【原创】Kafka Consumer多线程实例

| 优点 | 缺点 | |
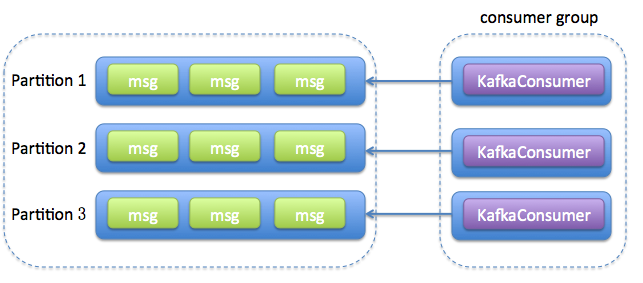
| 方法1(每个线程维护一个KafkaConsumer) | 方便实现 速度较快,因为不需要任何线程间交互 易于维护分区内的消息顺序 |
更多的TCP连接开销(每个线程都要维护若干个TCP连接) consumer数受限于topic分区数,扩展性差 频繁请求导致吞吐量下降 线程自己处理消费到的消息可能会导致超时,从而造成rebalance |
| 方法2 (单个(或多个)consumer,多个worker线程) | 可独立扩展consumer数和worker数,伸缩性好 |
实现麻烦
通常难于维护分区内的消息顺序
处理链路变长,导致难以保证提交位移的语义正确性
|
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer; import java.util.Arrays;
import java.util.Properties; public class ConsumerRunnable implements Runnable { // 每个线程维护私有的KafkaConsumer实例
private final KafkaConsumer<String, String> consumer; public ConsumerRunnable(String brokerList, String groupId, String topic) {
Properties props = new Properties();
props.put("bootstrap.servers", brokerList);
props.put("group.id", groupId);
props.put("enable.auto.commit", "true"); //本例使用自动提交位移
props.put("auto.commit.interval.ms", "1000");
props.put("session.timeout.ms", "30000");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
this.consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList(topic)); // 本例使用分区副本自动分配策略
} @Override
public void run() {
while (true) {
ConsumerRecords<String, String> records = consumer.poll(200); // 本例使用200ms作为获取超时时间
for (ConsumerRecord<String, String> record : records) {
// 这里面写处理消息的逻辑,本例中只是简单地打印消息
System.out.println(Thread.currentThread().getName() + " consumed " + record.partition() +
"th message with offset: " + record.offset());
}
}
}
}
ConsumerGroup类
package com.my.kafka.test; import java.util.ArrayList;
import java.util.List; public class ConsumerGroup { private List<ConsumerRunnable> consumers; public ConsumerGroup(int consumerNum, String groupId, String topic, String brokerList) {
consumers = new ArrayList<>(consumerNum);
for (int i = 0; i < consumerNum; ++i) {
ConsumerRunnable consumerThread = new ConsumerRunnable(brokerList, groupId, topic);
consumers.add(consumerThread);
}
} public void execute() {
for (ConsumerRunnable task : consumers) {
new Thread(task).start();
}
}
}
ConsumerMain类
public class ConsumerMain {
public static void main(String[] args) {
String brokerList = "localhost:9092";
String groupId = "testGroup1";
String topic = "test-topic";
int consumerNum = 3;
ConsumerGroup consumerGroup = new ConsumerGroup(consumerNum, groupId, topic, brokerList);
consumerGroup.execute();
}
}
方法2
import org.apache.kafka.clients.consumer.ConsumerRecord;
public class Worker implements Runnable {
private ConsumerRecord<String, String> consumerRecord;
public Worker(ConsumerRecord record) {
this.consumerRecord = record;
}
@Override
public void run() {
// 这里写你的消息处理逻辑,本例中只是简单地打印消息
System.out.println(Thread.currentThread().getName() + " consumed " + consumerRecord.partition()
+ "th message with offset: " + consumerRecord.offset());
}
}
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer; import java.util.Arrays;
import java.util.Properties;
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit; public class ConsumerHandler { // 本例中使用一个consumer将消息放入后端队列,你当然可以使用前一种方法中的多实例按照某张规则同时把消息放入后端队列
private final KafkaConsumer<String, String> consumer;
private ExecutorService executors; public ConsumerHandler(String brokerList, String groupId, String topic) {
Properties props = new Properties();
props.put("bootstrap.servers", brokerList);
props.put("group.id", groupId);
props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", "1000");
props.put("session.timeout.ms", "30000");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList(topic));
} public void execute(int workerNum) {
executors = new ThreadPoolExecutor(workerNum, workerNum, 0L, TimeUnit.MILLISECONDS,
new ArrayBlockingQueue<>(1000), new ThreadPoolExecutor.CallerRunsPolicy()); while (true) {
ConsumerRecords<String, String> records = consumer.poll(200);
for (final ConsumerRecord record : records) {
executors.submit(new Worker(record));
}
}
} public void shutdown() {
if (consumer != null) {
consumer.close();
}
if (executors != null) {
executors.shutdown();
}
try {
if (!executors.awaitTermination(10, TimeUnit.SECONDS)) {
System.out.println("Timeout.... Ignore for this case");
}
} catch (InterruptedException ignored) {
System.out.println("Other thread interrupted this shutdown, ignore for this case.");
Thread.currentThread().interrupt();
}
} }
public class Main {
public static void main(String[] args) {
String brokerList = "localhost:9092,localhost:9093,localhost:9094";
String groupId = "group2";
String topic = "test-topic";
int workerNum = 5;
ConsumerHandler consumers = new ConsumerHandler(brokerList, groupId, topic);
consumers.execute(workerNum);
try {
Thread.sleep(1000000);
} catch (InterruptedException ignored) {}
consumers.shutdown();
}
}
总结一下,这两种方法或是模型都有各自的优缺点,在具体使用时需要根据自己实际的业务特点来选取对应的方法。就我个人而言,我比较推崇第二种方法以及背后的思想,即不要将很重的处理逻辑放入消费者的代码中,很多Kafka consumer使用者碰到的各种rebalance超时、coordinator重新选举、心跳无法维持等问题都来源于此。
【原创】Kafka Consumer多线程实例的更多相关文章
- 【原创】Kafka Consumer多线程实例续篇
在上一篇<Kafka Consumer多线程实例>中我们讨论了KafkaConsumer多线程的两种写法:多KafkaConsumer多线程以及单KafkaConsumer多线程.在第二种 ...
- kafka系列 -- 多线程消费者实现
看了一下kafka,然后写了消费Kafka数据的代码.感觉自己功力还是不够. 不能随心所欲地操作数据,数据结构没学好,spark的RDD操作没学好. 不能很好地组织代码结构,设计模式没学好,面向对象思 ...
- 【原创】kafka consumer源代码分析
顾名思义,就是kafka的consumer api包. 一.ConsumerConfig.scala Kafka consumer的配置类,除了一些默认值常量及验证参数的方法之外,就是consumer ...
- 【原创】美团二面:聊聊你对 Kafka Consumer 的架构设计
在上一篇中我们详细聊了关于 Kafka Producer 内部的底层原理设计思想和细节, 本篇我们主要来聊聊 Kafka Consumer 即消费者的内部底层原理设计思想. 1.Consumer之总体 ...
- kafka consumer assign 和 subscribe模式差异分析
转载请注明原创地址:http://www.cnblogs.com/dongxiao-yang/p/7200971.html 最近需要研究flink-connector-kafka的消费行为,发现fli ...
- Kafka设计解析(四)- Kafka Consumer设计解析
本文转发自Jason’s Blog,原文链接 http://www.jasongj.com/2015/08/09/KafkaColumn4 摘要 本文主要介绍了Kafka High Level Con ...
- 读Kafka Consumer源码
最近一直在关注阿里的一个开源项目:OpenMessaging OpenMessaging, which includes the establishment of industry guideline ...
- kafka consumer 配置详解
1.Consumer Group 与 topic 订阅 每个Consumer 进程都会划归到一个逻辑的Consumer Group中,逻辑的订阅者是Consumer Group.所以一条message ...
- [Big Data - Kafka] Kafka设计解析(四):Kafka Consumer解析
High Level Consumer 很多时候,客户程序只是希望从Kafka读取数据,不太关心消息offset的处理.同时也希望提供一些语义,例如同一条消息只被某一个Consumer消费(单播)或被 ...
随机推荐
- 立即执行函数表达式(IIFE)
原文地址:benalman.com/news/2010/11/immediately-invoked-function-expression/ 译者:nzbin 也许你还没有注意到,我是一个对术语比较 ...
- Chrome V8引擎系列随笔 (1):Math.Random()函数概览
先让大家来看一幅图,这幅图是V8引擎4.7版本和4.9版本Math.Random()函数的值的分布图,我可以这么理解 .从下图中,也许你会认为这是个二维码?其实这幅图告诉我们一个道理,第二张图的点的分 ...
- 设计模式之行为类模式大PK
行为类模式大PK 行为类模式包括责任链模式.命令模式.解释器模式.迭代器模式.中介者模式.备忘录模式.观察者模式.状态模式.策略 ...
- 代码的坏味道(21)——中间人(Middle Man)
坏味道--中间人(Middle Man) 特征 如果一个类的作用仅仅是指向另一个类的委托,为什么要存在呢? 问题原因 对象的基本特征之一就是封装:对外部世界隐藏其内部细节.封装往往伴随委托.但是人们可 ...
- C# Entity Framework并发处理
原网站:C# Entity Framework并发处理 在软件开发过程中,并发控制是确保及时纠正由并发操作导致的错误的一种机制.从 ADO.NET 到 LINQ to SQL 再到如今的 ADO.NE ...
- 解决IE8下不兼容rgba()的解决办法
rgba()是css3的新属性,所以IE8及以下浏览器不兼容,这怎么办呢?终于我找到了解决办法. 解决办法 我们先来解释以下rgba rgba: rgba的含义,r代表red,g代表green,b代表 ...
- Android Weekly Notes Issue #234
Android Weekly Issue #234 December 4th, 2016 Android Weekly Issue #234 本期内容包括: ConstraintLayout的使用; ...
- maven 快照
大型应用软件一般由多个模块组成,一般它是多个团队开发同一个应用程序的不同模块,这是比较常见的场景.例如,一个团队正在对应用程序的应用程序,用户界面项目(app-ui.jar:1.0) 的前端进行开发, ...
- linux压缩和解压缩命令大全
.tar 解包:tar zxvf FileName.tar 打包:tar czvf FileName.tar DirName ------------------------------------- ...
- 【腾讯Bugly干货分享】聊聊苹果的Bug - iOS 10 nano_free Crash
本文来自于腾讯Bugly公众号(weixinBugly),未经作者同意,请勿转载,原文地址:https://mp.weixin.qq.com/s/hnwj24xqrtOhcjEt_TaQ9w 作者:张 ...