一只简单的网络爬虫(基于linux C/C++)————支持动态模块加载
插件在软件设计中有很大的好处,可以方便地扩展各种功能,使用插件技术能够在分析、设计、开发、项目计划、协作生产和产品扩展等很多方面带来好处:
(1)结构清晰、易于理解。由于借鉴了硬件总线的结构,而且各个插件之间是相互独立的,所以结构非常清晰也更容易理解。
(2)易修改、可维护性强。由于插件与宿主程序之间通过接口联系,就像硬件插卡一样,可以被随时删除,插入和修改,所以结构很灵活,容易修改,方便软件的升级和维护。
(3)可移植性强、重用力度大。因为插件本身就是由一系列小的功能结构组成,而且通过接口向外部提供自己的服务,所以复用力度更大,移植也更加方便。
(4)结构容易调整。系统功能的增加或减少,只需相应的增删插件,而不影响整个体系结构,因此能方便的实现结构调整。:
(5)插件之间的耦合度较低。由于插件通过与宿主程序通信来实现插件与插件,插件与宿主程序间的通信,所以插件之间的耦合度更低。
(6)可以在软件开发的过程中修改应用程序。由于采用了插件的结构,可以在软件的开发过程中随时修改插件,也可以在应用程序发行之后,通过补丁包的形式增删插件,通过这种形式达到修改应用程序的目的。
(7)灵活多变的软件开发方式。可以根据资源的实际情况来调整开发的方式,资源充足可以开发所有的插件,资源不充足可以选择开发部分插件,也可以请第三方的厂商开发,用户也可以根据自己的需要进行开发。
linux下面和动态连接相关的函数是dlopen、dlsym和dlclose
使用时在dlopen()函数以指定模式打开指定的动态链接库文件,并返回一个句柄给dlsym()的调用进程。使用dlclose()来卸载打开的库
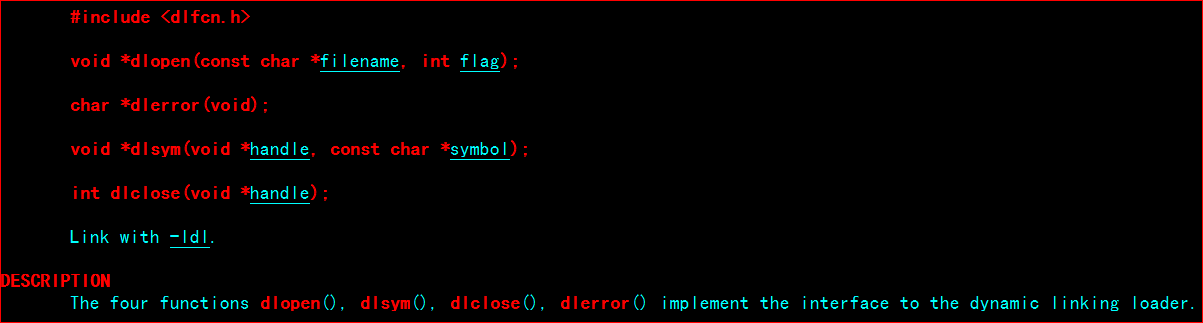
dlopen
功能:打开一个动态链接库
包含头文件: dlfcn.h
函数定义: void * dlopen( const char * pathname, int mode );
函数描述: 在dlopen的()函数以指定模式打开指定的动态连接库文件,并返回一个句柄给调用进程。使用dlclose()来卸载打开的库。
mode:模式有下面这些
RTLD_LAZY 暂缓决定,等有需要时再解出符号
RTLD_NOW 立即决定,返回前解除所有未决定的符号。
RTLD_LOCAL
RTLD_GLOBAL 允许导出符号
RTLD_GROUP
RTLD_WORLD
返回值: 打开错误返回NULL ,成功,返回库引用 ,编译时候要加入 -ldl (指定dl库)

dlsym
功能:根据动态链接库操作句柄与符号,返回符号对应的地址。
包含头文件:dlfcn.h
函数定义:void*dlsym(void* handle,const char* symbol)
函数描述:dlsym根据动态链接库操作句柄(handle)与符号(symbol),返回符号对应的地址。使用这个函数不但可以获取函数地址,也可以获取变量地址。handle是由dlopen打开动态链接库后返回的指针,symbol就是要求获取的函数或全局变量的名称。

dlclose
dlclose用于关闭指定句柄的动态链接库,只有当此动态链接库的使用计数为0时,才会真正被系统卸载。

在使用的dlsym的时候,可如下所示:
假设在my.so中定义了一个void mytest()函数,那在使用my.so时先声明一个函数指针:
void(*pMytest)();
接下来先将那个my.so载入:
pHandle=dlopen("my.so",RTLD_LAZY);//详见dlopen函数
然后使用dlsym函数将函数指针 pMytest 指向 mytest() 函数:
pMytest=(void(*)())dlsym(pHandle,"mytest");//可见放在双引号中的mytest不用加括号,即使有参数也不用
(可调用dlerror();返回错误信息,正确返回为空)这是单个函数的情况,比较容易理解,符号(symbol)就是我们要加载的函数名称。那么如果有多个函数呢?难道需要多次使用该函数加载动态库里面的函数吗???因为dlopen()加载库中的符号,这些符号在编译的时候是不知道的,而且这个符号(symbol)并没有说一定要是函数,因此我们可以使用结构体或其他数据结构把若干函数封装。然后获取该结构体,便可以使用里面的函数了。需要注意的是,我们在使用dlsym加载符号(symbol)的时候,这个符号(symbol)的名称一定要和我们在模块中的结构体的名称一样。爬虫的动态加载如下所示:
//动态加载模块
//路径,模块名称,路径必须是绝对路径
Module * dso_load(const char *path, const char *name)//模块名称
{
void *rv = NULL;
void *handle = NULL;
Module *module = NULL;
//字符串连接
char * npath = strcat2(3, path, name, ".so");//path+name+.so
//dlopen以指定模式打开指定的动态链接库文件,
//并返回一个句柄给dlsym()的调用进程。使用dlclose()来卸载打开的库
//编译时候要加入 -ldl (指定dl库)
if ((handle = dlopen(npath, RTLD_GLOBAL | RTLD_NOW)) == NULL)
{
SPIDER_LOG(SPIDER_LEVEL_ERROR, "Load module fail(dlopen): %s", dlerror());
}
//void*dlsym(void*handle,constchar*symbol)
//handle:由dlopen打开动态链接库后返回的指针;
//symbol:要求获取的函数或全局变量的名称。
//返回值:void* 指向函数的地址,供调用使用。
if ((rv = dlsym(handle, name)) == NULL)
{
SPIDER_LOG(SPIDER_LEVEL_ERROR, "Load module fail(dlsym): %s", dlerror());
}
// name也是结构体的名称,因此可以返回一个结构体
module = (Module *)rv;
module->init(module);//载入的时候调用init函数
return module;
}其中Module结构体如下:
//模块描述结构
typedef struct Module
{
int version;//主版本号
int minor_version;//次版本号
const char *name;//模块名称
void (*init)(Module *);//初始化函数
int (*handle)(void *);//处理函数
} Module;我们只需将所有的函数封装在该结构体内,然后返回一个这样的结构体,就可以通过该结构体使用里面的函数
下面看一个简单的动态模块的例子:
#include "dso.h"
#include "url.h"
static int handler(void * data)
{
Surl *url = (Surl *)data;
if (url->level > g_conf->max_depth)
return MODULE_ERR;
return MODULE_OK;
}
static void init(Module *mod)
{
SPIDER_ADD_MODULE_PRE_SURL(mod);
}
Module maxdepth = {
STANDARD_MODULE_STUFF,
init,
handler
};
该模块实现了两个函数,然后封装在模块maxdepth中,因此dlsym(handle, name)中的name就应该是maxdepth,才可以正确返回该符号,最好是再使用(Module *)进行一下类型转换。
一只简单的网络爬虫(基于linux C/C++)————支持动态模块加载的更多相关文章
- 一只简单的网络爬虫(基于linux C/C++)————开篇
最近学习开发linux下的爬虫,主要是参考了该博客及其他一些网上的资料.网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息 ...
- 一只简单的网络爬虫(基于linux C/C++)————利用正则表达式解析页面
我们向一个HTTP的服务器发送HTTP的请求后,服务器会返回可能一个HTML页面(当然也可以是其他的资源),我们可以利用返回的HTML页面,在其中寻找其他的Url,例如我们可以这样在浏览器上查看一下H ...
- 一只简单的网络爬虫(基于linux C/C++)————配置文件设计及读取
一般来说linux下比较大型的程序都是以配置文件作为参数介质传递的,该爬虫也采用配置文件的方式来获取参数,配置文件格式大致如下: max_job_num=1 #seeds=https://www.ba ...
- 一只简单的网络爬虫(基于linux C/C++)————浅谈并发(IO复用)模型
Linux常用的并发模型 Linux 下设计并发网络程序,有典型的 Apache 模型( Process Per Connection ,简称 PPC ), TPC ( Thread Per Conn ...
- 一只简单的网络爬虫(基于linux C/C++)————socket相关及HTTP
socket相关 建立连接 网络通信中少不了socket,该爬虫没有使用现成的一些库,而是自己封装了socket的相关操作,因为爬虫属于客户端,建立套接字和发起连接都封装在build_connect中 ...
- 一只简单的网络爬虫(基于linux C/C++)————守护进程
守护进程,也就是通常说的Daemon进程,是Linux中的后台服务进程.它是一个生存期较长的进程,通常独立于控制终端并且周期性地执行某种任务或等待处理某些发生的事件.守护进程常常在系统引导装入时启动, ...
- 一只简单的网络爬虫(基于linux C/C++)————读取命令行参数及日志宏设计
linux上面的程序刚开始启动的时候一般会从命令行获取某些参数,比如以守护进程运行啊什么的,典型的例子就是linux下的man,如下图所示 实现该功能可以使用getopt函数实现,该函数在头文件uni ...
- 一只简单的网络爬虫(基于linux C/C++)————线程相关
爬虫里面采用了多线程的方式处理多个任务,以便支持并发的处理,把主函数那边算一个线程的话,加上一个DNS解析的线程,以及我们可以设置的max_job_num值,最多使用了1+1+max_job_num个 ...
- 一只简单的网络爬虫(基于linux C/C++)————Url处理以及使用libevent进行DNS解析
Url处理 爬虫里使用了两个数据结构来管理Url 下面的这个数据结构用来维护原始的Url,同时有一个原始Url的队列 //维护url原始字符串 typedef struct Surl { char * ...
随机推荐
- Alibaba Cloud Linux 2 LTS 正式发布,提供更高性能和更多保障!
在Alibaba Cloud Linux 2(原Aliyun Linux 2)上线一年之际阿里云对外正式发布Alibaba Cloud Linux 2 LTS版本.LTS版本的发布对于Alibaba ...
- pgsql中的lateral使用小结
pgsql中的lateral 什么是LATERAL 带有LATERAL的SQL的计算步骤 LATERAL在OUTER JOIN中的使用限制(或定义限制) LATERAL的几个简单的例子 总结 举几个我 ...
- Linux C++ 网络编程学习系列(2)——多路IO之select实现
select实现多路IO 源码地址:https://github.com/whuwzp/linuxc/tree/master/select 源码说明: server.cpp: 监听127.1:6666 ...
- Web开发与设计之Google兵器谱-Web开发与设计利器
Web开发与设计之Google兵器谱-Web开发与设计利器 博客分类: Java综合 WebGoogleAjaxChromeGWT 笔者是个Java爱好者也是用Java进行web开发的工作者.平时笔者 ...
- Math.max.apply()用法
apply的一些其他巧妙用法 Math.max.apply( null, [12,23,34,45] ); //细心的人可能已经察觉到,在我调用apply方法的时候, // 第一个参数是对象(this ...
- 用Python介绍了企业资产情况的数据爬取、分析与展示。
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者:张耀杰 PS:如有需要Python学习资料的小伙伴可以加点击下方链接自 ...
- 原创Pig0.16.0安装搭建
tar -zxvf pig-0.16.0.tar.gz -C ~ vi ~/.bash_profile export PIG_HOME=/home/hadoop/pig-0.16.0 export ...
- web测试流程
1.立项后测试需要拿到文档(需求说明书,原型图,接口文档,) 2.需求评审 3.用例编写(主流程,备流程,异常流,业务规则,正常类,异常类,页面检查) 测试用例编写方法(等价类划分,边界值分析法,错误 ...
- jmeter引入外部jar包的方法
jmeter最完美的jar包引入 第一步:需要新建一个文件夹用来存放需要引用的外部jar包,例如:建一个dependencies 文件夹 第二步:jmeter 的配置文件 jmeter.propert ...
- HBase Filter 过滤器概述
abc 过滤器介绍 HBase过滤器是一套为完成一些较高级的需求所提供的API接口. 过滤器也被称为下推判断器(push-down predicates),支持把数据过滤标准从客户端下推到服务器,带有 ...