环境篇:Kylin3.0.1集成CDH6.2.0
环境篇:Kylin3.0.1集成CDH6.2.0

Kylin是什么?
Apache Kylin™是一个开源的、分布式的分析型数据仓库,提供Hadoop/Spark 之上的 SQL 查询接口及多维分析(OLAP)能力以支持超大规模数据,最初由 eBay 开发并贡献至开源社区。它能在亚秒内查询巨大的表。
Apache Kylin™ 令使用者仅需三步,即可实现超大数据集上的亚秒级查询。
- 定义数据集上的一个星形或雪花形模型
- 在定义的数据表上构建cube
- 使用标准 SQL 通过 ODBC、JDBC 或 RESTFUL API 进行查询,仅需亚秒级响应时间即可获得查询结果

如果没有Kylin
大数据在数据积累后,需要计算,而数据越多,算力越差,内存需求也越高,而这些对于Kylin影响不大,大数据中硬盘往往比内存要更便宜,Kylin通过与计算的形式,以空间换时间,亚秒级的响应让人们爱不释手。
https://archive.apache.org/dist/zeppelin/zeppelin-0.8.2/
1 Kylin架构
Kylin 提供与多种数据可视化工具的整合能力,如 Tableau,PowerBI 等,令用户可以使用 BI 工具对 Hadoop 数据进行分析
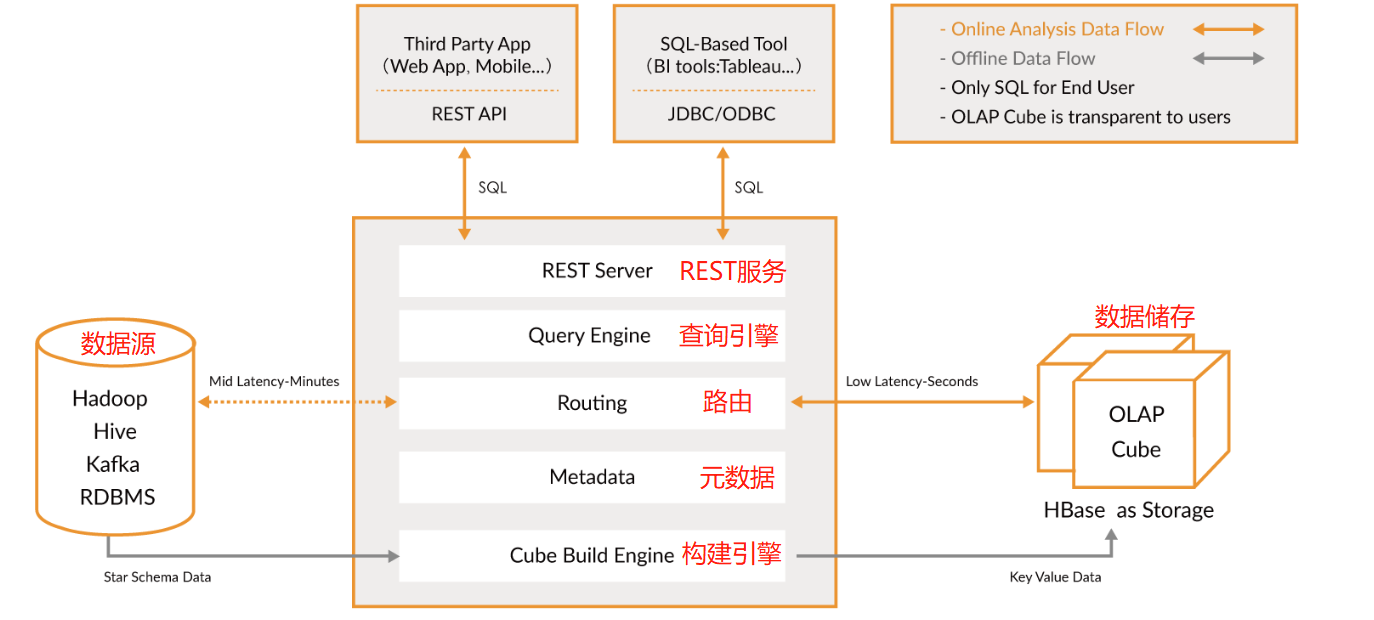
- REST Server REST Server
是一套面向应用程序开发的入口点,旨在实现针对 Kylin 平台的应用开发 工作。 此类应用程序可以提供查询、获取结果、触发 cube 构建任务、获取元数据以及获取 用户权限等等。另外可以通过 Restful 接口实现 SQL 查询。
- 查询引擎(Query Engine)
当 cube 准备就绪后,查询引擎就能够获取并解析用户查询。它随后会与系统中的其它 组件进行交互,从而向用户返回对应的结果。
- 路由器(Routing)
在最初设计时曾考虑过将 Kylin 不能执行的查询引导去 Hive 中继续执行,但在实践后 发现 Hive 与 Kylin 的速度差异过大,导致用户无法对查询的速度有一致的期望,很可能大 多数查询几秒内就返回结果了,而有些查询则要等几分钟到几十分钟,因此体验非常糟糕。 最后这个路由功能在发行版中默认关闭。
- 元数据管理工具(Metadata)
Kylin 是一款元数据驱动型应用程序。元数据管理工具是一大关键性组件,用于对保存 在 Kylin 当中的所有元数据进行管理,其中包括最为重要的 cube 元数据。其它全部组件的 正常运作都需以元数据管理工具为基础。 Kylin 的元数据存储在 hbase 中。
- 任务引擎(Cube Build Engine)
这套引擎的设计目的在于处理所有离线任务,其中包括 shell 脚本、Java API 以及 MapReduce 任务等等。任务引擎对 Kylin 当中的全部任务加以管理与协调,从而确保每一项任务 都能得到切实执行并解决其间出现的故障。
2 Kylin安装
- Hadoop: 2.7+, 3.1+ (since v2.5)
- Hive: 0.13 - 1.2.1+
- HBase: 1.1+, 2.0 (since v2.5)
- Spark (optional) 2.3.0+
- Kafka (optional) 1.0.0+ (since v2.5)
- JDK: 1.8+ (since v2.5)
- OS: Linux only, CentOS 6.5+ or Ubuntu 16.0.4+
2.1 修改环境变量
vim /etc/profile
#>>>注意地址指定为自己的
#kylin
export KYLIN_HOME=/usr/local/src/kylin/apache-kylin-3.0.1-bin-cdh60
export PATH=$PATH:$KYLIN_HOME/bin
#cdh
export CDH_HOME=/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373
#hadoop
export HADOOP_HOME=${CDH_HOME}/lib/hadoop
export HADOOP_DIR=${HADOOP_HOME}
export HADOOP_CLASSPATH=${HADOOP_HOME}
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
#hbase
export HBASE_HOME=${CDH_HOME}/lib/hbase
export PATH=$PATH:$HBASE_HOME/bin
#hive
export HIVE_HOME=${CDH_HOME}/lib/hive
export PATH=$PATH:$HIVE_HOME/bin
#spark
export SPARK_HOME=${CDH_HOME}/lib/spark
export PATH=$PATH:$SPARK_HOME/bin
#kafka
export KAFKA_HOME=${CDH_HOME}/lib/kafka
export PATH=$PATH:$KAFKA_HOME/bin
#<<<
source /etc/profile
2.2 修改hdfs用户权限
usermod -s /bin/bash hdfs
su hdfs
hdfs dfs -mkdir /kylin
hdfs dfs -chmod a+rwx /kylin
su
2.3 上传安装包解压
mkdir /usr/local/src/kylin
cd /usr/local/src/kylin
tar -zxvf apache-kylin-3.0.1-bin-cdh60.tar.gz
cd /usr/local/src/kylin/apache-kylin-3.0.1-bin-cdh60
2.4 Java兼容hbase
- hbase 所有节点
在CLASSPATH=${CLASSPATH}:$JAVA_HOME/lib/tools.jar后添加
vim /opt/cloudera/parcels/CDH/lib/hbase/bin/hbase
:/opt/cloudera/parcels/CDH/lib/hbase/lib/*
- Kylin节点添加jar包
cp /opt/cloudera/cm/common_jars/commons-configuration-1.9.cf57559743f64f0b3a504aba449c9649.jar /usr/local/src/kylin/apache-kylin-3.0.1-bin-cdh60/tomcat/lib
这2步不做会引起 Could not find or load main class org.apache.hadoop.hbase.util.GetJavaProperty
2.5 启动停止
./bin/kylin.sh start
#停止 ./bin/kylin.sh stop
2.6 web页面
访问端口
环境篇:Kylin3.0.1集成CDH6.2.0的更多相关文章
- Red5 1.0.0RC1 集成到tomcat6.0.35中运行&部署新的red5项目到tomcat中
1.下载red5-war-1.0-RC1.zip 解压之得到 ROOT.war 文件. 2.处理tomcat. 下载apache-tomcat-6.0.35-windows-x86.zip包,解压到你 ...
- netcore3.0 webapi集成Swagger 5.0,Swagger使用
Swagger使用 1.描述 Swagger 是一个规范和完整的框架,用于生成.描述.调用和可视化 RESTful 风格的 Web 服务. 作用: 1.接口的文档在线自动生成. 2.功能测试 本文转自 ...
- netcore3.0 webapi集成Swagger 5.0
在项目中引用Swashbuckle.AspNetCore和Swashbuckle.AspNetCore.Filters两个dll,在Startup中的ConfigureServices相关配置代码如下 ...
- 环境篇:Atlas2.0.0兼容CDH6.2.0部署
环境篇:Atlas2.0.0兼容CDH6.2.0部署 Atlas 是什么? Atlas是一组可扩展和可扩展的核心基础治理服务,使企业能够有效地满足Hadoop中的合规性要求,并允许与整个企业数据生态系 ...
- 环境篇:Atlas2.1.0兼容CDH6.3.2部署
环境篇:Atlas2.1.0兼容CDH6.3.2部署 Atlas 是什么? Atlas是一组可扩展和可扩展的核心基础治理服务,使企业能够有效地满足Hadoop中的合规性要求,并允许与整个企业数据生态系 ...
- 环境篇:CM+CDH6.3.2环境搭建(全网最全)
环境篇:CM+CDH6.3.2环境搭建(全网最全) 一 环境准备 1.1 三台虚拟机准备 Master( 32g内存 + 100g硬盘 + 4cpu + 每个cpu2核) 2台Slave( 12g内存 ...
- 热修复框架Tinker的从0到集成之路(转)
转自:http://blog.csdn.net/lisdye2/article/details/54411727 热修复框架Tinker的从0到集成之路 转载请标明出处: http://blog.cs ...
- 环境篇:Zeppelin
环境篇:Zeppelin Zeppelin 是什么 Apache Zeppelin 是一个让交互式数据分析变得可行的基于网页的开源框架.Zeppelin提供了数据分析.数据可视化等功能. Zeppel ...
- 环境篇:呕心沥血@CDH线上调优
环境篇:呕心沥血@线上调优 为什么出这篇文章? 近期有很多公司开始引入大数据,由于各方资源有限,并不能合理分配服务器资源,和服务器选型,小叶这里将工作中的总结出来,给新入行的小伙伴带个方向,不敢说一定 ...
随机推荐
- Python——详解__slots__,property和私有方法
本文始发于个人公众号:TechFlow,原创不易,求个关注 今天是Python专题的第11篇文章,我们来聊聊面向对象的一些进阶使用. __slots__ 如果你看过github当中一些大牛的代码,你会 ...
- mac上安装htop
对于经常在mac上使用top命令的童鞋来说,htop会是一个更加好看和更加好用的命令,下面就是在mac上安装htop的步骤 1.首先去htop官网去下载,我下的是最新的2.2.0版本,网址是https ...
- python_ck01(虚拟环境管理)
拖拖拉拉的毛病还是依旧如初... 断断续续坚持三天总算把虚拟环境管理部分的内容给看完了. 对三天的知识点进行梳理,方便以后回顾. ①虚拟环境安装 用pip install + 包名的方式安装,涉及到的 ...
- JavaScript思维导图很全(W3C上的!!!!很重要快来看!)
- 今天我们来谈谈jquery,
---恢复内容开始--- 首先从jquery的两种写法开始: 1.$(document).ready(function(){}); 首先我们的jquery是用来操作DOM节点的,所以必须等到文档加载完 ...
- Linux学习笔记(一)目录处理命令
目录处理命令 ls cd mkdir rmdir tree ls 英文原意: list 功能: 显示目录文件 语法: ls 选项[-ald] [文件或目录] ls -a 显示所有文件,包括隐藏文件 l ...
- Golang交付至Kubernetes
目录 0.前言 1.Go服务构建 1.1.制作Go服务镜像底包 1.2.制作slave基础镜像底包 1.2.1.Golang镜像 1.2.2.Docker镜像 2.创建golang流水线 3.流水线构 ...
- pytorch seq2seq闲聊机器人加入attention机制
attention.py """ 实现attention """ import torch import torch.nn as nn im ...
- python os模块判断文件是否存在
import os os.path.exists(test_file.txt)
- Jmeter与LoadRunner的比较
一.与Loadrunner的比较相似点 1.Jmeter的架构跟loadrunner原理一样, 都是通过中间代理,监控&收集并发客户端发现的指令,把他们生成脚本,再发送到应用服务器,再监控服务 ...