Hash环/一致性Hash原理
当前,Memcached、Redis这类分布式kv缓存已经非常普遍。从本篇开始,本系列将分析分布式缓存相关的原理、使用策略和最佳实践。
我们知道Memcached的分布式其实是一种“伪分布式”,也就是它的服务器结点之间其实是相互无关联的,之间没有网络拓扑关系,由客户端来决定一个key是存放到哪台机器。
具体来讲,假设我有多台memcached服务器,编号分别为m0,m1,m2,…。对于一个key,由客户端来决定存放到哪台机器,那最简单的hash公式就是 key % N,其中N是机器的总数。
但这有个问题,一旦机器数变少,或者增加机器,N发生变化,那之前存放的数据就全部无效了。因为你按照新的N值取模计算出的机器编号,和当时按旧的N值取模算出的机器编号肯定是不等的,也就意味着绝大部分缓存会失效。
这个问题的解决办法就是用1种特别的Hash函数,尽可能使得,增加机器/减少机器时,缓存失效的数目降到最低,这就是Hash环,或者叫一致性Hash。
Hash环
上面说的Hash函数,只经过了1次hash,即把key hash到对应的机器编号。
而Hash环有2次Hash:
(1)把所有机器编号hash到这个环上
(2)把key也hash到这个环上。然后在这个环上进行匹配,看这个key和哪台机器匹配。
具体来讲,如下:
假定有这样一个Hash函数,其值空间为(0到2的32次方-1) ,也就是说,其hash值是个32位无整型数字 ,这些数字组成一个环。
然后,先对机器进行hash(比如根据机器的ip),算出每台机器在这个环上的位置; 再对key进行hash,算出该key在环上的位置,然后从这个位置往前走,遇到的第一台机器就是该key对应的机器,就把该(key, value) 存储到该机器上。
如下图所示:
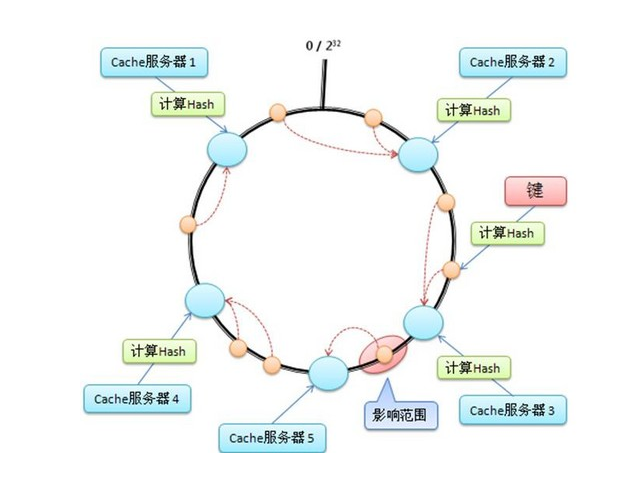
首先计算出每台Cache服务器在环上的位置(图中的大圆圈);然后每来一个(key, value),计算出在环上的位置(图中的小圆圈),然后顺时针走,遇到的第1个机器,就是其要存储的机器。
这里的关键点是:当你增加/减少机器时,其他机器在环上的位置并不会发生改变。这样只有增加的那台机器、或者减少的那台机器附近的数据会失效,其他机器上的数据都还是有效的。
数据倾斜问题
当你机器不多的时候,很可能出现几台机器在环上面贴的很近,不是在环上均匀分布。这将会导致大部分数据,都会集中在某1台机器上。
为了解决这个问题,可以引入“虚拟机器”的概念,也就是说:1台机器,我在环上面计算出多个位置。怎么弄呢? 假设用机器的ip来hash,我可以在ip后面加上几个编号, ip_1, ip_2, ip_3, … 把1台物理机器生个多个虚拟机器的编号。
数据首先映射到“虚拟机器上”,再从“虚拟机器”映射到物理机器上。因为虚拟机器可以很多,在环上面均匀分布,从而保证数据均匀分布到物理机器上面。
ZK的引入
上面我们提到了服务器的机器增加、减少,问题是客户端怎么知道呢?
一种笨办法就是手动的,当服务器机器增加、减少时候,重新配置客户端,重启客户端。
另外一种,就是引入ZK,服务器的节点列表注册到ZK上面,客户端监听ZK。发现结点数发生变化,自动更新自己的配置。
当然,不用ZK,用一个其他的中心结点,只要能实现这种更改的通知,也是可以的。
Hash环/一致性Hash原理的更多相关文章
- 分布式缓存--系列1 -- Hash环/一致性Hash原理
当前,Memcached.Redis这类分布式kv缓存已经非常普遍.从本篇开始,本系列将分析分布式缓存相关的原理.使用策略和最佳实践. 我们知道Memcached的分布式其实是一种“伪分布式”,也就是 ...
- 分布式缓存 - hash环/一致性hash
一 引言 当前memcached,redis这类分布式kv缓存已经非常普遍.我们知道memcached的分布式其实是一种"伪分布式",也就是它的服务器节点之间其实是无关联的,之间没 ...
- hash·余数hash和一致性hash
网站的伸缩性架构中,分布式的设计是现在的基本应用. 在memcached的分布式架构中,key-value缓存的命中通常采用分布式的算法 一.余数Hash 简单的路由算法可以使用余数Hash: ...
- 一致性Hash(Consistent Hashing)原理剖析
引入 在业务开发中,我们常把数据持久化到数据库中.如果需要读取这些数据,除了直接从数据库中读取外,为了减轻数据库的访问压力以及提高访问速度,我们更多地引入缓存来对数据进行存取.读取数据的过程一般为: ...
- 一致性Hash算法的原理与实现(分布式映射算法)
一致性Hash算法解决的问题: 解决分布式系统中的负载均衡问题 背景问题:有N台服务器提供缓存服务,需要对服务器进行负载均衡,将请求平均发到每台服务器上,每台服务器负载1/N的服务 硬Hash映射:将 ...
- 7.redis 集群模式的工作原理能说一下么?在集群模式下,redis 的 key 是如何寻址的?分布式寻址都有哪些算法?了解一致性 hash 算法吗?
作者:中华石杉 面试题 redis 集群模式的工作原理能说一下么?在集群模式下,redis 的 key 是如何寻址的?分布式寻址都有哪些算法?了解一致性 hash 算法吗? 面试官心理分析 在前几年, ...
- 一致性 hash 环
一致性 hash 环 最近做项目 做了一个分发器 ,需要 根据请求携带的参数 把请求分发到 不同的服务器上面,最终我选择使用 一致性hash 环 来实现 ,本篇 就主要讲解一下 一致性hash环 它的 ...
- 给面试官讲明白:一致性Hash的原理和实践
"一致性hash的设计初衷是解决分布式缓存问题,它不仅能起到hash作用,还可以在服务器宕机时,尽量少地迁移数据.因此被广泛用于状态服务的路由功能" 01分布式系统的路由算法 假设 ...
- 一致性hash在分布式系统中的应用
场景 如果要设计一套KV存储的系统,用户PUT一个key和value,存储到系统中,并且提供用户根据key来GET对应的value.要求随着用户规模变大,系统是可以水平扩展的,主要要解决以下几个问题. ...
随机推荐
- hadoop 集群搭建 配置 spark yarn 对效率的提升永无止境
[手动验证:任意2个节点间是否实现 双向 ssh免密登录] 弄懂通信原理和集群的容错性 任意2个节点间实现双向 ssh免密登录,默认在~目录下 [实现上步后,在其中任一节点安装\配置hadoop后,可 ...
- GitExtensions 官方手册(英文)
在线版本(最新版):https://git-extensions-documentation.readthedocs.io/en/latest/ PDF版本(版本号 2.48):http://pan. ...
- idea 破解注册方法总结
注册码(无期限) JetbrainsCrack-2.6.2.jar适用于ideaIU-2017.2.之前版本,若版本较新适用 JetbrainsCrack-2.6.3_proc.jar. 其中Jetb ...
- div 下 的img水平居中
设置text-align:center; 这个div必须要设置宽度: 如:{text-align:center; width:100%;}
- NSDictionary字典创建,获取,遍历,可变字典的删除 - iOS
字典是以键值对的形式来存储数据 key value 1 NSDictionary 字典 1.1 创建字典,不可变的 NSDictionary * dic = [NSDictionary diction ...
- 四叉树 bnuoj
点击打开题目链接 建树+广搜一棵树:最下面有更短代码(很巧妙). #include<iostream> #include<stdio.h> #include<queue& ...
- [Java] static, final
1.静态成员 静态成员独立于类的对象,先于对象的存在而存在.无论创建了类的多少个对象,静态成员都只有一个实例空间.一个静态变量被同一个类的所有对象共享.当改变了其中一个对象的静态变量时,其余对象的静态 ...
- MyBatis学习 之 七、mybatis各种数据库的批量修改
MyBatis的update元素的用法与insert元素基本相同,因此本篇不打算重复了.本篇仅记录批量update操作的sql语句,懂得SQL语句,那么MyBatis部分的操作就简单了. 注意:下 ...
- Educational Codeforces Round 23
A题 分析:注意两个点之间的倍数差,若为偶数则为YES,否则为NO #include "iostream" #include "cstdio" #include ...
- Oracle 安装报错 [INS-06101] IP address of localhost could not be determined 解决方法输入日志标题
安装Oracle 11gR2,报错:[INS-06101] IP address of localhost could not be determined 出现这种错误是因为主机名和/etc/host ...