spark-调节executor堆外内存
什么时候需要调节Executor的堆外内存大小?
当出现一下异常时:
shuffle file cannot find,executor lost、task lost,out of memory
出现这种问题的现象大致有这么两种情况:
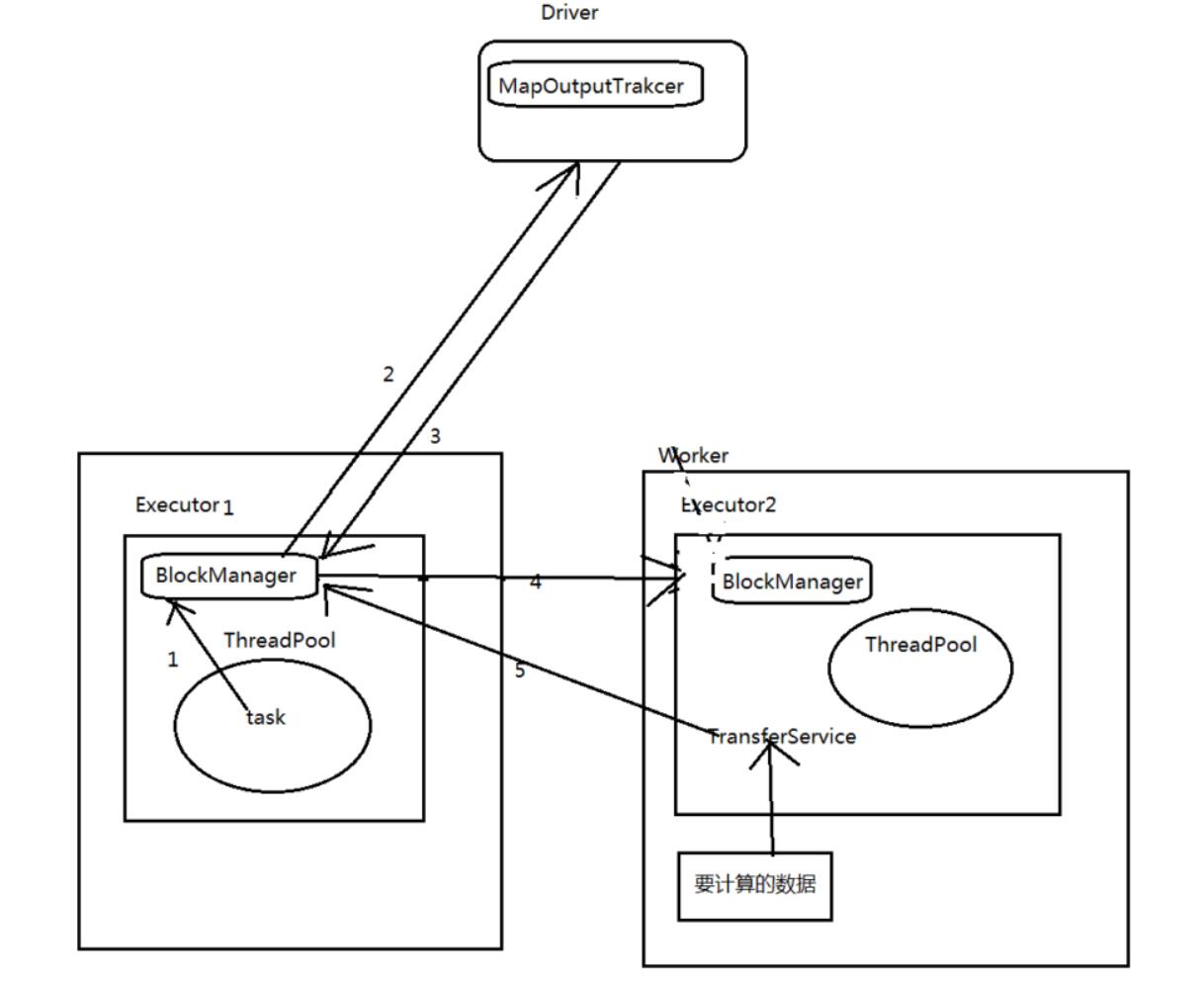
- Executor挂掉了,对应的Executor上面的block manager也挂掉了,找不到对应的shuffle map output文件,Reducer端不能够拉取数据
- Executor并没有挂掉,而是在拉取数据的过程出现了问题。
上述情况下,就可以去考虑调节一下executor的堆外内存。也许就可以避免报错;此外,有时,堆外内存调节的比较大的时候,对于性能来说,也会带来一定的提升。这个executor跑着跑着,突然内存不足了,堆外内存不足了,可能会OOM,挂掉。block manager也没有了,数据也丢失掉了。
如果此时,stage0的executor挂了,BlockManager也没有了;此时,stage1的executor的task,虽然通过
Driver的MapOutputTrakcer获取到了自己数据的地址;但是实际上去找对方的BlockManager获取数据的
时候,是获取不到的。
此时,就会在spark-submit运行作业(jar),client(standalone client、yarn client),在本机就会打印出log:shuffle output file not found。。。DAGScheduler,resubmitting task,一直会挂掉。反复挂掉几次,反复报错几次,整个spark作业就崩溃了
--conf spark.yarn.executor.memoryOverhead=2048
spark-submit脚本里面,去用--conf的方式,去添加配置;一定要注意!!!切记,
不是在你的spark作业代码中,用new SparkConf().set()这种方式去设置,不要这样去设置,是没有用的!
一定要在spark-submit脚本中去设置。spark.yarn.executor.memoryOverhead(看名字,顾名思义,针对的是基于yarn的提交模式)默认情况下,这个堆外内存上限默认是每一个executor的内存大小的10%;后来我们通常项目中,真正处理大数据的时候,这里都会出现问题,导致spark作业反复崩溃,无法运行;此时就会去调节这个参数,至少1G(1024M),甚至说2G、4G,通常这个参数调节上去以后,就会避免掉某些JVM OOM的异常问题,同时呢,会让整体spark作业的性能,得到较大的提升。
调节等待时长!!!
executor,优先从自己本地关联的BlockManager中获取某份数据
如果本地BlockManager没有的话,那么会通过TransferService,去远程连接其他节点上executor
的BlockManager去获取,尝试建立远程的网络连接,并且去拉取数据,task创建的对象特别大,特别多频繁的让JVM堆内存满溢,进行垃圾回收。正好碰到那个exeuctor的JVM在垃圾回收。
JVM调优:垃圾回收
处于垃圾回收过程中,所有的工作线程全部停止;相当于只要一旦进行垃圾回收,spark / executor停止工作,无法提供响应,此时呢,就会没有响应,无法建立网络连接,会卡住;ok,spark默认的网络连接的超时时长,是60s,如果卡住60s都无法建立连接的话,那么就宣告失败了。碰到一种情况,偶尔,偶尔,偶尔!!!没有规律!!!某某file。一串file id。uuid(dsfsfd-2342vs--sdf--sdfsd)。not found。file lost。这种情况下,很有可能是有那份数据的executor在jvm gc。所以拉取数据的时候,建立不了连接。然后超过默认60s以后,直接宣告失败。报错几次,几次都拉取不到数据的话,可能会导致spark作业的崩溃。也可能会导致DAGScheduler,反复提交几次stage。TaskScheduler,反复提交几次task。大大延长我们的spark作业的运行时间。
可以考虑调节连接的超时时长。
--conf spark.core.connection.ack.wait.timeout=300spark-submit脚本,切记,不是在new SparkConf().set()这种方式来设置的。spark.core.connection.ack.wait.timeout(spark core,connection,连接,ack,wait timeout,建立不上连接的时候,超时等待时长)调节这个值比较大以后,通常来说,可以避免部分的偶尔出现的某某文件拉取失败,某某文件lost掉了。。。
为什么在这里讲这两个参数呢?
因为比较实用,在真正处理大数据(不是几千万数据量、几百万数据量),几亿,几十亿,几百亿的时候。
很容易碰到executor堆外内存,以及gc引起的连接超时的问题。
file not found,executor lost,task lost。
调节上面两个参数,还是很有帮助的。
spark-调节executor堆外内存的更多相关文章
- 【Spark篇】---Spark调优之代码调优,数据本地化调优,内存调优,SparkShuffle调优,Executor的堆外内存调优
一.前述 Spark中调优大致分为以下几种 ,代码调优,数据本地化,内存调优,SparkShuffle调优,调节Executor的堆外内存. 二.具体 1.代码调优 1.避免创建重复的RDD,尽 ...
- Spark Shuffle 堆外内存溢出问题与解决(Shuffle通信原理)
Spark Shuffle 堆外内存溢出问题与解决(Shuffle通信原理) http://xiguada.org/spark-shuffle-direct-buffer-oom/ 问题描述 Spar ...
- Java堆外内存之一:堆外内存场景介绍(对象池VS堆外内存)
最近经常有人问我在Java中使用堆外(off heap)内存的好处与用途何在.我想其他面临几样选择的人应该也会对这个答案感兴趣吧. 堆外内存其实并无特别之处.线程栈,应用程序代码,NIO缓存用的都是堆 ...
- Spark在Executor上的内存分配
spark.serializer (default org.apache.spark.serializer.JavaSerializer ) 建议设置为 org.apache.spark.ser ...
- Netty堆外内存泄漏排查,这一篇全讲清楚了
上篇文章介绍了Netty内存模型原理,由于Netty在使用不当会导致堆外内存泄漏,网上关于这方面的资料比较少,所以写下这篇文章,专门介绍排查Netty堆外内存相关的知识点,诊断工具,以及排查思路提供参 ...
- Java堆外内存的使用
堆外内存的回收见HeapByteBuffer和DirectByteBuffer以及回收DirectByteBuffer 基本类型长度 在Java中有很多的基本类型,比如: byte,一个字节是8位bi ...
- Netty之Java堆外内存扫盲贴
Java的堆外内存本来是高贵而神秘的东西,只在一些缓存方案的收费企业版里出现.但自从用了Netty,就变成了天天打交道的事情,毕竟堆外内存能减少IO时的内存复制,不需要堆内存Buffer拷贝一份到直接 ...
- 堆外内存操作类ByteBuffer
本篇主要讲解如何使用直接内存(堆外内存),并按照下面的步骤进行说明: 1 相关背景-->读写操作-->关键属性-->读写实践-->扩展-->参考说明 希望对想使用直接内存 ...
- google-perftools 分析JAVA 堆外内存
google-perftools 分析JAVA 堆外内存 分类: j2se2011-08-25 21:48 3358人阅读 评论(4) 收藏 举报 javahbasehtml工具os 原文转自:htt ...
随机推荐
- 2019沈阳网赛树形dp
https://nanti.jisuanke.com/t/41403 2019沈阳网络赛D题 树形dp.一棵树,求任意两个点的距离之和.u-v和v-u算两次.两点之间的距离分为三类,模3等于0,1,2 ...
- 接入HikariCP遇到问题
老Tomcat项目在接入HikariCP时遇到报错: Caused by: java.lang.AbstractMethodError: com.mysql.jdbc.Connection.isVal ...
- Go_栈
1. 栈的介绍 2. 栈的应用 3. 栈入门 package main import ( "fmt" "errors" ) //使用数组来模拟一个栈的使用 ty ...
- web学习---html,js,php,mysql一个动态网页获取流程
使用bootstrap的cms模版系统搭建了一个信息管理系统.通过这个系统学习动态网页获取的工作流程. 抓包分析一个页面的数据请求流程如下图所示: 同样,对于需要向数据库插入数据,可以使用ajax接口 ...
- python练习:编写一个程序,要求用户输入10个整数,然后输出其中最大的奇数,如果用户没有输入奇数,则输出一个消息进行说明。
python练习:编写一个程序,要求用户输入10个整数,然后输出其中最大的奇数,如果用户没有输入奇数,则输出一个消息进行说明. 重难点:通过input函数输入的行消息为字符串格式,必须转换为整型,否则 ...
- confluence-工具安装
wiki 企业级的应用知识库,个人感觉还是很不错的,所以自己本地也搭一个玩玩: 1.下载confluence wget https://downloads.atlassian.com/software ...
- 安装Anaconda3时出现conda不是内部或者外部命令
在win10,64位,python版本为3.7的环境下安装anaconda3的时候,无法在命令行执行conda命令,一直提示conda不是内部或者外部命令,参考网上的修改环境变量,修改完后还是没有用, ...
- Java_Habse_add
import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.hb ...
- C# FormData 文件太大报错404 Form表单上传大文件,无法进入后台Action,页面提示404.
web.config中添加如下节点 <system.webServer> <security> <requestFiltering > &l ...
- DAG 计数
以下方法都是按照这个套路: 考虑一个不一定连通的 DAG ,你枚举一些零度点(拓扑序第一层)集合 \(S\),这些点之间不能连边,这些点跟剩下点(点集为 \(T\),\(|S| \cup |T| = ...