CentOS7 部署 Hadoop 3.2.1 (伪分布式)
CentOS: Linux localhost.localdomain 3.10.0-862.el7.x86_64 #1 SMP Fri Apr 20 16:44:24 UTC 2018 x86_64 x86_64 x86_64 GNU/Linux
JDK: Oracle jdk1.8.0_241 , https://www.oracle.com/java/technologies/javase-jdk8-downloads.html
Hadoop : hadoop-3.2.1.tar.gz
官方安装文档:https://hadoop.apache.org/docs/r3.2.1/hadoop-project-dist/hadoop-common/SingleCluster.html
1、设置自身免登陆,输入命令(红色部分)
# ssh-keygen
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
1b:e4:ff::::6a:2f:::b0:ec::fe:5b: root@localhost.localdomain
The key's randomart image is:
+--[ RSA ]----+
| .... .|
| . .. o.|
| ..o . o. |
| ooo +. |
| ESo o.. |
| o+. .o . |
| ....... |
| o.. |
| . .. |
+-----------------+
# cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
# chmod 600 ~/.ssh/authorized_keys
# ssh root@localhost
Last login: Sun Mar ::
2.关闭selinux、防火墙
a. 永久有效
修改 /etc/selinux/config 文件中的 SELINUX=enforcing 修改为 SELINUX=disabled ,然后重启。
b. 临时生效
# setenforce
# systemctl stop firewalld.service
# systemctl disable iptables.service
3.下载Java SDK,前往 https://www.oracle.com/java/technologies/javase-jdk8-downloads.html 下载
# mkdir /data/server/hadoop/
# cd /data/server/hadoop/
# rz #选择你下载好的文件,上传到当前目录下
# tar zxvf jdk-8u241-linux-x64.tar.gz
4. 下载Hadoop,前往https://downloads.apache.org/hadoop/common/ 选择你想要的版本,这里选最新版本3.2.1
# cd /data/server/hadoop
# wget https://downloads.apache.org/hadoop/common/hadoop-3.2.1/hadoop-3.2.1.tar.gz
# tar zxvf hadoop-3.2..tar.gz
# mv hadoop-3.2./ 3.2.
5.设置Hadoop环境变量,vi /etc/profile ,在末尾增加如下内容:
#hadoop
export HADOOP_HOME=/data/server/hadoop/3.2.
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_YARN_HOME=$HADOOP_HOME
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin export HDFS_DATANODE_USER=root
export HDFS_DATANODE_SECURE_USER=root
export HDFS_NAMENODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
再执行使变量生效
# source /etc/profile
6.设置JAVA_HOME, vi 3.2.1/etc/hadoop/hadoop-env.sh ,末尾添加如下内容:
export JAVA_HOME=/data/server/hadoop/jdk1.8.0_241
7.查看是否正常
# hadoop version
Hadoop 3.2.
Source code repository https://gitbox.apache.org/repos/asf/hadoop.git -r b3cbbb467e22ea829b3808f4b7b01d07e0bf3842
Compiled by rohithsharmaks on --10T15:56Z
Compiled with protoc 2.5.
From source with checksum 776eaf9eee9c0ffc370bcbc1888737
This command was run using /home/data/server/hadoop/3.2./share/hadoop/common/hadoop-common-3.2..jar
8.重命名启动脚本,避免和spark服务脚本冲突(可不删除cmd脚本)。
rm -rf ./3.2./sbin/*.cmd
rm -rf ./3.2.1/bin/*.cmd mv ./3.2.1/sbin/start-all.sh ./3.2.1/sbin/start-hadoop-all.sh
mv ./3.2.1/sbin/stop-all.sh ./3.2.1/sbin/stop-hadoop-all.sh
Hadoop设置
编辑 3.2.1/etc/hadoop/core-site.xml :
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://172.16.1.122:9000</value>
<description>指定HDFS Master(namenode)的通信地址,默认端口</description>
</property> <property>
<name>hadoop.tmp.dir</name>
<value>/data/server/hadoop/3.2.1/tmp</value>
<description>指定hadoop运行时产生文件的存储路径</description>
</property> <property>
<name>hadoop.native.lib</name>
<value>false</value>
<description>是否应使用本机hadoop库(如果存在)</description>
</property>
</configuration>
编辑 3.2.1/etc/hadoop/hdfs-site.xml(参考:https://www.cnblogs.com/duanxz/p/3799467.html) :
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
<description>设置数据块应该被复制的份数</description>
</property> <property>
<name>dfs.safemode.threshold.pct</name>
<value>0</value>
<description>小于等于0意味不进入安全模式,大于1意味一直处于安全模式</description>
</property> <property>
<name>dfs.permissions</name>
<value>false</value>
<description>文件操作时的权限检查标识, 关闭</description>
</property> </configuration>
编辑 3.2.1/etc/hadoop/yarn-site.xml (参考:https://www.cnblogs.com/yinchengzhe/p/5142659.html):
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<description>NodeManager上运行的附属服务。需配置成mapreduce_shuffle,才可运行MapReduce程序</description>
</property> <property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>
编辑 3.2.1/etc/hadoop/mapred-site.xml :
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<description>yarn模式</description>
</property> <property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property> </configuration>
格式化hdfs
# hdfs namenode -format
启动hadoop
# start-hadoop-all.sh
查看启动情况(红色部分)
# /data/server/hadoop/jdk1..0_241/bin/jps
20400 NodeManager
QuorumPeerMain
20054 SecondaryNameNode
19687 NameNode
Jps
19817 DataNode
18108 ResourceManager
至此,hadoop启动成功;
验证hadoop
下面运行一次经典的WorkCount程序来检查hadoop工作是否正常:
创建input文件夹:
# hdfs dfs -mkdir /input
将test.txt文件上传的hdfs的/input目录下:
# hdfs dfs -put ./3.2./LICENSE.txt /input/test.txt
接运行hadoop安装包中自带的workcount程序:
hadoop jar ./3.2./share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2..jar wordcount /input/test.txt /output/
控制台输出结果:
-- ::, INFO client.RMProxy: Connecting to ResourceManager at /172.16.1.122:
-- ::, INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/root/.staging/job_1585465225552_0004
-- ::, INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
-- ::, INFO input.FileInputFormat: Total input files to process :
-- ::, INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
-- ::, INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
-- ::, INFO mapreduce.JobSubmitter: number of splits:
-- ::, INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
-- ::, INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1585465225552_0004
-- ::, INFO mapreduce.JobSubmitter: Executing with tokens: []
-- ::, INFO conf.Configuration: resource-types.xml not found
-- ::, INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
-- ::, INFO impl.YarnClientImpl: Submitted application application_1585465225552_0004
-- ::, INFO mapreduce.Job: The url to track the job: http://172.16.1.122:8088/proxy/application_1585465225552_0004/
-- ::, INFO mapreduce.Job: Running job: job_1585465225552_0004
-- ::, INFO mapreduce.Job: Job job_1585465225552_0004 running in uber mode : false
-- ::, INFO mapreduce.Job: map % reduce %
-- ::, INFO mapreduce.Job: map % reduce %
-- ::, INFO mapreduce.Job: map % reduce %
-- ::, INFO mapreduce.Job: Job job_1585465225552_0004 completed successfully
-- ::, INFO mapreduce.Job: Counters:
File System Counters
FILE: Number of bytes read=
FILE: Number of bytes written=
FILE: Number of read operations=
FILE: Number of large read operations=
FILE: Number of write operations=
HDFS: Number of bytes read=
HDFS: Number of bytes written=
HDFS: Number of read operations=
HDFS: Number of large read operations=
HDFS: Number of write operations=
HDFS: Number of bytes read erasure-coded=
Job Counters
Launched map tasks=
Launched reduce tasks=
Data-local map tasks=
Total time spent by all maps in occupied slots (ms)=
Total time spent by all reduces in occupied slots (ms)=
Total time spent by all map tasks (ms)=
Total time spent by all reduce tasks (ms)=
Total vcore-milliseconds taken by all map tasks=
Total vcore-milliseconds taken by all reduce tasks=
Total megabyte-milliseconds taken by all map tasks=
Total megabyte-milliseconds taken by all reduce tasks=
Map-Reduce Framework
Map input records=
Map output records=
Map output bytes=
Map output materialized bytes=
Input split bytes=
Combine input records=
Combine output records=
Reduce input groups=
Reduce shuffle bytes=
Reduce input records=
Reduce output records=
Spilled Records=
Shuffled Maps =
Failed Shuffles=
Merged Map outputs=
GC time elapsed (ms)=
CPU time spent (ms)=
Physical memory (bytes) snapshot=
Virtual memory (bytes) snapshot=
Total committed heap usage (bytes)=
Peak Map Physical memory (bytes)=
Peak Map Virtual memory (bytes)=
Peak Reduce Physical memory (bytes)=
Peak Reduce Virtual memory (bytes)=
Shuffle Errors
BAD_ID=
CONNECTION=
IO_ERROR=
WRONG_LENGTH=
WRONG_MAP=
WRONG_REDUCE=
File Input Format Counters
Bytes Read=
File Output Format Counters
Bytes Written=
查看输出结果:
# hdfs dfs -ls /output
可见hdfs的/output目录下,有两个文件:
Found items
-rw-r--r-- root supergroup -- : /output/_SUCCESS
-rw-r--r-- root supergroup -- : /output/part-r-
看一下文件part-r-00000的内容:
# hdfs dfs -cat /output/part-r-
hadoop
hbase
hive
mapreduce
spark
sqoop
storm
可见WorkCount计算成功,结果符合预期;
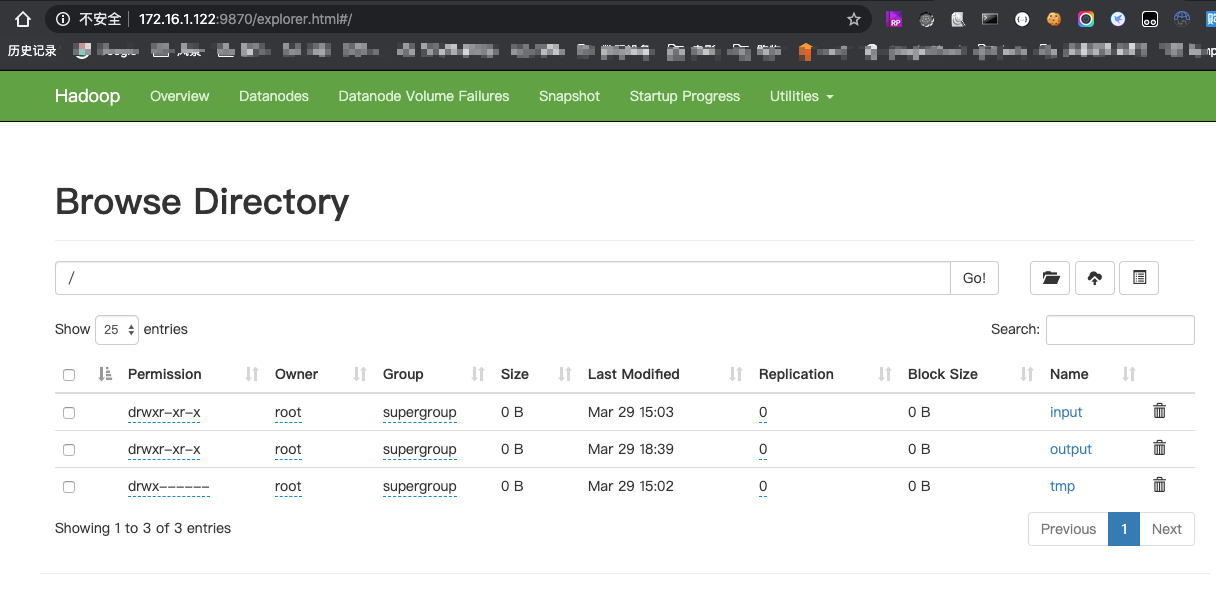
7. hdfs网页如下图,可以看到文件信息,地址:http://172.16.1.122:9870/
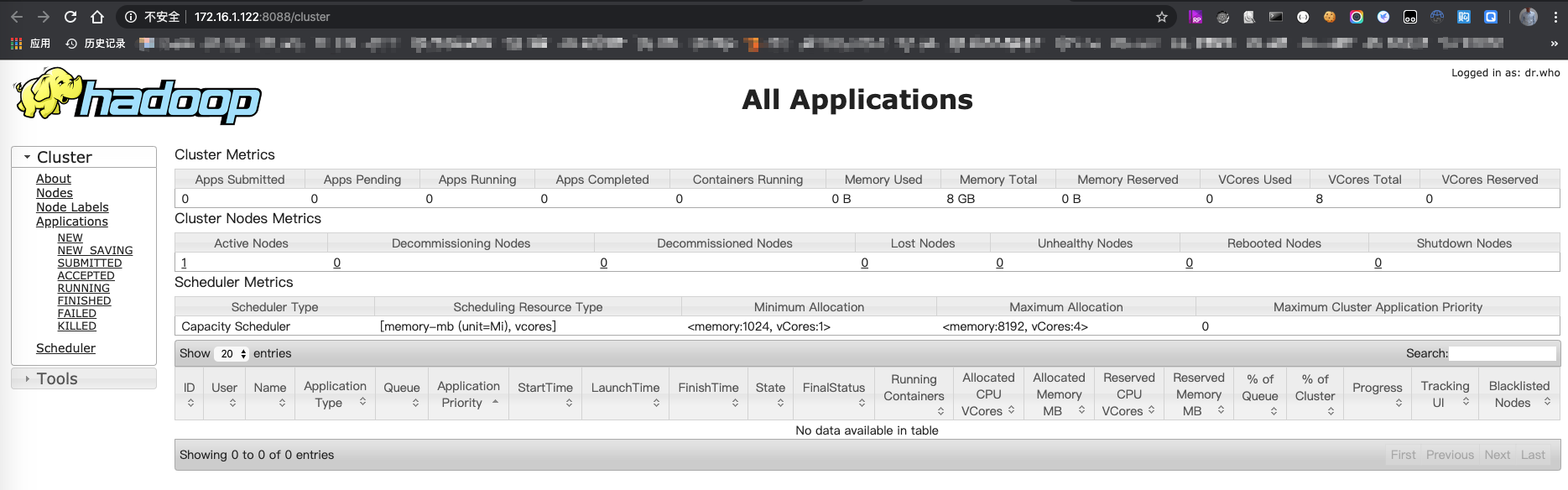
8. yarn的网页如下图,可以看到任务信息,地址:http://172.16.1.122:8088/cluster
至此,hadoop3.2.1伪分布式搭建和验证完毕。
PS:
https://blog.csdn.net/u010476739/article/details/86647585?depth_1-utm_source=distribute.pc_relevant.none-task&utm_source=distribute.pc_relevant.none-task
https://blog.csdn.net/lu1171901273/article/details/86518494
https://blog.csdn.net/chenxun_2010/article/details/78238251
https://www.cnblogs.com/jancco/p/4447756.html
https://blog.csdn.net/pengjunlee/article/details/104290537
CentOS7 部署 Hadoop 3.2.1 (伪分布式)的更多相关文章
- hadoop 2.7.3伪分布式安装
hadoop 2.7.3伪分布式安装 hadoop集群的伪分布式部署由于只需要一台服务器,在测试,开发过程中还是很方便实用的,有必要将搭建伪分布式的过程记录下来,好记性不如烂笔头. hadoop 2. ...
- hadoop 2.7.3伪分布式环境运行官方wordcount
hadoop 2.7.3伪分布式模式运行wordcount 基本环境: 系统:win7 虚机环境:virtualBox 虚机:centos 7 hadoop版本:2.7.3 本次以伪分布式模式来运行w ...
- Hadoop 在windows 上伪分布式的安装过程
第一部分:Hadoop 在windows 上伪分布式的安装过程 安装JDK 1.下载JDK http://www.oracle.com/technetwork/java/javaee/d ...
- Hadoop Single Node Setup(hadoop本地模式和伪分布式模式安装-官方文档翻译 2.7.3)
Purpose(目标) This document describes how to set up and configure a single-node Hadoop installation so ...
- Hadoop生态圈-hbase介绍-伪分布式安装
Hadoop生态圈-hbase介绍-伪分布式安装 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.HBase简介 HBase是一个分布式的,持久的,强一致性的存储系统,具有近似最 ...
- centos 7下Hadoop 2.7.2 伪分布式安装
centos 7 下Hadoop 2.7.2 伪分布式安装,安装jdk,免密匙登录,配置mapreduce,配置YARN.详细步骤如下: 1.0 安装JDK 1.1 查看是否安装了openjdk [l ...
- 安装部署Apache Hadoop (本地模式和伪分布式)
本节内容: Hadoop版本 安装部署Hadoop 一.Hadoop版本 1. Hadoop版本种类 目前Hadoop发行版非常多,有华为发行版.Intel发行版.Cloudera发行版(CDH)等, ...
- Hadoop + Hive + HBase + Kylin伪分布式安装
问题导读 1. Centos7如何安装配置? 2. linux网络配置如何进行? 3. linux环境下java 如何安装? 4. linux环境下SSH免密码登录如何配置? 5. linux环境下H ...
- Hadoop环境搭建 (伪分布式搭建)
一,Hadoop版本下载 建议下载:Hadoop2.5.0 (虽然是老版本,但是在企业级别中运用非常稳定,新版本虽然添加了些小功能但是版本稳定性有带与考核) 1.下载地址: hadoop.apache ...
随机推荐
- Runtime常见使用
一些语法 更改对象的类/获取对象的类 1234 CustomClass *class1 = [[CustomClass alloc]init];Class aclass =object_setClas ...
- 【pic+js+gh】免费高速图床方案
本文用到的工具或网站 PicGo jsdelivr github 速度对比 Github的速度: jsdelivrCDN的速度: 下载PicGo 首先进入PicGo的下载地址 选择最新版本下载,根据自 ...
- linux安装部署ftp图片服务器
1.安装http反向代理服务器.安装ftp文件传输组件vsftpd 详细安装及配置参见 https://blog.csdn.net/zhouym/article/details/100145964 2 ...
- tab 切换下划线跟随实现
HTML 结构如下: <ul> <li class="active">不可思议的CSS</li> <li>导航栏</li> ...
- CentOS下安装Anaconda和pycharm
前情提要:Linux越来越受大家喜爱,而在Linux中有一个社区很活跃的系统:那就是CentOS:而Anaconda又是几乎就一劳永逸的,你装了它之后基本上很多类库就不用再装了.然后就是pycharm ...
- vijos 1011 清帝之惑之顺治
背景 顺治帝福临,是清朝入关后的第一位皇帝.他是皇太极的第九子,生于崇德三年(1638)崇德八年八月二ten+six日在沈阳即位,改元顺治,在位18年.卒于顺治十八年(1661),终24岁. 顺治即位 ...
- Adobe Premiere Pro 2020破解教程
首先官网下载Adobe Creative Cloud,安装完之后使用它继续安装Pr.注意在安装之前,点击文件→首选项,先设置一下你的安装路径,没有设置则默认安装在C盘. 接着下载网上良心博主推荐的破解 ...
- 添加谷歌拓展程序 vue.js devtools过程中的问题
在用vue做项目过程中,需要用到vue.js devtools,在从github上面clone下来代码,然后再npm install ,过程报错,然后更新npm包也是会有问题,以下是install的问 ...
- 【colab pytorch】使用tensorboard可视化
import datetime import torch import torch.nn as nn import torch.nn.functional as F import torch.opti ...
- 小巧开源的 baresip VOIP 项目
Baresip is a modular SIP User-Agent with audio and video support https://github.com/alfredh/baresip ...