Hash环/一致性Hash原理
当前,Memcached、Redis这类分布式kv缓存已经非常普遍。从本篇开始,本系列将分析分布式缓存相关的原理、使用策略和最佳实践。
我们知道Memcached的分布式其实是一种“伪分布式”,也就是它的服务器结点之间其实是相互无关联的,之间没有网络拓扑关系,由客户端来决定一个key是存放到哪台机器。
具体来讲,假设我有多台memcached服务器,编号分别为m0,m1,m2,…。对于一个key,由客户端来决定存放到哪台机器,那最简单的hash公式就是 key % N,其中N是机器的总数。
但这有个问题,一旦机器数变少,或者增加机器,N发生变化,那之前存放的数据就全部无效了。因为你按照新的N值取模计算出的机器编号,和当时按旧的N值取模算出的机器编号肯定是不等的,也就意味着绝大部分缓存会失效。
这个问题的解决办法就是用1种特别的Hash函数,尽可能使得,增加机器/减少机器时,缓存失效的数目降到最低,这就是Hash环,或者叫一致性Hash。
Hash环
上面说的Hash函数,只经过了1次hash,即把key hash到对应的机器编号。
而Hash环有2次Hash:
(1)把所有机器编号hash到这个环上
(2)把key也hash到这个环上。然后在这个环上进行匹配,看这个key和哪台机器匹配。
具体来讲,如下:
假定有这样一个Hash函数,其值空间为(0到2的32次方-1) ,也就是说,其hash值是个32位无整型数字 ,这些数字组成一个环。
然后,先对机器进行hash(比如根据机器的ip),算出每台机器在这个环上的位置; 再对key进行hash,算出该key在环上的位置,然后从这个位置往前走,遇到的第一台机器就是该key对应的机器,就把该(key, value) 存储到该机器上。
如下图所示:
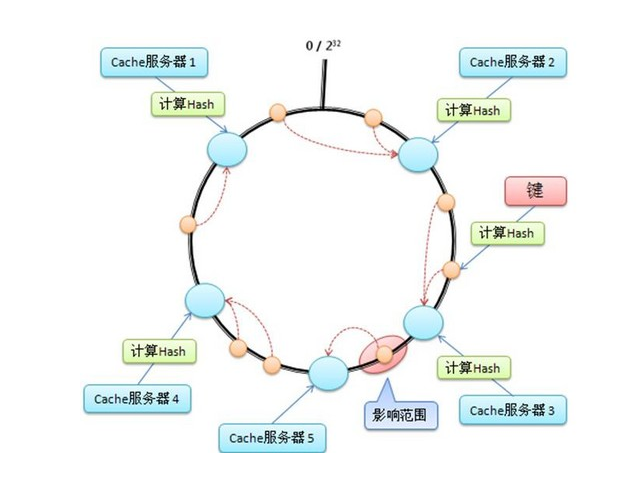
首先计算出每台Cache服务器在环上的位置(图中的大圆圈);然后每来一个(key, value),计算出在环上的位置(图中的小圆圈),然后顺时针走,遇到的第1个机器,就是其要存储的机器。
这里的关键点是:当你增加/减少机器时,其他机器在环上的位置并不会发生改变。这样只有增加的那台机器、或者减少的那台机器附近的数据会失效,其他机器上的数据都还是有效的。
数据倾斜问题
当你机器不多的时候,很可能出现几台机器在环上面贴的很近,不是在环上均匀分布。这将会导致大部分数据,都会集中在某1台机器上。
为了解决这个问题,可以引入“虚拟机器”的概念,也就是说:1台机器,我在环上面计算出多个位置。怎么弄呢? 假设用机器的ip来hash,我可以在ip后面加上几个编号, ip_1, ip_2, ip_3, … 把1台物理机器生个多个虚拟机器的编号。
数据首先映射到“虚拟机器上”,再从“虚拟机器”映射到物理机器上。因为虚拟机器可以很多,在环上面均匀分布,从而保证数据均匀分布到物理机器上面。
ZK的引入
上面我们提到了服务器的机器增加、减少,问题是客户端怎么知道呢?
一种笨办法就是手动的,当服务器机器增加、减少时候,重新配置客户端,重启客户端。
另外一种,就是引入ZK,服务器的节点列表注册到ZK上面,客户端监听ZK。发现结点数发生变化,自动更新自己的配置。
当然,不用ZK,用一个其他的中心结点,只要能实现这种更改的通知,也是可以的。
Hash环/一致性Hash原理的更多相关文章
- 分布式缓存--系列1 -- Hash环/一致性Hash原理
当前,Memcached.Redis这类分布式kv缓存已经非常普遍.从本篇开始,本系列将分析分布式缓存相关的原理.使用策略和最佳实践. 我们知道Memcached的分布式其实是一种“伪分布式”,也就是 ...
- 分布式缓存 - hash环/一致性hash
一 引言 当前memcached,redis这类分布式kv缓存已经非常普遍.我们知道memcached的分布式其实是一种"伪分布式",也就是它的服务器节点之间其实是无关联的,之间没 ...
- hash·余数hash和一致性hash
网站的伸缩性架构中,分布式的设计是现在的基本应用. 在memcached的分布式架构中,key-value缓存的命中通常采用分布式的算法 一.余数Hash 简单的路由算法可以使用余数Hash: ...
- 一致性Hash(Consistent Hashing)原理剖析
引入 在业务开发中,我们常把数据持久化到数据库中.如果需要读取这些数据,除了直接从数据库中读取外,为了减轻数据库的访问压力以及提高访问速度,我们更多地引入缓存来对数据进行存取.读取数据的过程一般为: ...
- 一致性Hash算法的原理与实现(分布式映射算法)
一致性Hash算法解决的问题: 解决分布式系统中的负载均衡问题 背景问题:有N台服务器提供缓存服务,需要对服务器进行负载均衡,将请求平均发到每台服务器上,每台服务器负载1/N的服务 硬Hash映射:将 ...
- 7.redis 集群模式的工作原理能说一下么?在集群模式下,redis 的 key 是如何寻址的?分布式寻址都有哪些算法?了解一致性 hash 算法吗?
作者:中华石杉 面试题 redis 集群模式的工作原理能说一下么?在集群模式下,redis 的 key 是如何寻址的?分布式寻址都有哪些算法?了解一致性 hash 算法吗? 面试官心理分析 在前几年, ...
- 一致性 hash 环
一致性 hash 环 最近做项目 做了一个分发器 ,需要 根据请求携带的参数 把请求分发到 不同的服务器上面,最终我选择使用 一致性hash 环 来实现 ,本篇 就主要讲解一下 一致性hash环 它的 ...
- 给面试官讲明白:一致性Hash的原理和实践
"一致性hash的设计初衷是解决分布式缓存问题,它不仅能起到hash作用,还可以在服务器宕机时,尽量少地迁移数据.因此被广泛用于状态服务的路由功能" 01分布式系统的路由算法 假设 ...
- 一致性hash在分布式系统中的应用
场景 如果要设计一套KV存储的系统,用户PUT一个key和value,存储到系统中,并且提供用户根据key来GET对应的value.要求随着用户规模变大,系统是可以水平扩展的,主要要解决以下几个问题. ...
随机推荐
- Principle of least astonishment
Principle of least astonishment - Wikipedia https://en.wikipedia.org/wiki/Principle_of_least_astonis ...
- [TJOI2017] 不勤劳的图书管理员
题目描述 加里敦大学有个帝国图书馆,小豆是图书馆阅览室的一个书籍管理员.他的任务是把书排成有序的,所以无序的书让他产生厌烦,两本乱序的书会让小豆产生这两本书页数的和的厌烦度.现在有n本被打乱顺序的书, ...
- kaminari分页插件样式
修改国际化文件,zh-cn views: pagination: first: "首页" last: "尾页" previous: "上一页" ...
- 代码块、继承、this、super、final(java基础知识八)
1.代码块的概述和分类 * A:代码块概述 * 在Java中,使用{}括起来的代码被称为代码块.* B:代码块分类 * 根据其位置和声明的不同,可以分为局部代码块,构造代码块,静态代码块,同步代码块( ...
- MYSQL进阶学习笔记九:MySQL事务的应用!(视频序号:进阶_21-22)
知识点十:MySQL 事务的应用 (21-22) 为什么要引入事务: 为什么要引入事务这个技术呢?现在的很多软件都是多用户,多程序,多线程的.对同一表可能同时有很多人在用,为保持数据的一致性,所以提出 ...
- hdu2063 二分图(基础题)
这个题目适合刚刚接触二分图的同学做哦: 给一个题目链接 点击打开链接. 题目大意,有K个男女匹配方式, 输入数据的第一行是三个整数K , M , N,分别表示可能的组合数目,女生的人数,男生的人数.0 ...
- LA-5052 (暴力)
题意: 给[1,n]的两个排列,统计有多少个二元组(a,b)满足a是A的连续子序列,b是B的连续子序列,a,b中包含的数相同; 思路: 由于是连续的序列,且长度相同,可以枚举一个串的子串,找出这个子串 ...
- liunx下的权限详解
用户组 在linux中的每个用户必须属于一个组,不能独立于组外.在linux中每个文件有所有者.所在组.其它组的概念 - 所有者 - 所在组 - 其它组 - 改变用户所在的组 所有者 一般为文件的创建 ...
- 「LuoguP4752」牧 Divided Prime(判质数
Description 给定一个数字 A,这个 A 由 a1,a2,⋯,aN相乘得到. 给定一个数字 B,这个 B 由 b1,b2,⋯,bM相乘得到. 如果 A/B 是一个质数,请输出YES,否则输出 ...
- 使用strtok_s函数从一个字符串中分离出单词
下面的代码从含有多个结束符的字符串中分离出单词来,需要对strtok_s有清楚的认识.这段代码是我在写一个处理文件中单词个数时用来分离读取到的字符串中的单词时写的,亲测可用~ 1 2 3 4 5 6 ...