大数据之Hudi + Kylin的准实时数仓实现
问题导读:
1、数据库、数据仓库如何理解?
2、数据湖有什么用途?解决什么问题?
3、数据仓库的加载链路如何实现?
4、Hudi新一代数据湖项目有什么优势?
在近期的 Apache Kylin × Apache Hudi Meetup 直播上,Apache Kylin PMC Chair 史少锋和 Kyligence 解决方案工程师刘永恒就 Hudi + Kylin 的准实时数仓实现进行了介绍与演示。下文是分享现场的回顾。
我的分享主题是《基于 Hudi 和 Kylin 构建准实时、高性能数据仓库》,除了讲义介绍,还安排了 Demo 实操环节。下面是今天的日程:
<ignore_js_op>
01数据库、数据仓库
先从基本概念开始。我们都知道数据库和数据仓库,这两个概念都已经非常普遍了。数据库 Database,简称 DB,主要是做 OLTP(online transaction processing),也就是在线的交易,如增删改;数据仓库 Data Warehouse,简称 DW,主要是来做OLAP(online analytics processing),也就是在线数据分析。OLTP 的典型代表是 Oracle、MySQL,OLAP 则像 Teradata、Greenplum,近些年有 ClickHouse、Kylin 等。
<ignore_js_op>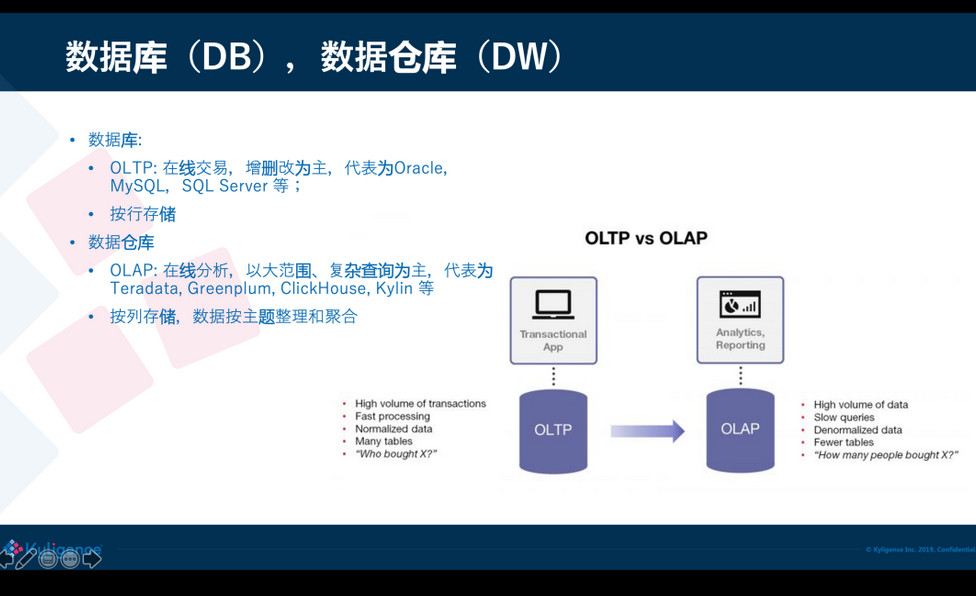
数据库和数据仓库两者在存储实现上是不一样的,数据库一般是按行存,这样可以按行来增加、修改;数据仓库是按列来存储,是为了分析的时候可以高效访问大量的数据,同时跳过不需要的列;这种存储差异导致两个系统难以统一,数据从数据库进入到数据仓库需要一条链路去处理。
02数据湖
近些年出现了数据湖(Data Lake)的概念,简单来说数据湖可以存储海量的、不同格式、汇总或者明细的数据,数据量可以达到 PB 到 EB 级别。企业不仅可以使用数据湖做分析,还可以用于未来的或未曾预判到的场景,因此需要的原始数据存储量是非常大的,而且模式是不可预知的。数据湖产品典型的像 Hadoop 就是早期的数据湖了,现在云上有很多的数据湖产品,比方 Amazon S3,Azure Blob store,阿里云 OSS,以及各家云厂商都有自己的存储服务。有了数据湖之后,企业大数据处理就有了一个基础平台,非常多的数据从源头收集后都会先落到数据湖上,基于数据湖再处理和加载到不同的分析库去。
<ignore_js_op>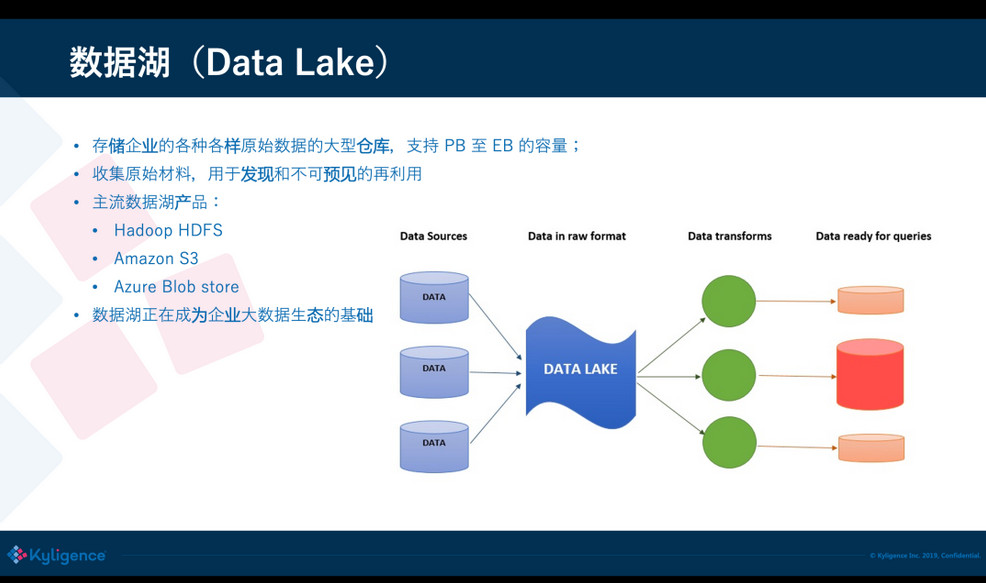
但是,数据湖开始设计主要是用于数据的存储,解决的是容量的水平扩展性、数据的持久性和高可用性,没有太多考虑数据的更新和删除。例如 HDFS 上通常是将文件分块(block)存储,一个 block 通常一两百兆;S3 同样也是类似,大的 block 可以节省管理开销,并且这些文件格式不一,通常没有高效的索引。如果要修改文件中的某一行记录,对于数据湖来说是非常难操作的,因为它不知道要修改的记录在哪个文件的哪个位置,它提供的方式仅仅是做批量替换,代价比较大。
<ignore_js_op>
另外一个极端的存储则是像 HBase 这样的,提供高效的主键索引,基于主键就可以做到非常快的插入、修改和删除;但是 HBase 在大范围读的效率比较低,因为它不是真正的列式存储。对于用户来说面临这么两个极端:一边是非常快的读存储(HDFS/S3),一边是非常快速的写存储;如果取中间的均衡比较困难。有的时候却需要有一种位于两者之间的方案:读的效率要高,但写开销不要那么大。
03数据仓库的加载链路
在有这么一个方案之前,我们怎样能够支撑到数据的修改从 OLTP 到 OLAP 之间准实时同步呢?通常大家会想到,通过 CDC/binlog 把修改增量发出来,但 binlog 怎么样进入到 Hive 中去呢?我们知道 Hive 很难很快地修改一条记录,修改只能把整张表或者整个分区重新写一遍。为了接收和准实时消费 binlog,可能需要引入一个只读的 Database 或 MPP 数据库,专门复制上游业务库的修改;然后再从这个中间的数据库导出数据到数据湖上,供下一个阶段使用。这个方案可以减少对业务库的压力和影响,但依然存在一些问题。
<ignore_js_op>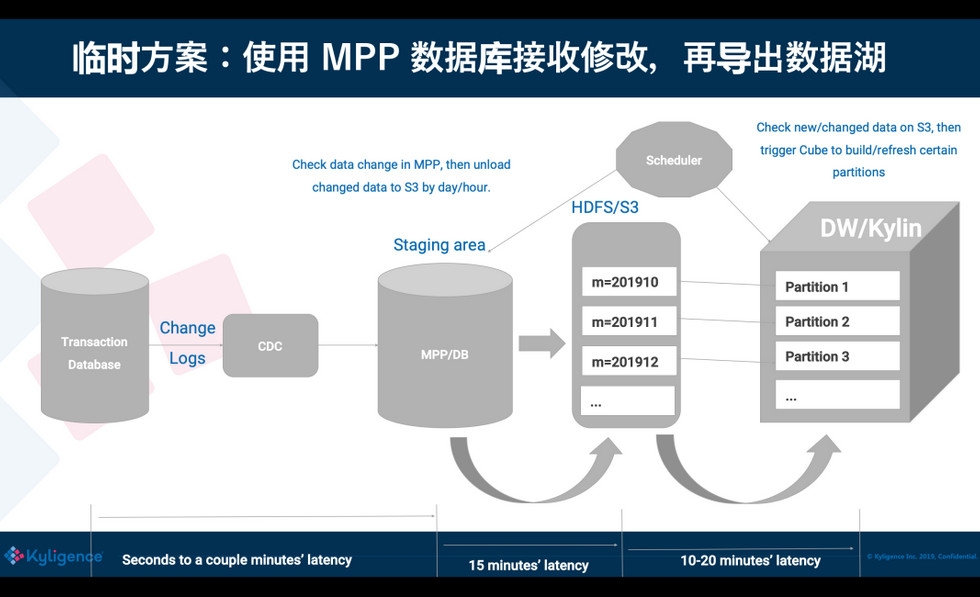
这里有一个生动的例子,是前不久从一个朋友那里看到的,各位可以感受一下。
<ignore_js_op>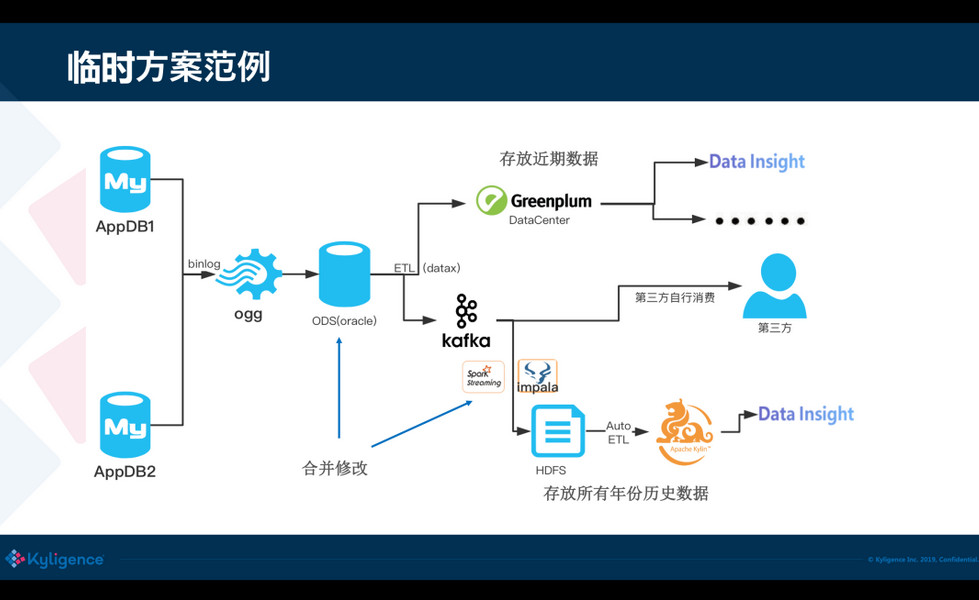
可以看到在过去的方案是非常复杂的,又要用 MPP 又要用数据湖,还要用 Kylin,在这中间数据频繁的被导出导入,浪费是非常严重的,而且维护成本高,容易出错,因为数据湖和数据库之间的文件格式往往还存在兼容性问题。
<ignore_js_op>
04Hudi:新一代数据湖项目
后来我们注意到 Hudi 这个项目,它的目的就是要在大数据集上支持 Upsert(update+insert)。Hudi 是在大数据存储上的一个数据集,可以将 Change Logs 通过 upsert 的方式合并进 Hudi;Hudi 对上可以暴露成一个普通的 Hive 或 Spark 的表,通过 API 或命令行可以获取到增量修改的信息,继续供下游消费;Hudi 还保管了修改历史,可以做时间旅行或回退;Hudi 内部有主键到文件级的索引,默认是记录到文件的布隆过滤器,高级的有存储到 HBase 索引提供更高的效率。
<ignore_js_op>
05基于 Hudi+Kylin 的准实时数仓实现
有了 Hudi 之后,可以跳过使用中间数据库或 MPP,直接微批次地增量消费 binlog,然后插入到 Hudi;Hudi 内的文件直接存放到 HDFS/S3 上,对用户来说存储成本可以大大降低,不需要使用昂贵的本地存储。Hudi 表可以暴露成一张 Hive 表,这对 Kylin 来说是非常友好,可以让 Kylin 把 Hudi 当一张普通表,从而无缝使用。Hudi 也让我们更容易地知道,从上次消费后有哪些 partition 发生了修改,这样 Kylin 只要刷新特定的 partition 就可以,从而端到端的数据入库的延迟可以降低到1小时以内。从 Uber 多年的经验来说,对大数据的统计分析,入库小于 1 小时在大多数场景下都是可以接受的。
<ignore_js_op>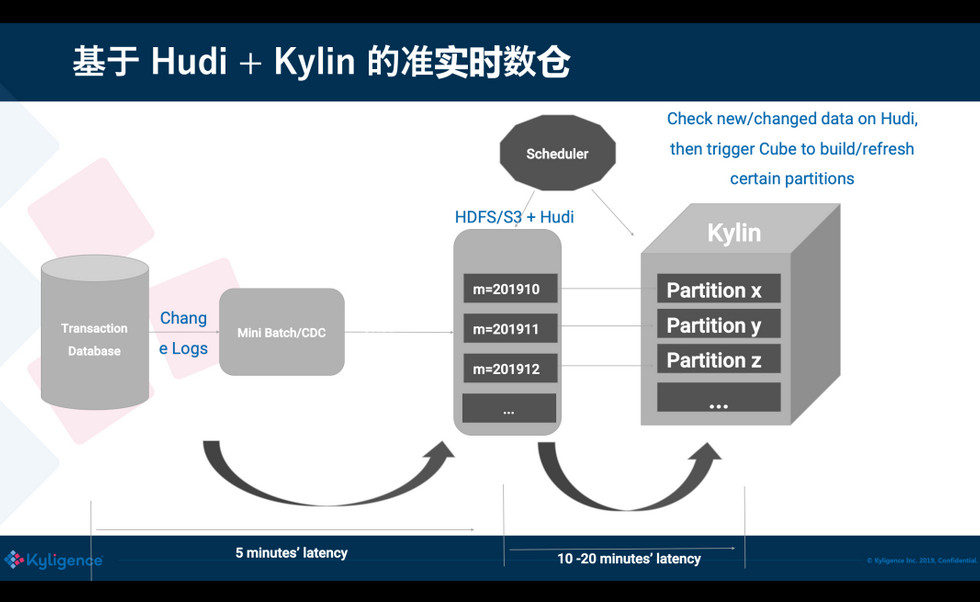
这里再总结一下,使用 Hudi 来做 DW 数据加载的前置存储给我们带来的诸多的好处:首先,它可以支持准实时的插入、修改和删除,对保护用户数据隐私来说是非常关键的(例如 GDPR );它还可以控制小文件,减少对 HDFS 的压力;第二,Hudi 提供了多种访问视图,可以根据需要去选择不同的视图;第三,Hudi 是基于开放生态的,存储格式使用 Parquet 和 Avro,目前主要是使用 Spark 来做数据操作,未来也可以扩展;支持多种查询引擎,所以在生态友好性上来说,Hudi 是远远优于另外几个竞品的。
<ignore_js_op>
06使用 Kyligence Cloud 现场演示
前面是一个基本的介绍,接下来我们做一个 Live Demo,用到 Kyligence Cloud(基于 Kylin 内核)这个云上的大数据分析平台;你可以一键在 Azure/AWS 上来启动分析集群,内置多种大数据组件来做建模加速,可直接从云上存储或云上的数据库抽取数据,提供了自动的监控和运维。
<ignore_js_op>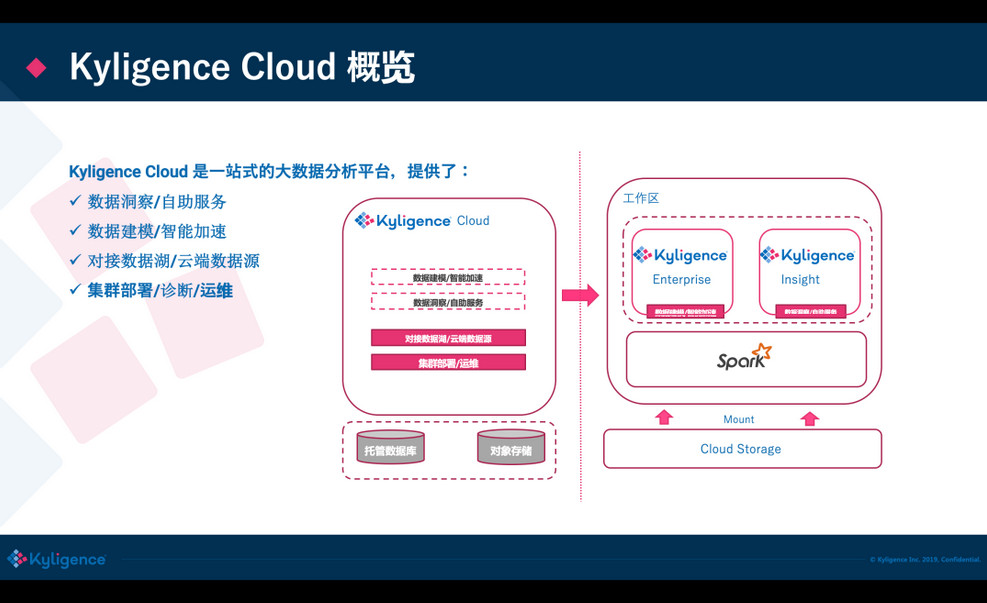
目前 Kyligence Cloud 已经不需要依赖 Hadoop 了,直接使用 VM 来做集群的计算力,内置了 Spark 做分布式计算,使用 S3 做数据存储;还集成了 Kylignece Insight 做可视化分析,底层可以对接常见的数据源,也包括 Hudi,在最新发布版的 Hudi 已经被集成进来了。
<ignore_js_op>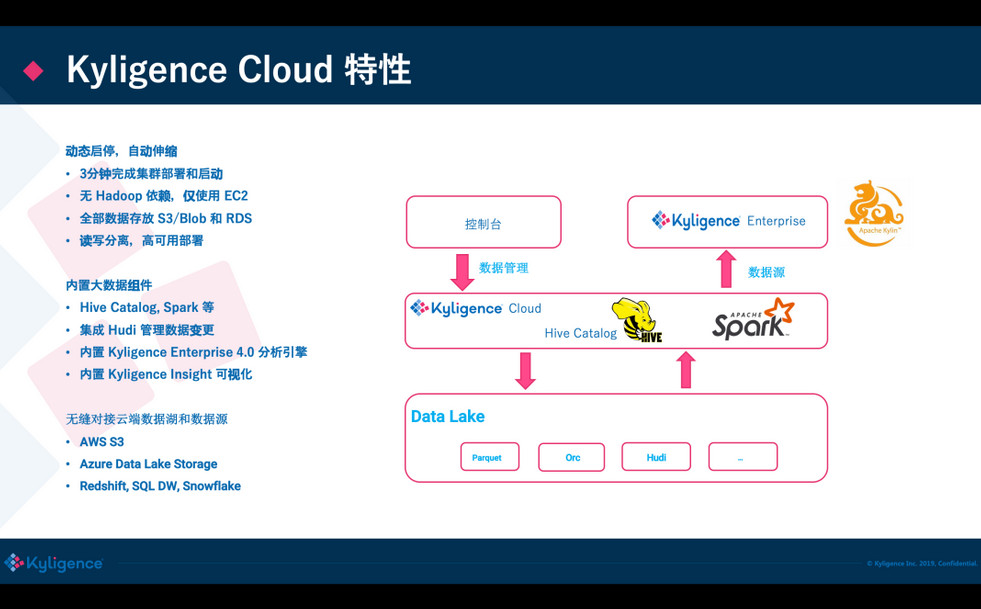
接下来,刘永恒将带来 Live Demo,他是从业务库到处数据加载到 Hudi 中,然后 Hudi 随后就可以从这当中来被访问。接下来他会演示做一些数据修改,再把这个数据修改合并到 Hudi,在 Hudi 中就可以看到这些数据的改变,接下来的时间就交给刘永恒。
<ignore_js_op>
大数据之Hudi + Kylin的准实时数仓实现的更多相关文章
- 基于Flink构建全场景实时数仓
目录: 一. 实时计算初期 二. 实时数仓建设 三. Lambda架构的实时数仓 四. Kappa架构的实时数仓 五. 流批结合的实时数仓 实时计算初期 虽然实时计算在最近几年才火起来,但是在早期也有 ...
- flink实时数仓从入门到实战
第一章.flink实时数仓入门 一.依赖 <!--Licensed to the Apache Software Foundation (ASF) under oneor more contri ...
- HBase实战 | 知乎实时数仓架构演进
https://mp.weixin.qq.com/s/hx-q13QteNvtXRpNsE5Y0A 作者 | 知乎数据工程团队编辑 | VincentAI 前线导读:“数据智能” (Data Inte ...
- 美团点评基于 Flink 的实时数仓建设实践
https://mp.weixin.qq.com/s?__biz=MjM5NjQ5MTI5OA==&mid=2651749037&idx=1&sn=4a448647b3dae5 ...
- 基于 Flink 的实时数仓生产实践
数据仓库的建设是“数据智能”必不可少的一环,也是大规模数据应用中必然面临的挑战.在智能商业中,数据的结果代表了用户反馈.获取数据的及时性尤为重要.快速获取数据反馈能够帮助公司更快地做出决策,更好地进行 ...
- (转)用Flink取代Spark Streaming!知乎实时数仓架构演进
转:https://mp.weixin.qq.com/s/e8lsGyl8oVtfg6HhXyIe4A AI 前线导读:“数据智能” (Data Intelligence) 有一个必须且基础的环节,就 ...
- 更强大的实时数仓构建能力!分析型数据库PostgreSQL 6.0新特性解读
阿里云 AnalyticDB for PostgreSQL 为采用MPP架构的分布式集群数据库,完备支持SQL 2003,部分兼容Oracle语法,支持PL/SQL存储过程,触发器,支持标准数据库事务 ...
- 基于 Kafka 的实时数仓在搜索的实践应用
一.概述 Apache Kafka 发展至今,已经是一个很成熟的消息队列组件了,也是大数据生态圈中不可或缺的一员.Apache Kafka 社区非常的活跃,通过社区成员不断的贡献代码和迭代项目,使得 ...
- Clickhouse实时数仓建设
1.概述 Clickhouse是一个开源的列式存储数据库,其主要场景用于在线分析处理查询(OLAP),能够使用SQL查询实时生成分析数据报告.今天,笔者就为大家介绍如何使用Clickhouse来构建实 ...
随机推荐
- Hyperledger Fabric开发(二):创建网络
运行fabric-samples项目中的一个例子:first-network,创建第一个网络(Building Your First Network). 该网络共有4个peer节点,划分为2个组织(o ...
- F. Machine Learning 带修端点莫队
F. Machine Learning time limit per test 4 seconds memory limit per test 512 megabytes input standard ...
- poj1386有向图判断是否存在欧拉回路或者欧拉路
有向图的图联通是指基图联通,也就是把有向图的边改成无向图然后看是否连通.判断联通可用dfs或者并查集. 题意就是给你n个由小写字母构成的字符串,问你能不能将这n个字符串连接起来,B能接在A后面的条 ...
- JavaScript实现单向链表结构
参考资料 一.什么是链表结构? 1.1.简介 链表和数组一样, 可以用于存储一系列的元素, 但是链表和数组的实现机制完全不同,链表中的元素在内存不是连续的空间,链表的每个元素由一个存储元素本身(数据) ...
- SVN强制添加备注
1.进入仓库project1/hooks目录,找到pre-commit.tmpl文件 cp pre-commit.tmpl pre-commit 2.编辑pre-commit文件, 将: $SVNLO ...
- 关于docker的常见使用命令
1. Docker的启动与停止 systemctl命令是系统服务管理器指令 启动docker: systemctl start docker 停止docker: systemctl stop dock ...
- Python __str__(self)
python 在打印一个实例化对象时,打印的是对象的地址,比如:<__main__.Workers object at 0x00000000255A9AC8> 而__str__(self) ...
- SpringBoot打包Docker镜像
构建spring boot项目 本地测试访问 打成jar包 在本地运行jar包测试 到这一步就证明jar包没问题 idea下载一个插件 在这创建一个Dockerfile文件 安装插件后会高亮显示. 在 ...
- parrot os 创建swap分区&swapon failed invalid argument解决
parrot os(不仅仅是debian系统),分区提示,查看系统格式为btrfs,需要注意的是btrfs无法添加swap分区,但是可以在5.0内核以上添加 以下命令,完成创建8g的swap分区 to ...
- vc程序设计--图形绘制1
利用绘图函数创建填充区.Windows通过使用当前画笔画一个图形的边界,然后用当前的刷子填充这个图形来创建-一个填充图形.共有三个填充图形,第一个是用深灰色画刷填充带圆角的矩形,第二个是采用亮 ...