一只简单的网络爬虫(基于linux C/C++)————线程相关
爬虫里面采用了多线程的方式处理多个任务,以便支持并发的处理,把主函数那边算一个线程的话,加上一个DNS解析的线程,以及我们可以设置的max_job_num值,最多使用了1+1+max_job_num个线程。相关的线程封装如下:
创建线程
int create_thread(void *(*start_func)(void *), void * arg, pthread_t *pid, pthread_attr_t * pattr)
{
pthread_attr_t attr;
pthread_t pt;
if (pattr == NULL)
{
pattr = &attr;
pthread_attr_init(pattr);//pthread_attr_init函数的作用初始化一个线程对象的属性,需要用pthread_attr_destroy函数对其去除初始化
pthread_attr_setstacksize(pattr, 1024*1024);//设置线程堆栈的大小
pthread_attr_setdetachstate(pattr, PTHREAD_CREATE_DETACHED);//设置线程分离
}
if (pid == NULL)
pid = &pt;
int rv = pthread_create(pid, pattr, start_func, arg);//创建线程
pthread_attr_destroy(pattr);//取出线程对象属性的初始化
return rv;
}
主要是使用了pthread_attr_init函数对线程的属性做了一些设置
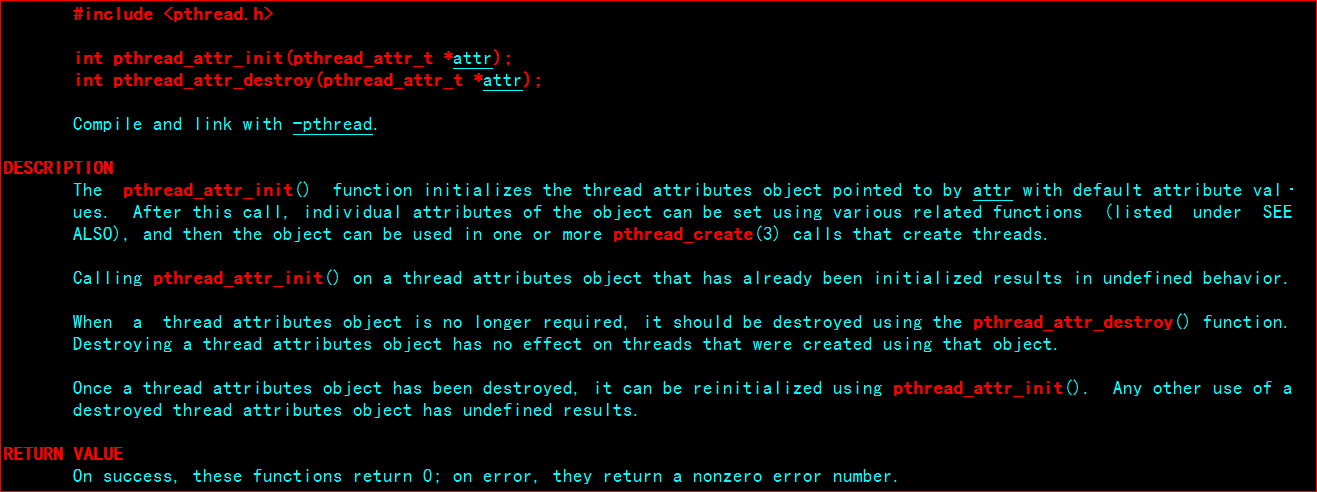
Posix线程中的线程属性是一个pthread_attr_t类型,主要包括scope属性、detach属性、堆栈地址、堆栈大小、优先级。在pthread_create中,把第二个参数设置为NULL的话,将采用默认的属性配置。
pthread_attr_t的主要属性的意义如下:
__detachstate,表示新线程是否与进程中其他线程脱离同步, 如果设置为PTHREAD_CREATE_DETACHED 则新线程不能用pthread_join()来同步,且在退出时自行释放所占用的资源。缺省为PTHREAD_CREATE_JOINABLE状态。这个属性也可以在线程创建并运行以后用pthread_detach()来设置,而一旦设置为PTHREAD_CREATE_DETACH状态(不论是创建时设置还是运行时设置)则不能再恢复到PTHREAD_CREATE_JOINABLE状态。
__schedpolicy,表示新线程的调度策略,主要包括SCHED_OTHER(正常、非实时)、SCHED_RR(实时、轮转法)和SCHED_FIFO(实时、先入先出)三种,缺省为SCHED_OTHER,后两种调度策略仅对超级用户有效。运行时可以用过pthread_setschedparam()来改变。
__schedparam,一个struct sched_param结构,目前仅有一个sched_priority整型变量表示线程的运行优先级。这个参数仅当调度策略为实时(即SCHED_RR或SCHED_FIFO)时才有效,并可以在运行时通过pthread_setschedparam()函数来改变,缺省为0。
__inheritsched,有两种值可供选择:PTHREAD_EXPLICIT_SCHED和PTHREAD_INHERIT_SCHED,前者表示新线程使用显式指定调度策略和调度参数(即attr中的值),而后者表示继承调用者线程的值。缺省为PTHREAD_EXPLICIT_SCHED。
__scope,表示线程间竞争CPU的范围,也就是说线程优先级的有效范围。POSIX的标准中定义了两个值:PTHREAD_SCOPE_SYSTEM和PTHREAD_SCOPE_PROCESS,前者表示与系统中所有线程一起竞争CPU时间,后者表示仅与同进程中的线程竞争CPU。目前LinuxThreads仅实现了PTHREAD_SCOPE_SYSTEM一值。
为了设置这些属性,POSIX定义了一系列属性设置函数,包括pthread_attr_init()、pthread_attr_destroy()和与各个属性相关的pthread_attr_getXXX/pthread_attr_setXXX函数。如下图:

主要的函数如下:
1、pthread_attr_init
功能: 对线程属性变量的初始化。
头文件: pthread.h
函数原型: int pthread_attr_init (pthread_attr_t* attr);
函数传入值:attr:线程属性。
函数返回值:成功: 0
失败: -1
2、pthread_attr_setscope
功能: 设置线程 __scope 属性。scope属性表示线程间竞争CPU的范围,也就是说线程优先级的有效范围。POSIX的标准中定义了两个值:PTHREAD_SCOPE_SYSTEM和PTHREAD_SCOPE_PROCESS,前者表示与系统中所有线程一起竞争CPU时间,后者表示仅与同进程中的线程竞争CPU。默认为PTHREAD_SCOPE_PROCESS。目前LinuxThreads仅实现了PTHREAD_SCOPE_SYSTEM一值。
头文件: pthread.h
函数原型: int pthread_attr_setscope (pthread_attr_t* attr, int scope);
函数传入值:attr: 线程属性。
scope:PTHREAD_SCOPE_SYSTEM,表示与系统中所有线程一起竞争CPU时间,
PTHREAD_SCOPE_PROCESS,表示仅与同进程中的线程竞争CPU
函数返回值:成功: 0
失败: -1
3、pthread_attr_setdetachstate
功能: 设置线程detachstate属性。该表示新线程是否与进程中其他线程脱离同步,如果设置为PTHREAD_CREATE_DETACHED则新线程不能用pthread_join()来同步,且在退出时自行释放所占用的资源。缺省为PTHREAD_CREATE_JOINABLE状态。这个属性也可以在线程创建并运行以后用pthread_detach()来设置,而一旦设置为PTHREAD_CREATE_DETACH状态(不论是创建时设置还是运行时设置)则不能再恢复到PTHREAD_CREATE_JOINABLE状态。
头文件: phread.h
函数原型: int pthread_attr_setdetachstate (pthread_attr_t* attr, int detachstate);
函数传入值:attr:线程属性。
detachstate:PTHREAD_CREATE_DETACHED,不能用pthread_join()来同步,且在退出时自行释放所占用的资源
PTHREAD_CREATE_JOINABLE,能用pthread_join()来同步
函数返回值:成功: 0
失败: -1
4、pthread_attr_setschedparam
功能: 设置线程schedparam属性,即调用的优先级。
头文件: pthread.h
函数原型: int pthread_attr_setschedparam (pthread_attr_t* attr, struct sched_param* param);
函数传入值:attr:线程属性。
param:线程优先级。一个struct sched_param结构,目前仅有一个sched_priority整型变量表示线程的运行优先级。这个参数仅当调度策略为实时(即SCHED_RR或SCHED_FIFO)时才有效,并可以在运行时通过pthread_setschedparam()函数来改变,缺省为0
函数返回值:成功: 0
失败: -1
5、pthread_attr_getschedparam
功能: 得到线程优先级。
头文件: pthread.h
函数原型: int pthread_attr_getschedparam (pthread_attr_t* attr, struct sched_param* param);
函数传入值:attr:线程属性;
param:线程优先级;
函数返回值:成功: 0
失败: -1
具体的函数可以通过man查得,下面谈谈pthread_attr_setdetachstate
在任何一个时间点上,线程是可结合的(joinable),或者是分离的(detached)。一个可结合的线程能够被其他线程收回其资源和杀死;在被其他线程回收之前,它的存储器资源(如栈)是不释放的。相反,一个分离的线程是不能被其他线程回收或杀死的,它的存储器资源在它终止时由系统自动释放。
线程的分离状态决定一个线程以什么样的方式来终止自己。在默认情况下线程是非分离状态的,这种情况下,原有的线程等待创建的线程结束。只有当pthread_join()函数返回时,创建的线程才算终止,才能释放自己占用的系统资源。而分离线程不是这样子的,它没有被其他的线程所等待,自己运行结束了,线程也就终止了,马上释放系统资源。程序员应该根据自己的需要,选择适当的分离状态。所以如果我们在创建线程时就知道不需要了解线程的终止状态,则可以pthread_attr_t结构中的detachstate线程属性,让线程以分离状态启动。
爬虫里使用的是线程分离。
线程(任务)开始
void begin_thread()
{
SPIDER_LOG(SPIDER_LEVEL_DEBUG, "Begin Thread %lu", pthread_self());//获得线程自身的ID
}该函数只是简单的打印一下自身id日志
线程(任务)结束
下面这个函数结束了一个任务,其实线程是自动结束的,因为之前设置了线程分离的属性,在线程函数执行结束后就会终止并释放资源,并没有使用pthread_join()函数,因此该函数其实只是打印下标志说明线程结束,并且如果在事件数允许的情况下调用attach_epoll_task(),该函数执行了发送请求,注册epoll事件等操作,然后又根据epoll_wait函数返回的事件数又创建若干线程来执行任务,如果事件数达到设置的上限,则会在其他线程结束的时候再创建新的线程来处理任务
//结束一个任务,只是结束任务, 因为设置了线程分离,所以回调函数执行结束后便会结束该线程
//但是如果任务数允许,则会创建新的任务
void end_thread()
{
pthread_mutex_lock(&gctn_lock);
int left = g_conf->max_job_num - (--g_cur_thread_num);//刷新剩下的任务数
if (left == 1)
{//创建一些新的任务,主函数那里只是处理原来的那些url
// can start one thread
attach_epoll_task();//该函数执行了发送请求,注册epoll事件等操作
}
else if (left > 1)
{
// can start two thread
attach_epoll_task();
attach_epoll_task();
}
else
{//要先等待其他的事件退出,才能开启新的任务
// have reached g_conf->max_job_num , do nothing
}
//打印当前线程的id以及剩下的任务数
SPIDER_LOG(SPIDER_LEVEL_DEBUG, "End Thread %lu, cur_thread_num=%d", pthread_self(), g_cur_thread_num);
pthread_mutex_unlock(&gctn_lock);
}
因此该爬虫没有使用线程池,而是每次创建新的线程处理事件,然后事件函数执行完毕自动结束线程,循环这个过程。
线程属性的相关知识可以参考这里
一只简单的网络爬虫(基于linux C/C++)————线程相关的更多相关文章
- 一只简单的网络爬虫(基于linux C/C++)————开篇
最近学习开发linux下的爬虫,主要是参考了该博客及其他一些网上的资料.网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息 ...
- 一只简单的网络爬虫(基于linux C/C++)————浅谈并发(IO复用)模型
Linux常用的并发模型 Linux 下设计并发网络程序,有典型的 Apache 模型( Process Per Connection ,简称 PPC ), TPC ( Thread Per Conn ...
- 一只简单的网络爬虫(基于linux C/C++)————支持动态模块加载
插件在软件设计中有很大的好处,可以方便地扩展各种功能,使用插件技术能够在分析.设计.开发.项目计划.协作生产和产品扩展等很多方面带来好处: (1)结构清晰.易于理解.由于借鉴了硬件总线的结构,而且各个 ...
- 一只简单的网络爬虫(基于linux C/C++)————socket相关及HTTP
socket相关 建立连接 网络通信中少不了socket,该爬虫没有使用现成的一些库,而是自己封装了socket的相关操作,因为爬虫属于客户端,建立套接字和发起连接都封装在build_connect中 ...
- 一只简单的网络爬虫(基于linux C/C++)————守护进程
守护进程,也就是通常说的Daemon进程,是Linux中的后台服务进程.它是一个生存期较长的进程,通常独立于控制终端并且周期性地执行某种任务或等待处理某些发生的事件.守护进程常常在系统引导装入时启动, ...
- 一只简单的网络爬虫(基于linux C/C++)————读取命令行参数及日志宏设计
linux上面的程序刚开始启动的时候一般会从命令行获取某些参数,比如以守护进程运行啊什么的,典型的例子就是linux下的man,如下图所示 实现该功能可以使用getopt函数实现,该函数在头文件uni ...
- 一只简单的网络爬虫(基于linux C/C++)————利用正则表达式解析页面
我们向一个HTTP的服务器发送HTTP的请求后,服务器会返回可能一个HTML页面(当然也可以是其他的资源),我们可以利用返回的HTML页面,在其中寻找其他的Url,例如我们可以这样在浏览器上查看一下H ...
- 一只简单的网络爬虫(基于linux C/C++)————Url处理以及使用libevent进行DNS解析
Url处理 爬虫里使用了两个数据结构来管理Url 下面的这个数据结构用来维护原始的Url,同时有一个原始Url的队列 //维护url原始字符串 typedef struct Surl { char * ...
- 一只简单的网络爬虫(基于linux C/C++)————配置文件设计及读取
一般来说linux下比较大型的程序都是以配置文件作为参数介质传递的,该爬虫也采用配置文件的方式来获取参数,配置文件格式大致如下: max_job_num=1 #seeds=https://www.ba ...
随机推荐
- 推荐一款超实用的GitHub可视化代码树插件:Octotree
前言 大家在GitHub查看代码的时候,是不是会经常跳转搜索代码!过一段时间就不知道自己跑到哪里了!有了这款工具,妈妈再也不用担心我找不到代码位置了! 直接上效果图 插件名称 : octotree 作 ...
- Python中list(列表)、dict(字典)、tuple(元组)、set(集合)详细介绍
更新时间:2019.08.10 更新内容: "2.14加入sorted()函数" "2.3"加入一种删除元素的方法 "二.字典"新增1.5, ...
- Linux C++ 网络编程学习系列(4)——多路IO之epoll基础
epoll实现多路IO 源码地址:https://github.com/whuwzp/linuxc/tree/master/epoll 源码说明: server.cpp: 监听127.1:6666,功 ...
- synchronized的锁是针对多线程的
synchronized的锁是针对多线程的,从线程的角度去思考才能真正弄明白. Java的synchronized使用方法总结 1. 把synchronized当作函数修饰符时 这也就是同步方法,那这 ...
- 搭建vue2.0开发环境及手动安装vue-devtools工具
安装vue脚手架 1.安装node.js,如果安装成功输入 node -v ,查看node版本号,输入npm -v查看npm版本 https://nodejs.org/en/ 2.注册淘宝镜像,定制的 ...
- python简易的大乐透数据获取及初步分析
该项目从网上爬取并分析彩票数据,为用户查看和初步分析往期数据提供一种简易的工具. https://github.com/unknowcry/Lottery # -*- coding: utf-8 -* ...
- Atlassian 系列软件安装(Crowd+JIRA+Confluence+Bitbucket+Bamboo)
公司使用的软件开发和协作工具为 Atlassian 系列软件,近期需要从腾讯云迁移到阿里云环境,简单记录下安装和配置过程.(Atlassian 的文档非常详尽,过程中碰见的问题都可以找到解决办法.) ...
- Problem E. Bet
转载:https://blog.csdn.net/qq_40861916/article/details/84403731 #include<iostream> #include<c ...
- NIO教程 ——检视阅读
NIO教程 --检视阅读 参考 BIO,NIO,AIO 总结 Java NIO浅析 Java NIO 教程--极客,蓝本 Java NIO 系列教程 --并发编程网 BIO,NIO--知乎 NIO 入 ...
- SpringBoot全局异常处理与定制404页面
一.错误处理原理分析 使用SpringBoot创建的web项目中,当我们请求的页面不存在(http状态码为404),或者器发生异常(http状态码一般为500)时,SpringBoot就会给我们返回错 ...