...
- Comet OJ - Contest #15 题解
传送门 \(A\) 咕咕 const int N=1005; int a[N],n,T; int main(){ for(scanf("%d",&T);T;--T){ sc ...
- planAhead的启动时间较长
发现Xilinx planAhead的启动时间约需10秒钟.
- nginx之动静分离(nginx与php不在同一台服务器)
nginx实现动静分离(nginx与php不在同一个服务器) 使用wordpress-5.0.3-zh_CN.tar.gz做实验 Nginx服务器的配置: [root@app ~]# tar xf w ...
- 记一次vue+vuex+vue-router+axios+elementUI开发(三)
项目用到了状态管理工具 Vuex 中文文档:https://vuex.vuejs.org/zh/guide/ 大家都知道,vue中可用props将父组件的数据传递给子组件,但是有个问题,子组件一般不 ...
- module 'torch' has no attribute 'gesv'
新版torch不支持gesv,使用solve函数. Kt, _ = torch.gesv(P.mm(H.t()).t(), S) 改成 Kt, _ = torch.solve(P.mm(H.t()). ...
- mercurial branch name use integer as a name
问题:mercurial branch name use integer as a name 解决: 到安装目录下找到mercurial/scmutil.py文件(我的:/usr/local/Cell ...
- eclipse debug调试 class文件 Source not found.
1.情景展示 明明有class文件,为什么提示没有? 2.原因分析 这是eclipse与myeclipse的不同之处,myeclipse会自动加载运行时所需的的class文件,而eclipse则需 ...