python-day3爬虫基础之下载网页
今天主要学习了关于网页下载器的一些内容,下边做一下总结:
1.网页下载器,顾名思义,就是将URL所对应的网页以HTML的形式下载到本地,最终存储成本地文件或者还是本地内存字符串,然后进行后续的分析与处理;
网页下载器主要有:urllib2和requests
下边介绍下urllib下载网页的方法:

首先是引入urllib.request
然后打开我们所定义的url,最后打印出状态码(getcode的作用就获取状态码),如果状态码是200的话,就代表是正常的。运行之后的结果如下所示:

2.网页解析器:它是以下载好的html网页字符串作为输入,然后从中提取出有价值的数据以及新的URL。
其中常见的网页解析器有:正则表达式(这是一种模糊化思想,个人认为就跟搜索关键词一样)
html.parser
Beautiful Soup(比较强大且比较常用)
lxml
其中后三者主要适用于结构化解析,这里还涉及到一个词叫做DOM(Document Object Model)树,这个今天理解的不是很透彻,以后在慢慢谈。Beautiful Soup属于python的第三方库,主要是从html和xml中提取数据。
这里给大家举个例子:
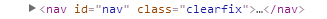
在这里,节点名称就是 nav,节点属性:id=“nav” class=“clearfix” ,节点内容:...
除此之外,今天还接触到了实例爬虫的过程:
第一步就是确定目标;第二步就是分析目标,这里边包括URL格式、数据格式以及网页编码;第三步就是编写代码了,最后执行爬虫。
今天白天帮老师干活,晚上身体有点不舒服,学的比较少,写的也比较范范,希望大家理解,如果有写的不对的,欢迎指出,大家共同学习,一起进步。
python-day3爬虫基础之下载网页的更多相关文章
- python从爬虫基础到爬取网络小说实例
一.爬虫基础 1.1 requests类 1.1.1 request的7个方法 requests.request() 实例化一个对象,拥有以下方法 requests.get(url, *args) r ...
- Python扫描器-爬虫基础
0x1.基础框架原理 1.1.爬虫基础 爬虫程序主要原理就是模拟浏览器发送请求->下载网页代码->只提取有用的数据->存放于数据库或文件中 1.1.基础原理 1.发起HTTP请求 2 ...
- Python BeautifulSoup4 爬虫基础、多线程学习
针对 崔庆才老师 的 https://ssr1.scrape.center 的爬虫基础练习.Threading多线程库.Time库.json库.BeautifulSoup4 爬虫库.py基本语法
- Python开发爬虫之BeautifulSoup解析网页篇:爬取安居客网站上北京二手房数据
目标:爬取安居客网站上前10页北京二手房的数据,包括二手房源的名称.价格.几室几厅.大小.建造年份.联系人.地址.标签等. 网址为:https://beijing.anjuke.com/sale/ B ...
- Python归纳 | 爬虫基础知识
1. urllib模块库 Urllib是python内置的HTTP请求库,urllib标准库一共包含以下子包: urllib.error 由urllib.request引发的异常类 urllib.pa ...
- 自学Python六 爬虫基础必不可少的正则
要想做爬虫,不可避免的要用到正则表达式,如果是简单的字符串处理,类似于split,substring等等就足够了,可是涉及到比较复杂的匹配,当然是正则的天下,不过正则好像好烦人的样子,那么如何做呢,熟 ...
- python网络爬虫抓取动态网页并将数据存入数据库MySQL
简述以下的代码是使用python实现的网络爬虫,抓取动态网页 http://hb.qq.com/baoliao/ .此网页中的最新.精华下面的内容是由JavaScript动态生成的.审查网页元素与网页 ...
- 自学Python四 爬虫基础知识储备
首先,推荐两个关于python爬虫不错的博客:Python爬虫入门教程专栏 和 Python爬虫学习系列教程 .写的都非常不错,我学习到了很多东西!在此,我就我看到的学到的进行总结一下! 爬虫就是 ...
- 自学Python五 爬虫基础练习之SmartQQ协议
BAT站在中国互联网的顶端,引导着中国互联网的发展走向...既受到了多数程序员的关注,也在被我们所惦记着... 关于SmartQQ的协议来自HexBlog,根据他的博客我自己也一步一步的去分析,去尝试 ...
随机推荐
- C# Stream篇(四) -- FileStream
FileStream 目录: 如何去理解FileStream? FileStream的重要性 FileStream常用构造函数(重要) 非托管参数SafeFileHandle简单介绍 FileStre ...
- linux系统pid的最大值研究
内核源码探查 通过对linux内核源码的追踪,可以看到对pid最大值的限定最终集中到include/linux/threads.h文件中的PID_MAX_DEFAULT上了,代码如下: /* * Th ...
- js原型链理解(2)--原型链继承
1.原型链继承 2.constructor stealing(构造借用) 3.组合继承 js中的原型链继承,运用的js原型链中的__proto__. function Super(){ this.se ...
- 初步了解URL
URl的定义: 在webs上每种可用的资源(比如:HTML文档,图像,视频片段,程序等)都可以由一个通用的资源标志符(Universal Resource Identifier)进行定位.URl的组成 ...
- Tornado中的Cookie设置
Tornado中的cookie分为两种--普通cookie和安全cookie 普通cookie 1.创建cookie 原型 self.set_cookie(name, value, domain=No ...
- UVA - 818 Cutting Chains(切断圆环链)(dfs + 二进制法枚举子集)
题意:有n个圆环(n<=15),已知已经扣在一起的圆环,现在需要打开尽量少的圆环,使所有圆环可以组成一条链. 分析:因为不知道要打开哪个环,如果列举所有的可能性,即枚举打开环的所有子集,最多才2 ...
- int *const 与const int *问题
自己一直就不太清楚int *const与const int*之间的差别,总是弄混,今天势必拿一个程序验证一下. 一个指针是有两个属性的,一个是它指向的地方,一个是它指向地方上的内容.两者的差别也在此. ...
- PHP - 验证码制作加验证
一,主页 index.php <!DOCTYPE html> <html lang="en"> <head> <meta charse ...
- python刷LeetCode:26. 删除排序数组中的重复项
难度等级:简单 题目描述: 给定一个排序数组,你需要在原地删除重复出现的元素,使得每个元素只出现一次,返回移除后数组的新长度. 不要使用额外的数组空间,你必须在原地修改输入数组并在使用 O(1) 额外 ...
- FFmpeg命令大全(更新中)
1.视频抽取音频: ffmpeg -i 3.mp4 -vn -y -acodec copy 3.aacffmpeg -i 3.mp4 -vn -y -acodec copy 3.m4a