python3下scrapy爬虫(第四卷:初步抓取网页内容之抓取网页里的指定数据延展方法)
上卷中我运用创建HtmlXPathSelector 对象进行抓取数据:
现在咱们再试一下其他的方法,先试一下我得最爱XPATH
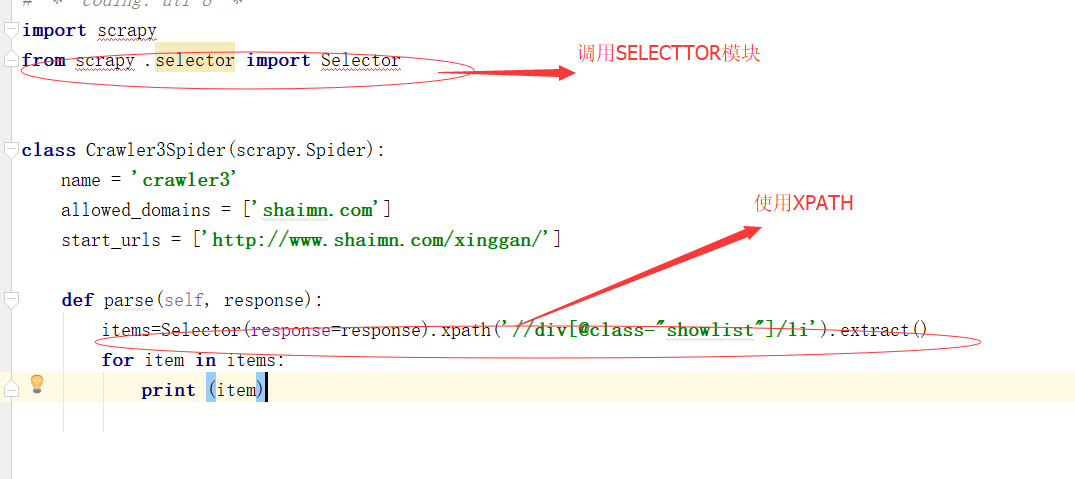
看下结果:
直接打印出结果了

我现在就正常拼下路径 只求打印结果:

现在再说说 最常见的正则的用法说实话你要是初学者用很正常 我觉得正则不是特别好,但是还是要会的,它引入的模块与XPATH一样只需稍微修改些代码就行
使用方式分为两种
第一种:
直接对抓取结果进行匹配

第二种:
选择器内匹配
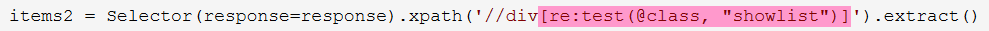
python3下scrapy爬虫(第四卷:初步抓取网页内容之抓取网页里的指定数据延展方法)的更多相关文章
- python3下scrapy爬虫(第二卷:初步抓取网页内容之直接抓取网页)
上一卷中介绍了安装过程,现在我们开始使用这个神奇的框架 跟很多博主一样我也先选择一个非常好爬取的网站作为最初案例,那么我先用屌丝必备网站http://www.shaimn.com/xinggan/作为 ...
- python3下scrapy爬虫(第六卷:利用cookie模拟登陆抓取个人中心页面)
之前我们爬取的都是那些无需登录就要可以使用的网站但是当我们想爬取自己或他人的个人中心时就需要做登录,一般进入登录页面有两种 ,一个是独立页面登陆,另一个是弹窗,我们先不管验证码登陆的问题 ,现在试一下 ...
- python3下scrapy爬虫(第三卷:初步抓取网页内容之抓取网页里的指定数据)
上一卷中我们抓取了网页的所有内容,现在我们抓取下网页的图片名称以及连接 现在我再新建个爬虫文件,名称设置为crawler2 做爬虫的朋友应该知道,网页里的数据都是用文本或者块级标签包裹着的,scrap ...
- python3下scrapy爬虫(第五卷:初步抓取网页内容之scrapy全面应用)
现在爬取http://category.dangdang.com/pg1-cid4008149.html网址上的商品价格,名称,评价数量 先准备下下数据:商品名,商品链接,评价数量 第一步:在item ...
- python3下scrapy爬虫(第一卷:安装问题)
一般爬虫都是用urllib包,requests包 配合正则.beautifulsoup等包混合使用,达到爬虫效果,不过有框架谁还用原生啊,现在我们来谈谈SCRAPY框架爬虫, 现在python3的兼容 ...
- python3下scrapy爬虫(第十四卷:scrapy+scrapy_redis+scrapyd打造分布式爬虫之执行)
现在我们现在一个分机上引入一个SCRAPY的爬虫项目,要求数据存储在MONGODB中 现在我们需要在SETTING.PY设置我们的爬虫文件 再添加PIPELINE 注释掉的原因是爬虫执行完后,和本地存 ...
- python3下scrapy爬虫(第十三卷:scrapy+scrapy_redis+scrapyd打造分布式爬虫之配置)
之前我们的爬虫都是单机爬取,也是单机维护REQUEST队列, 看一下单机的流程图: 一台主机控制一个队列,现在我要把它放在多机执行,会产生一个事情就是做重复的爬取,毫无意义,所以分布式爬虫的第一个难点 ...
- python3下scrapy爬虫(第十二卷:解决scrapy数据存储大量数据时阻塞问题)
之前我们使用scrapy爬取数据,用的存储方式是直接引入PYMYSQL,或者MYSQLDB,案例中数据量并不大,这种数据存储方式属于同步过程,也就是上一条语句执行完才能执行下一条语句,当数据量变大时, ...
- python3下scrapy爬虫(第十一卷:scrapy数据存储进mongodb)
说起python爬虫数据存储就不得不说到mongodb,现在我们来试一下scrapy操作mongodb 首先开启mongodb mongod --dbpath=D:\mongodb\db 开启服务后就 ...
随机推荐
- 2. react 编程实践 俄罗斯方块-环境搭建
1. 创建 demo 目录 mkdir demo 2. 初始化应用 npm init 工程信息 package name : tetris-class-demo version: descriptio ...
- 201409-2 画图 Java
思路: 法1:计算每个矩形的小方块,去掉重复的 法2:二维数组,需要涂色就置flag为1,最后遍历输出,不会有重复计算 import java.util.Scanner; public class M ...
- 基于redis实现锁控制
多数据源 数据源1为锁控制,数据源2自定义,可用于存储. 锁:当出现并发的时候为了保证数据的一致性,不会出现并发问题,假设,用户1修改一条信息,用户2也同时修改,会按照顺序覆盖自修改的值,为了避免这种
- 2×c列联表|多组比例简式|卡方检验|χ2检验与连续型资料假设检验
第四章 χ2检验 χ2检验与连续型资料假设检验的区别? 卡方检验的假设检验是什么? 理论值等于实际值 何条件下卡方检验的需要矫正?如何矫正? 卡方检验的自由度如何计算? Df=k-1而不是n-1 卡方 ...
- MySQL--INSERT INTO ... ON DUPLICATE KEY UPDATE ...
转自:https://my.oschina.net/iceman/blog/53735 如果在INSERT语句末尾指定了ON DUPLICATE KEY UPDATE,并且插入行后会导致在一个UNIQ ...
- 决策树分类回归,ID3,c4.5,CART,及其Python代码
决策树模型 内部节点表示一个特征或者属性,叶子结点表示一个类.决策树工作时,从根节点开始,对实例的每个特征进行测试,根据测试结果,将实例分配到其子节点中,这时的每一个子节点对应着特征的一个取值,如此递 ...
- 几个Java基础题
1.java中线程能不能重复start t1.start(); System.out.println("ssss"); t1.start(); 答:第一 ...
- 20190221 beautiful soup 入门
beautiful soup 入门 Beautiful Soup 是 python 的一个库,最主要的功能是从网页抓取数据. Beautiful Soup 自动将输入文档转换为 Unicode 编码, ...
- Opencv笔记(十九)——直方图(一)
直方图概念 图像的构成是有像素点构成的,每个像素点的值代表着该点的颜色(灰度图或者彩色图).所谓直方图就是对图像的中的这些像素点的值进行统计,得到一个统一的整体的灰度概念.一般情况下直方图都是灰度图像 ...
- [GX/GZOI2019]宝牌一大堆(DP)
出这种麻将题有意思吗? 乍看很难实则很水,就是麻将式DP,想必大家很熟悉了吧.首先把“国士无双”和“七对子”两种牌型判掉,然后观察牌胡的形式,发现每多一张牌实际上就是把1个面子变成1个杠子,然后可以直 ...