selenium 之定位方法
1 id 定位 driver.find_element_by_id()
HTML 规定id 属性在HTML 文档中必须是唯一的。这类似于公民的身份证号,具有很强的唯一性
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('http://ui.imdsx.cn/uitester/')
driver.maximize_window() #最大化当前窗口
driver.execute_script('window.scrollTo(0,0);')
#执行JavaScript语句,通过js 来操作滚动条
driver.find_element_by_id('i1').send_keys(111)
2 name 定位 driver.find_element_by_name()
HTML 规定name 来指定元素的名称,因此它的作用更像是人的姓名
driver.find_element_by_name('name').send_keys(111)
3 class 定位 driver.find_element_by_class()
HTML 规定class 来指定元素的类名
driver.find_element_by_class_name('classname').send_keys(111)
4 tag 定位(标签名定位) driver.find_element_by_tag_name()
HTML 的本质就是通过tag来定义实现不同的功能,每一个元素本质上也是一个tag
因为一个tag 往往用来定义一类功能,所以通过tag识别某个元素的概率很低
一个页面都会有大量的<div> ,<input> <a> 等tag ,所以很难通过标tag name 去区分不同的元素
driver.find_element_by_tag_name('input').send_keys('tag-name')
#默认写入第一个input 标签内
5 link text 定位(文本定位) driver.find_element_by_link_text()
代码 <a href="http://www.imdsx.cn">跳转大师兄博客地址</a>
driver.find_element_by_link_text('跳转大师兄博客地址').click()
通过上面的代码发现, find_element_by_link_text()方法通过元素标签对之间的文本信息来定位元素
6 partial link 定位 driver.find_element_by_partial_link_text()
partial link 定位是对link 定位的一种补充,有些文本链接会比较长,这个时候可以取文本链接的一部分定位,只要这一部分信息可以唯一地标识这个链接
driver.find_element_by_partial_link_text('师兄博客地址').click()
通过上面的代码发现, find_element_by_partial_link_text()方法也是通过元素标签对之间的文本信息来定位元素
7 Xpath 定位 driver.find_element_by_xpath()
XPath是XML的路径语言,通俗一点讲就是通过元素的路径来查找到这个标签元素
XPath 使用方法
7.1 //* 定位页面下所有元素
7.2 绝对路径定位
7.3 利用元素属性定位
driver.find_element_by_xpath('//input[@placeholder="请通过XPATH定位元素"]')
driver.find_element_by_xpath('//*[@placeholder="请通过XPATH定位元素"]')
//表示当前页面某个目录下
input 表示定位元素的标签名,如果不想指定标签名,用* 代替
[ ] 固定格式
@ 表示引用某样属性
placeholder="请通过XPATH定位元素" 元素的属性值
知识扩展:
使用绝对路径定位的缺点:前端修改层级后,之前的case报废
通过属性定位的方式可以提高容错率
7.4 层级与属性结合(层级过滤)
当标签页重复时,Xpath提供了层级过滤
例如:找不到儿子,那么就先找他的爸爸,实在不行可以再找他的爷爷
//form/div/input[@placeholder="用户名"]
支持通过 / 进行层级递进,找到符合层级关系的标签
一个元素它的兄弟元素跟它的标签一样,这时候无法通过层级定位到。因为都是一个父亲生的,多胞胎兄弟。Xpath提供了索引过滤
通过索引,在List中定位属性,与python的索引有些差别,Xpath从1开始
8 CSS 定位 driver.find_element_by_css_selector()
Css Selector定位实际就是HTML的Css选择器的标签定位
CSS 选择器常用语法如下图:(参考链接 http://www.w3school.com.cn/cssref/css_selectors.asp)
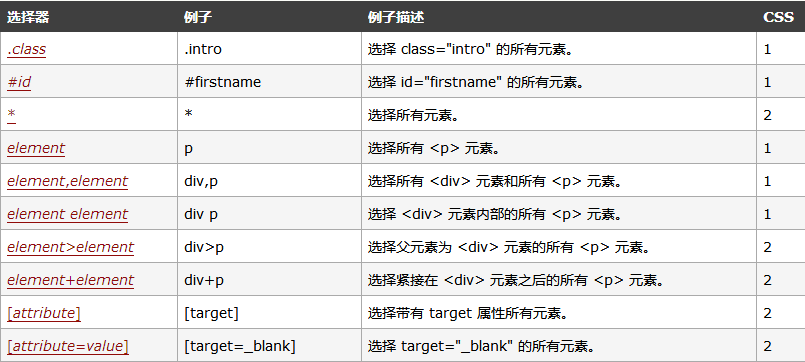

8.1 通过class 属性定位
. 代表通过class属性来定位元素 .c1
8.3 通过属性定位
9 用By 定位元素 driver.find_element()
通过查看Webdriver 的底层实现代码发现:
以上八种定位方式,最后都是调用find_element() 方法
它需要两个参数,第一个参数是定位的类型,由BY 提供,第二个参数是定位的具体方式
满足W3C 最后都是通过BY.CSS_SELECTOR 方法定位
底层代码如下:
def find_element(self, by=By.ID, value=None):
"""
'Private' method used by the find_element_by_* methods. :Usage:
Use the corresponding find_element_by_* instead of this. :rtype: WebElement
"""
if self.w3c:
if by == By.ID:
by = By.CSS_SELECTOR
value = '[id="%s"]' % value
elif by == By.TAG_NAME:
by = By.CSS_SELECTOR
elif by == By.CLASS_NAME:
by = By.CSS_SELECTOR
value = ".%s" % value
elif by == By.NAME:
by = By.CSS_SELECTOR
value = '[name="%s"]' % value
return self.execute(Command.FIND_ELEMENT, {
'using': by,
'value': value})['value']
10 以上九种定位方式的复数形式
elements返回list 用角标取值
需要循环的时候用复数形式
driver.find_elements_by_class_name('classname')[0].send_keys('111')
二、定位控件
appium 通过 uiautomatorviewer.bat 工具来查看控件的属性。该工具位于 Android SDK 的 /tools/bin/ 目录下。
1、id 定位
driver.find_element_by_id('resource-id')
# ID定位于selenium不同,可能存在重复的问题。
# appium-desktop抓取元素时如果出现有id,则可以直接用。
selenium 之定位方法的更多相关文章
- selenium各种定位方法(转)
selenium使用 Xpath CSS JavaScript jQuery的定位方法 (治疗selenium各种定位不到,点击不了的并发症) 2017年07月28日 22:47:36 阅读数:369 ...
- python selenium八大定位方法
一.定位方法 注意:元素属性必须唯一存在 #id定位 find_element_by_id() #name定位 find_element_by_name() #class_name定位 find_el ...
- python之selenium元素定位方法
前提: 大家好,今天我们来学习一下selenium,今天主要讲解selenium定位元素的方法,希望对大家有所帮助! 内容: 一,selenium定位元素 selenium提供了8种方法: 1.id ...
- selenium的定位方法-多元素定位
在实际工作中,有些时候定位元素使用ID.NAME.CLASS_NMAE.XPATH等方法无法定位到具体元素,会发现元素属性有很多一致的,这个时候使用单元素定位方法无法准确定位到具体元素,例如,百度首页 ...
- selenium的定位方法-单元素定位
selenium自动化测试中,提供了单个元素定位方法,多个元素定位方法,2种方式都是根据元素属性:ID.NAME.CLASS_NAME.TAG_NAME.CSS_SELECTOR.XPATH.LINK ...
- python selenium(定位方法)
一.定位方法 注意:元素属性必须唯一存在 #id定位 find_element_by_id() #name定位 find_element_by_name() #class_name定位 find_el ...
- selenium自动化定位方法
用selenium操作浏览器进行自动化操作其实就是通过元素属性执行相关操作.所以,我们要知道怎样去查找元素,定位元素. 常见的定位属性有: #查找元素的id find_elements_by_id(i ...
- selenium元素定位方法
一.如何找到页面元素 Webdriver的findElement方法可以用来找到页面的某个元素,最常用的方法是用id和name查找.下面介绍几种比较常用的方法. 1.1By ID 假设页面写成这样:i ...
- selenium元素定位方法之轴定位
一.轴运算名称 ancestor:祖先结点(包括父结点) parent:父结点 preceding:当前元素节点标签之前的所有结点(html页面先后顺序) preceding-sibling:当前元素 ...
随机推荐
- 我使用过的Linux命令之sftp - 安全文件传输命令行工具
用途说明 sftp命令可以通过ssh来上传和下载文件,是常用的文件传输工具,它的使用方式与ftp类似,但它使用ssh作为底层传输协议,所以安全性比ftp要好得多. 常用方式 格式:sftp <h ...
- Codeforces Round #190 (Div. 2).D
一道贪心题. 可以分两种情况 1 .是没有把对面的牌全打败,那么只要用最大的可能去打攻击状态的牌. 2. 是将对面的牌全打败,那么只要保证打对面防守状态的花费最小,就可以保证最后的结果最大 两种情况下 ...
- gulp 报错'wacth' errord
gulp.wacth(...).watch is not a function 如图: 检查了gulpfile.js文件中的wacth事件:发现这样的写法出错: gulp.task('watch', ...
- MySql指令大全(转载)
1.连接Mysql 格式: mysql -h主机地址 -u用户名 -p用户密码 1.连接到本机上的MYSQL.首先打开DOS窗口,然后进入目录mysql\bin,再键入命令mysql -u root ...
- js 高程 函数节流 throttle() 分析与优化
在 js 高程 22.3.3章节 里看到了 函数节流 的概念,觉得给出的代码可以优化,并且概念理解可以清晰些,所以总结如下: 先看 函数节流 的定义,书上原话(斜体表示): 产生原因/适用场景: 浏览 ...
- maven打包排除spring-boot内嵌tomcat容器依赖jar
在pom文件中添加打包排除配置信息. <plugin> <artifactId>maven-war-plugin</artifactId> <version& ...
- 堪称神器的Windows软件推荐
更多软件使用技巧.破解软件以及硬件选购知识,欢迎加入我的QQ群(701974765)与我们交流!! 先贴上软件列表,详细描述后期更新,可自行百度 TrafficMonitor CPU.内存.网速资源监 ...
- java 程序命名规则
程序命名规则提示:模块设计人员确定本软件的模块命名规则(例如类.函数.变量等),确保模块设计文档的风格与代码的风格保持一致.可以从机构的编程规范中摘取或引用(如果存在的话).命名规则1.包命名 ...
- swift 下storyboard的页面跳转和传值
------------------1. 最简单的方法 拖拽, 这个就不用多解释了吧. 直接拖拽到另一个视图控制器, 选择 show, 就行了. 2. 利用 Segue 方法 (这里主要是 方法1 的 ...
- Netty 粘包/半包原理与拆包实战
Java NIO 粘包 拆包 (实战) - 史上最全解读 - 疯狂创客圈 - 博客园 https://www.cnblogs.com/crazymakercircle/p/9941658.html 本 ...