MySQL优化器 limit影响的case
测试的用例中,因为limit的大小不同,而产生了完全不同的执行计划:
1. 测试case:
create table t1 (
f1 int() not null,
f2 int() not null,
f3 int() not null,
f4 tinyint() not null,
primary key (f1),
unique key (f2, f3),
key (f4)
) engine=innodb; insert into t1 values
(,,,), (,,,), (,,,), (,,,), (,,,),
(,,,), (,,,), (,,,), (,,,), (,,,),
(,,,), (,,,), (,,,), (,,,), (,,,),
(,,,), (,,,), (,,,), (,,,), (,,,),
(,,,), (,,,);
2. 两个不同limit的sql生成的执行计划:
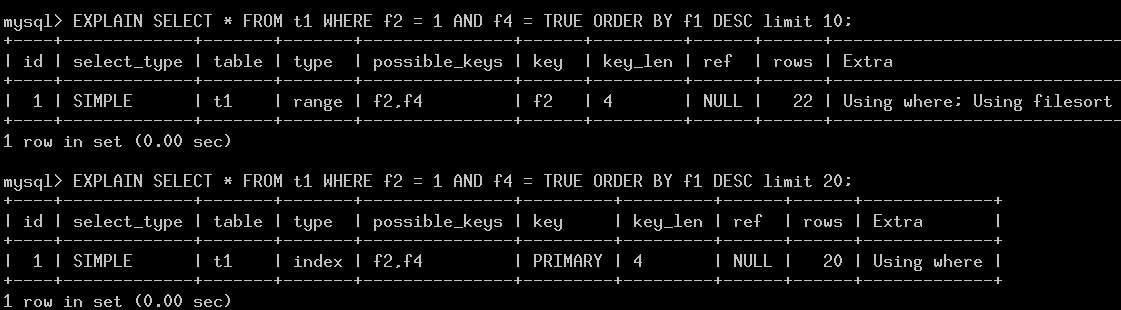
3. 分析过程:
step 1. 获取可用的key,并计算rows
update_ref_and_keys
get_quick_record_count
结果: f2, f4可用, 其分配的quick_rows=[22, 22]

从上面的cardinality来看,f2,f4的过滤性都是2, 这样扫描f2,需要11行,然后根据primary回聚簇表扫描,有需要11行,所有,使用f2, f4索引的扫描需要22行。
step2:穷举下执行计划,找到cost最低的
best_access_path
best_extension_by_limited_search
结果: 全表扫描的代价比较低,records=17, cost=2, 所以最后join->best_position[0]记录的就是全表扫描的执行计划。
step3:limit的影响
在make_join_select的过程,对于limit进行处理,理由是:如果有limit,并且比当前best_position的记录数小,我们尝试是否有可用的index,减少扫描代价
所以,在limit=10的时候,进行test_quick_select查找,并使用f2的索引。而limit=20的查询,不满足条件,所以继续使用全表扫描。
相关注释和代码如下:
/*
We plan to scan all rows.
Check again if we should use an index.
We could have used an column from a previous table in
the index if we are using limit and this is the first table
*/
if ((cond &&
!tab->keys.is_subset(tab->const_keys) && i > ) ||
(!tab->const_keys.is_clear_all() && i == join->const_tables &&
join->unit->select_limit_cnt <
join->best_positions[i].records_read &&
!(join->select_options & OPTION_FOUND_ROWS)))
step4: order by的影响
函数:test_if_skip_sort_order
limit=10:ref_key=f2: 判断有一个primary key的index可以覆盖order by查询, 但走pk的代价高于ref_key=f2。
limit=20:ref_key=0: 判断有一个primary key的index可以覆盖order by查询,而且当前使用的是全表扫描,代价小于全表,所以选择pk。
所以,两个limit值不同的查询,导致了不同的执行计划。
MySQL优化器 limit影响的case的更多相关文章
- 0104探究MySQL优化器对索引和JOIN顺序的选择
转自http://www.jb51.net/article/67007.htm,感谢博主 本文通过一个案例来看看MySQL优化器如何选择索引和JOIN顺序.表结构和数据准备参考本文最后部分" ...
- 机智的MySQL优化器 --- is null
[介绍] 工作的越久越到的的问题越多,就越是觉得一些“老话”历久弥新:由于最近的学习计划是深入的学习一遍MySQL优化器:学习过程中的一些成果 也会发布到这里,一来是为了整理自己已经知道的和新学到的, ...
- 数据库 mysql 优化器原理
MySQL查询优化器有几个目标,但是其中最主要的目标是尽可能地使用索引,并且使用最严格的索引来消除尽可能多的数据行. 你的最终目标是提交SELECT语句查找数据行,而不是排除数据行.优化器试图排除数据 ...
- MySQL优化器功能开关optimizer_switch
MySQL 8.0新增特性 use_invisible_indexes:是否使用不可见索引,MySQL 8.0新增可以创建invisible索引,这一开关控制优化器是否使用invisible索引,on ...
- 《Mysql - 优化器是如何选择索引的?》
一:概念 - 在 索引建立之后,一条语句可能会命中多个索引,这时,索引的选择,就会交由 优化器 来选择合适的索引. - 优化器选择索引的目的,是找到一个最优的执行方案,并用最小的代价去执行语句. 二: ...
- 如何干涉MySQL优化器使用hash join
GreatSQL社区原创内容未经授权不得随意使用,转载请联系小编并注明来源. GreatSQL是MySQL的国产分支版本,使用上与MySQL一致. 前言 实验 总结 前言 数据库的优化器相当于人类的大 ...
- MySQL优化器cost计算
记录MySQL 5.5上,优化器进行cost计算的方法. 第一篇: 单表的cost计算 数据结构: 1. table_share: 包含了表的元数据,其中索引部分: key_info:一个key的结构 ...
- MySQL优化器 --- index_merge
[背景] 对于关系数据库中的一张表,通常来说数据页面的总大小要比较某一个索引占用的页面要大的多(上面说的索引是不包涵主键索引的); 更进一步我们可以推导出,如果我们通过读索引就能解决问题,那么它相比读 ...
- MySQL优化器不使用索引的情况
优化器选择不适用索引的情况 有时候,有乎其并没有选择索引而去查找数据,而是通过扫描聚集索引,也就是直接进行全表的扫描来得到数据.这种情况多发生于范围查找.JOIN链接操作等情况.例如 ; 通过SHOW ...
随机推荐
- try catch finally 关闭流标准的写法
平常开发中,都知道要在finlly里关闭流,但是有时finlly里代码不当,会引起另外的异常. 以下是看struts2源代码看到的,随手记录下. 有两点注意: (1)判断流是否为空. (2)filly ...
- Opencv Mat的操作
cout << mat 有错误的原因 You are using OpenCV built with VS10. The ostream operator << in the ...
- SIM900A访问HTTP的简单方法
最近做项目,使用Arduino控制设备,读取数据,然后通过移动网络传送到服务器. 我选用的是正点原子的SIM900A模块.在服务器部署了一个监听程序,Arduino控制SIM900A通过TCP方式把数 ...
- 1035 Password (20)
#include <stdio.h> #include <string.h> struct MyStruct { ]; ]; bool changed; }; int main ...
- 《ENVI下遥感影像自然真彩色合成方法》——TM、spot5
来源:http://blog.sina.com.cn/s/blog_764b1e9d0100tz4f.html#bsh-73-375271630
- 使用plspl创建orcale作业
1.由于权限问题,第一步应先以sys账户登录,路径:工具->DBMS 调试程序->作业 ,新建一个作业,出现如下图的窗口 2.开始依次填写相应内容,Name为作业名字,注意要加上用户名前 ...
- 在DataTable中执行DataTable.Select("条件")
.在DataTable中执行DataTable.Select("条件")返回DataTable: // <summary> // 执行DataTable中的查询返回 ...
- android/IOS各平台分享链接/跳转链接配置说明(备用)
Android: [Java] 纯文本查看 复制代码 ? 01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 微信/朋友圈 //设置 ...
- ServiceStack.Redis
什么是Redis 首先,简述一下什么是Redis. Redis是一个开源.支持网络.基于内存.键值对存储数据库,使用ANSI C编写.从2013年5月开始,Redis的开发由Pivotal赞助.在这之 ...
- mysql 增加删除用户
mysql 增加用户 (注意:因为MYSQL环境中的命令,所以后面都带一个分号作为命令结束符) 格式:grant select on 数据库.* to 用户名@登录主机 identified by ' ...