day4-hdfs的核心工作原理\写数据流程 \读数据流程
namenode元数据管理要点
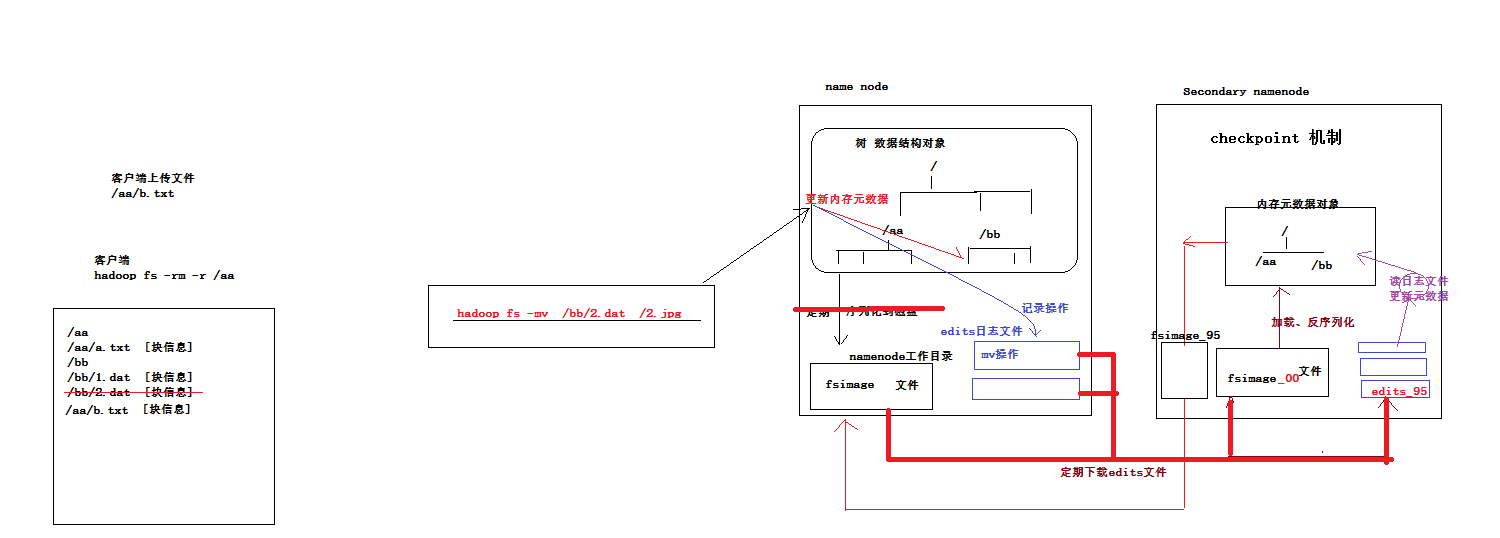
1、什么是元数据?
hdfs的目录结构及每一个文件的块信息(块的id,块的副本数量,块的存放位置<datanode>)
2、元数据由谁负责管理?
namenode
3、namenode把元数据记录在哪里?
namenode的实时的完整的元数据存储在内存中;
namenode还会在磁盘中(dfs.namenode.name.dir)存储内存元数据在某个时间点上的镜像文件;
namenode会把引起元数据变化的客户端操作记录在edits日志文件中;
|
secondarynamenode会定期从namenode上下载fsimage镜像和新生成的edits日志,然后加载fsimage镜像到内存中,然后顺序解析edits文件,对内存中的元数据对象进行修改(整合) 整合完成后,将内存元数据序列化成一个新的fsimage,并将这个fsimage镜像文件上传给namenode |
|
上述过程叫做:checkpoint操作 提示:secondary namenode每次做checkpoint操作时,都需要从namenode上下载上次的fsimage镜像文件吗? 第一次checkpoint需要下载,以后就不用下载了,因为自己的机器上就已经有了。 |
补充:secondary namenode启动位置的配置
|
默认值 |
<property> <name>dfs.namenode.secondary.http-address</name> <value>0.0.0.0:50090</value> </property> |
把默认值改成你想要的机器主机名即可
secondarynamenode保存元数据文件的目录配置:
|
默认值 |
<property> <name>dfs.namenode.checkpoint.dir</name> <value>file://${hadoop.tmp.dir}/dfs/namesecondary</value> </property> |
改成自己想要的路径即可:/root/dfs/namesecondary
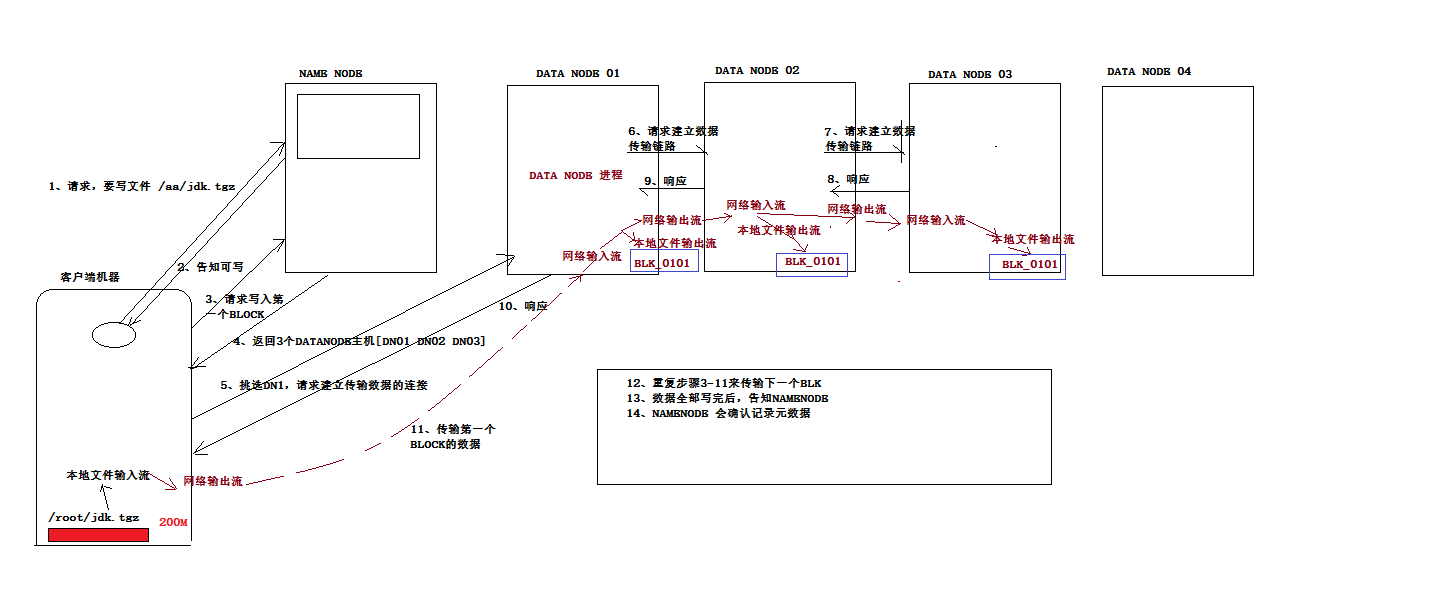
写数据流程
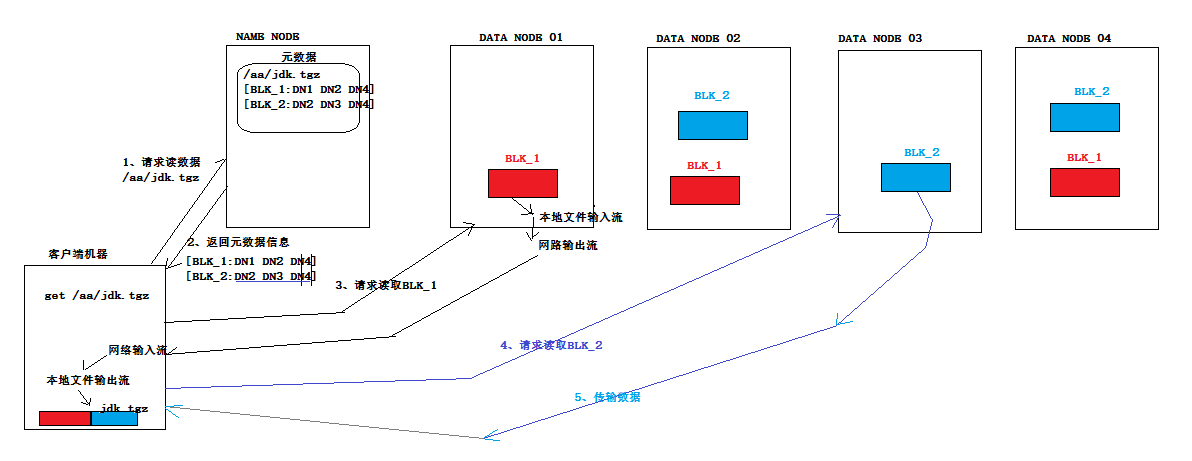
读数据流程
day4-hdfs的核心工作原理\写数据流程 \读数据流程的更多相关文章
- HDFS写数据和读数据流程
HDFS数据存储 HDFS client上传数据到HDFS时,首先,在本地缓存数据,当数据达到一个block大小时.请求NameNode分配一个block. NameNode会把block所在的Dat ...
- 第四次作业 描述HDFS体系结构、工作原理与流程
1.用自己的图,描述HDFS体系结构.工作原理与流程. 读数据的流程 2.伪分布式安装Hadoop.
- 《浏览器工作原理与实践》<05>渲染流程(上):HTML、CSS和JavaScript,是如何变成页面的?
在上一篇文章中我们介绍了导航相关的流程,那导航被提交后又会怎么样呢?就进入了渲染阶段.这个阶段很重要,了解其相关流程能让你“看透”页面是如何工作的,有了这些知识,你可以解决一系列相关的问题,比如能熟练 ...
- 《浏览器工作原理与实践》<06>渲染流程(下):HTML、CSS和JavaScript,是如何变成页面的?
在上篇文章中,我们介绍了渲染流水线中的 DOM 生成.样式计算和布局三个阶段,那今天我们接着讲解渲染流水线后面的阶段. 这里还是先简单回顾下上节前三个阶段的主要内容:在 HTML 页面内容被提交给渲染 ...
- 框架源码系列八:Spring源码学习之Spring核心工作原理(很重要)
目录:一.搞清楚ApplicationContext实例化Bean的过程二.搞清楚这个过程中涉及的核心类三.搞清楚IOC容器提供的扩展点有哪些,学会扩展四.学会IOC容器这里使用的设计模式五.搞清楚不 ...
- hdfs的datanode工作原理
datanode的作用: (1)提供真实文件数据的存储服务. (2)文件块(block):最基本的存储单位.对于文件内容而言,一个文件的长度大小是size,那么从文件的0偏移开始,按照固定的大小,顺序 ...
- 大数据 --> 分布式文件系统HDFS的工作原理
分布式文件系统HDFS的工作原理 Hadoop分布式文件系统(HDFS)是一种被设计成适合运行在通用硬件上的分布式文件系统.HDFS是一个高度容错性的系统,适合部署在廉价的机器上.它能提供高吞吐量的数 ...
- Hadoop中HDFS工作原理
转自:http://blog.csdn.net/sdlyjzh/article/details/28876385 Hadoop其实并不是一个产品,而是一些独立模块的组合.主要有分布式文件系统HDFS和 ...
- Hadoop分布式文件系统HDFS的工作原理
Hadoop分布式文件系统(HDFS)是一种被设计成适合运行在通用硬件上的分布式文件系统.HDFS是一个高度容错性的系统,适合部署在廉价的机器上.它能提供高吞吐量的数据访问,非常适合大规模数据集上的应 ...
随机推荐
- linux centos 下php的mcrypt扩展
去http://www.sourceforge.net下载Libmcrypt,mhash,mcrypt安装包 libmcrypt(libmcrypt-2.5.8.tar.gz ):mcrypt(mcr ...
- PHP会话控制考察点
为什么要使用会话控制技术 HTTP协议是无状态的,也就是说HTTP没有一个内建的机制来维护两个事务之间的状态.当一个用户完成一个请求发起第二个请求的时候,服务器无法知道这次请求是来自于上一次的客户.而 ...
- iOS Cell异步图片加载优化,缓存机制详解
最近研究了一下UITbleView中异步加载网络图片的问题,iOS应用经常会看到这种界面.一个tableView上显示一些标题.详情等内容,在加上一张图片.这里说一下这种思路. 为了防止图片多次下载, ...
- ALTER GROUP - 修改一个用户组
SYNOPSIS ALTER GROUP groupname ADD USER username [, ... ] ALTER GROUP groupname DROP USER username [ ...
- java组件不存在解决方案:右侧Maven Projects展开后左上角第一个刷新按钮 刷新后就会从新加载所有java的依赖项了
java组件不存在解决方案:右侧Maven Projects展开后左上角第一个刷新按钮 刷新后就会从新加载所有java的依赖项了 软件:idea 问题产生:其他同事进行开发,引入新java组件后提交 ...
- Python框架Django的入门
本篇文章主要给大家介绍Django的入门知识:
- SQLSTATE=2300
在powerdesigner将表的结构运用于数据库的时候报的错. 目标: 在Hibernate中使用多表级联的插入操作. 解决办法: 将navicat中的mysql数据库表删除, 手动创建 原因: p ...
- 【Hadoop】一、分布式数据库HBase简介
1.分布式数据库特点 说到数据库,我们最熟悉的是类似于mysql这样的关系型数据库,称为RDBMS.关系型数据库作为一种数据存储和数据检索的关键技术,它支持SQL语言的结构化查询,但是它天生不是为 ...
- 原生javascript实现call、apply和bind的方法
var context = {id: 12}; function fun (name, age) { console.log(this.id, name, age) } bind bind() 方法会 ...
- 零基础入门学习Python(12)--列表:一个打了激素的数组(3)
前言 这节课我们继续谈一下Python列表一些知识 知识点 Python常用操作符 比较操作符 >>> list1 = [123] >>> list2 = [234 ...