什么是spark(五)Spark SQL
Spark SQL
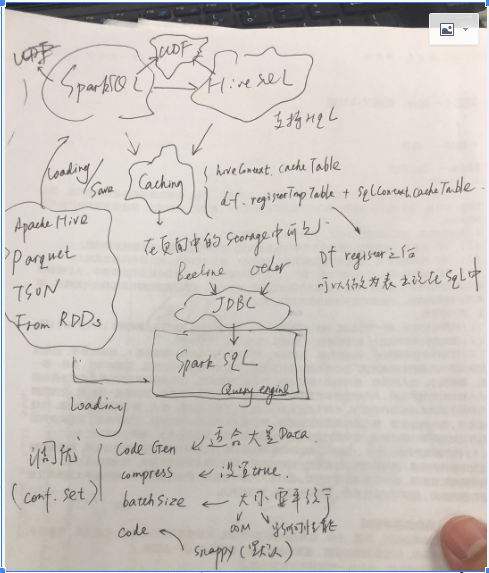
Spark SQL主要分为两部分,一部分是Spark Sql在scala中直接,使用作为执行层面上的应用,本质上就是生成DAG的另外一种形式;其发生试下Driver中生成;
另外一部分是spark SQL作为查询引擎,供client端通过jdbc来进行调用;
SparkContext和HiveContext是sparkSQL开发索要操作的对象,后者提供了HQL的查询;前者不支持HQL,但是支持普通的SQL;很多针对Hive的一些sql不支持,所以对于Hive表的查询,建议使用HiveContext;基本的思路是首先通过SQL语句获得dataframe,通过dataframe进行注册
除此之外Spark/HivecContext支持Cache;Cache的数据将会在Spark的页面中的Storage中看到;支持UDF(User Define Function)。
SparkSQL同样支持Hive,Parquet,JSON,而且可以通过RDD获得DataFrame;
SparkSQL调优:
1)code gen,适合于大量的数据;
2)compress,对于内存数据进行压缩;
3)batchsize,多少数据进行压缩;
4)codec,压缩的编码;
这些调优参数都是在conf里面设置的。
什么是spark(五)Spark SQL的更多相关文章
- 大数据技术之_27_电商平台数据分析项目_02_预备知识 + Scala + Spark Core + Spark SQL + Spark Streaming + Java 对象池
第0章 预备知识0.1 Scala0.1.1 Scala 操作符0.1.2 拉链操作0.2 Spark Core0.2.1 Spark RDD 持久化0.2.2 Spark 共享变量0.3 Spark ...
- [Spark][Python][DataFrame][SQL]Spark对DataFrame直接执行SQL处理的例子
[Spark][Python][DataFrame][SQL]Spark对DataFrame直接执行SQL处理的例子 $cat people.json {"name":" ...
- [Spark][Hive][Python][SQL]Spark 读取Hive表的小例子
[Spark][Hive][Python][SQL]Spark 读取Hive表的小例子$ cat customers.txt 1 Ali us 2 Bsb ca 3 Carls mx $ hive h ...
- Spark Shell启动时遇到<console>:14: error: not found: value spark import spark.implicits._ <console>:14: error: not found: value spark import spark.sql错误的解决办法(图文详解)
不多说,直接上干货! 最近,开始,进一步学习spark的最新版本.由原来经常使用的spark-1.6.1,现在来使用spark-2.2.0-bin-hadoop2.6.tgz. 前期博客 Spark ...
- [Spark] 05 - Spark SQL
关于Spark SQL,首先会想到一个问题:Apache Hive vs Apache Spark SQL – 13 Amazing Differences Hive has been known t ...
- Hive on Spark和Spark sql on Hive,你能分的清楚么
摘要:结构上Hive On Spark和SparkSQL都是一个翻译层,把一个SQL翻译成分布式可执行的Spark程序. 本文分享自华为云社区<Hive on Spark和Spark sql o ...
- Spark Shell & Spark submit
Spark 的 shell 是一个强大的交互式数据分析工具. 1. 搭建Spark 2. 两个目录下面有可执行文件: bin 包含spark-shell 和 spark-submit sbin 包含 ...
- 【转】科普Spark,Spark是什么,如何使用Spark
本博文是转自如下链接,为了方便自己查阅学习和他人交流.感谢原博主的提供! http://www.aboutyun.com/thread-6849-1-1.html http://www.aboutyu ...
- 大数据技术之_19_Spark学习_01_Spark 基础解析 + Spark 概述 + Spark 集群安装 + 执行 Spark 程序
第1章 Spark 概述1.1 什么是 Spark1.2 Spark 特点1.3 Spark 的用户和用途第2章 Spark 集群安装2.1 集群角色2.2 机器准备2.3 下载 Spark 安装包2 ...
- [Spark][Python]spark 从 avro 文件获取 Dataframe 的例子
[Spark][Python]spark 从 avro 文件获取 Dataframe 的例子 从如下地址获取文件: https://github.com/databricks/spark-avro/r ...
随机推荐
- [java]BoneCP 参数详解
BoneCP 参数详解: ======================================== 一.BoneCP配置文件格式(bonecp-config.xml): xml versio ...
- Python之坐标轴刻度细化、坐标轴设置、标题图例添加
学习python中matplotlib绘图设置坐标轴刻度.文本 http://www.jb51.net/article/134638.htm Python绘图 https://www.cnblogs. ...
- How to find per-process I/O statistics on Linux
以下转自http://www.xaprb.com/blog/2009/08/23/how-to-find-per-process-io-statistics-on-linux/ Newer Linux ...
- phpMyAdmin 应用程序“DEFAULT WEB SITE”中的服务器错误
分析原因:没有“C:\inetpub\wwwroot\phpmyadmin\”此目录 解决办法:新建路径 分析原因:IIS设置少了一项,需添加"服务端包含"选项 解决办法:控制面板 ...
- 自定义URL协议在Web中启动本地应用程序
转自(http://blog.csdn.net/jackychen_king/article/details/7743811) 1.注册应用程序来处理自定义协议 你必须添加一个新的key以及相关的va ...
- 【codeforces-482div2-C】Kuro and Walking Route(DFS)
题目链接:http://codeforces.com/contest/979/problem/C Kuro is living in a country called Uberland, consis ...
- 使用 Express 实现一个简单的 SPA 静态资源服务器
背景 限制 SPA 应用已经成为主流,在项目开发阶段产品经理和后端开发同学经常要查看前端页面,下面就是我们团队常用的使用 express 搭建的 SPA 静态资源服务器方案. 为 SPA 应用添加入口 ...
- LeetCode OJ:Generate Parentheses(括号生成)
Given n pairs of parentheses, write a function to generate all combinations of well-formed parenthes ...
- C++STL内存配置的设计思想与关键源码分析
说明:我认为要读懂STL中allocator部分的源码,并汲取它的思想,至少以下几点知识你要了解:operator new和operator delete.handler函数以及一点模板知识.否则,下 ...
- C#设置System.Net.ServicePointManager.DefaultConnectionLimit,突破Http协议的并发连接数限制
在Http协议中,规定了同个Http请求的并发连接数最大为2. 这个数值,可谓是太小了. 而目前的浏览器,已基本不再遵循这个限制,但是Dot Net平台上的 System.Net 还是默认遵循了这个标 ...