day4-hdfs的核心工作原理\写数据流程 \读数据流程
namenode元数据管理要点
1、什么是元数据?
hdfs的目录结构及每一个文件的块信息(块的id,块的副本数量,块的存放位置<datanode>)
2、元数据由谁负责管理?
namenode
3、namenode把元数据记录在哪里?
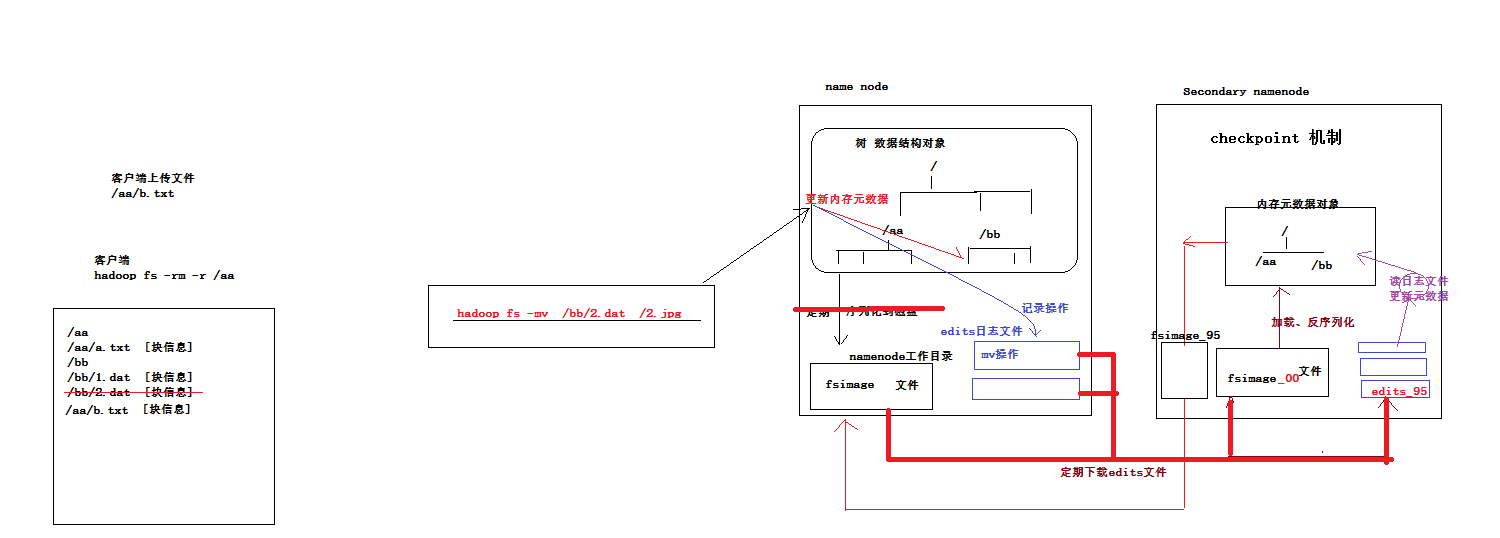
namenode的实时的完整的元数据存储在内存中;
namenode还会在磁盘中(dfs.namenode.name.dir)存储内存元数据在某个时间点上的镜像文件;
namenode会把引起元数据变化的客户端操作记录在edits日志文件中;
|
secondarynamenode会定期从namenode上下载fsimage镜像和新生成的edits日志,然后加载fsimage镜像到内存中,然后顺序解析edits文件,对内存中的元数据对象进行修改(整合) 整合完成后,将内存元数据序列化成一个新的fsimage,并将这个fsimage镜像文件上传给namenode |
|
上述过程叫做:checkpoint操作 提示:secondary namenode每次做checkpoint操作时,都需要从namenode上下载上次的fsimage镜像文件吗? 第一次checkpoint需要下载,以后就不用下载了,因为自己的机器上就已经有了。 |
补充:secondary namenode启动位置的配置
|
默认值 |
<property> <name>dfs.namenode.secondary.http-address</name> <value>0.0.0.0:50090</value> </property> |
把默认值改成你想要的机器主机名即可
secondarynamenode保存元数据文件的目录配置:
|
默认值 |
<property> <name>dfs.namenode.checkpoint.dir</name> <value>file://${hadoop.tmp.dir}/dfs/namesecondary</value> </property> |
改成自己想要的路径即可:/root/dfs/namesecondary
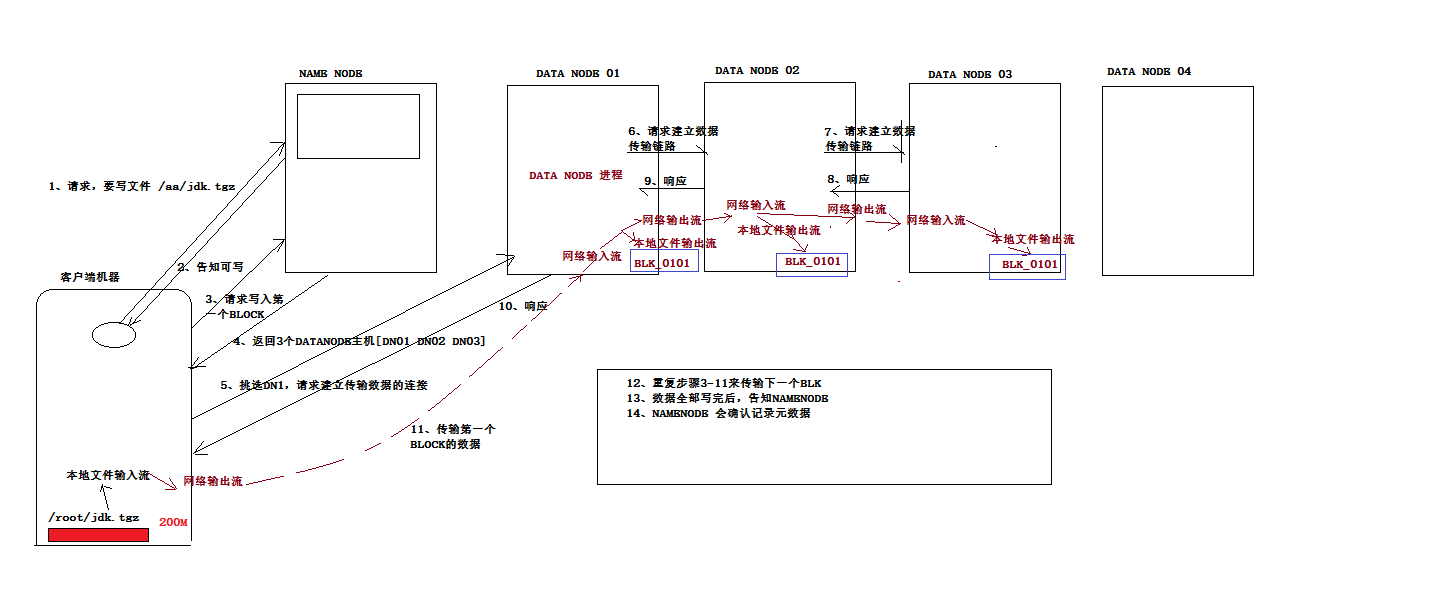
写数据流程
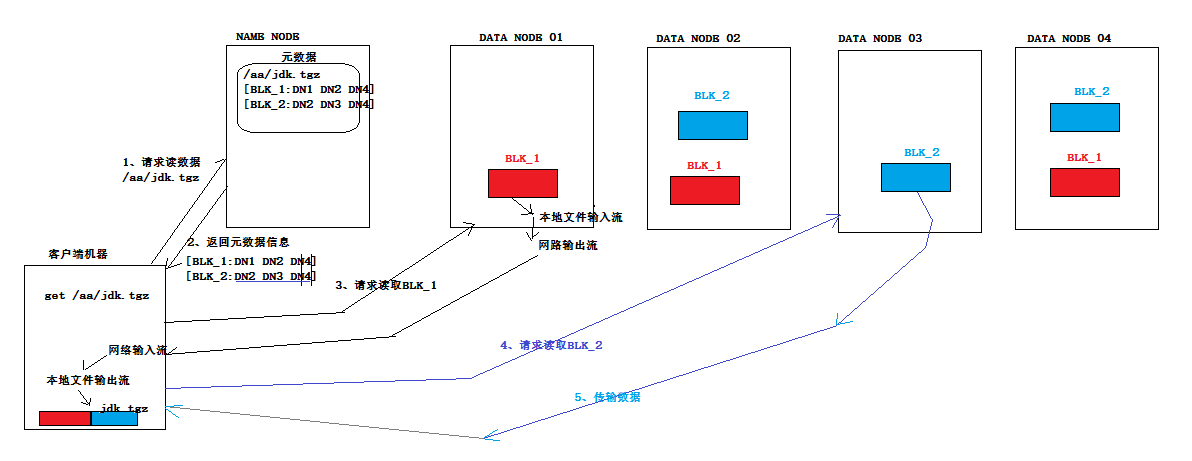
读数据流程
day4-hdfs的核心工作原理\写数据流程 \读数据流程的更多相关文章
- HDFS写数据和读数据流程
HDFS数据存储 HDFS client上传数据到HDFS时,首先,在本地缓存数据,当数据达到一个block大小时.请求NameNode分配一个block. NameNode会把block所在的Dat ...
- 第四次作业 描述HDFS体系结构、工作原理与流程
1.用自己的图,描述HDFS体系结构.工作原理与流程. 读数据的流程 2.伪分布式安装Hadoop.
- 《浏览器工作原理与实践》<05>渲染流程(上):HTML、CSS和JavaScript,是如何变成页面的?
在上一篇文章中我们介绍了导航相关的流程,那导航被提交后又会怎么样呢?就进入了渲染阶段.这个阶段很重要,了解其相关流程能让你“看透”页面是如何工作的,有了这些知识,你可以解决一系列相关的问题,比如能熟练 ...
- 《浏览器工作原理与实践》<06>渲染流程(下):HTML、CSS和JavaScript,是如何变成页面的?
在上篇文章中,我们介绍了渲染流水线中的 DOM 生成.样式计算和布局三个阶段,那今天我们接着讲解渲染流水线后面的阶段. 这里还是先简单回顾下上节前三个阶段的主要内容:在 HTML 页面内容被提交给渲染 ...
- 框架源码系列八:Spring源码学习之Spring核心工作原理(很重要)
目录:一.搞清楚ApplicationContext实例化Bean的过程二.搞清楚这个过程中涉及的核心类三.搞清楚IOC容器提供的扩展点有哪些,学会扩展四.学会IOC容器这里使用的设计模式五.搞清楚不 ...
- hdfs的datanode工作原理
datanode的作用: (1)提供真实文件数据的存储服务. (2)文件块(block):最基本的存储单位.对于文件内容而言,一个文件的长度大小是size,那么从文件的0偏移开始,按照固定的大小,顺序 ...
- 大数据 --> 分布式文件系统HDFS的工作原理
分布式文件系统HDFS的工作原理 Hadoop分布式文件系统(HDFS)是一种被设计成适合运行在通用硬件上的分布式文件系统.HDFS是一个高度容错性的系统,适合部署在廉价的机器上.它能提供高吞吐量的数 ...
- Hadoop中HDFS工作原理
转自:http://blog.csdn.net/sdlyjzh/article/details/28876385 Hadoop其实并不是一个产品,而是一些独立模块的组合.主要有分布式文件系统HDFS和 ...
- Hadoop分布式文件系统HDFS的工作原理
Hadoop分布式文件系统(HDFS)是一种被设计成适合运行在通用硬件上的分布式文件系统.HDFS是一个高度容错性的系统,适合部署在廉价的机器上.它能提供高吞吐量的数据访问,非常适合大规模数据集上的应 ...
随机推荐
- H1B工作签证·绿卡:美国留学的两个关键步骤
月20日在留美学生家长群聚会上的发言稿一.H1B签证系美国最主要的工作签证类别,发放给美国公司雇佣的外国籍有专业技能的员工,属于非移民签证的一种.持有H1B签证者可以在美国工作三年,然后可以再延长三年 ...
- How to Configure YUM to Install Packages From Installation ISO (RHEL)
1. Mount RHEL Installation ISO mkdir /media/dvd mount /dev/cdrom /media/dvd 2. Get Media ID with the ...
- 基于jQuery的用户界面插件集合---EasyUI
easyui是一种基于jQuery的用户界面插件集合.为创建现代化,互动,JavaScript应用程序,提供必要的功能.使用easyui你不需要写很多代码,你只需要通过编写一些简单HTML标记,就可以 ...
- 阿里云 Django部署参考
Linux下安装Python3和django并配置mysql作为django默认服务器 CentOS7.3安装Python3.6 yum except KeyboardInterrupt, e: 错误 ...
- jQuery-图片的放大镜显示效果方法封装
(function($){ $.fn.jqueryzoom = function(options){ var settings = { xzoom: 200, //zoomed width defau ...
- vue全选与反选以及通过使用如何filter删除数据
在vue学习经常遇到的一些基本问题,下面是购物车里面的部分功能,分享给初学者,直接上源码: <!DOCTYPE html><html> <head> <met ...
- C++ 之 string
C++ 的 string 类封装了很多对字符串的常用操作. string 类是模板类 basic_string类,以 char作为其元素类型的类. string 以单字节作为一个字符,如果处理多字符集 ...
- BZOJ3545 Peaks 离线处理+线段树合并
题意: 在Bytemountains有N座山峰,每座山峰有他的高度h_i.有些山峰之间有双向道路相连,共M条路径,每条路径有一个困难值,这个值越大表示越难走,现在有Q组询问,每组询问询问从点v开始只经 ...
- Linux基础学习二
新建分区:fdisk /dev/sda(a代表第一块硬盘) 建完后w保存 更新分区表:partprobe mkfs.ext4 /dev/sdb{1..3} : 格式 ...
- 零基础入门学习Python(33)--异常处理:你不可能总是对的2
知识点 异常处理 捕捉异常可以使用try/except语句. try/except语句用来检测try语句块中的错误,从而让except语句捕获异常信息并处理. 如果你不想在异常发生时结束你的程序,只需 ...