python3下scrapy爬虫(第十二卷:解决scrapy数据存储大量数据时阻塞问题)
之前我们使用scrapy爬取数据,用的存储方式是直接引入PYMYSQL,或者MYSQLDB,案例中数据量并不大,这种数据存储方式属于同步过程,也就是上一条语句执行完才能执行下一条语句,当数据量变大时,由于SCRAPY解析数据的速率远远大于数据存储入数据库的速度,以至于造成数据阻塞,可以理解为数据高并发的问题。
现在我们可以使用TWISTED里的功能,话不多说先在PIPELINE里引入类对象,来执行异步操作:

引入adbapi对象
第一步:在SETTINGS.py里设置数据库连接配置,做成数据异步容器,书写格式如下图

第二步:自定义PIPRLINE,将配置数据的异步容器引入过来,注意语法引入的方法,将配置数据写入字典中,并以动态参数的方式作为连接池的参数
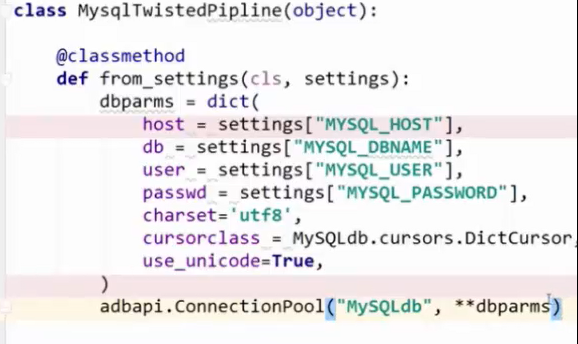
第三步:创建连接对象:


第四步:使用TWISTED将数据插入变为异步执行
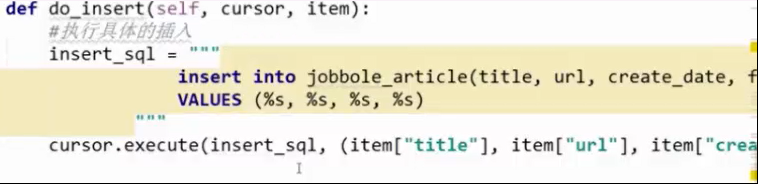
 第五步:执行插入:
第五步:执行插入:
 第六步:加入异步存储异常处理函数:
第六步:加入异步存储异常处理函数:

这种存储方式是极力推荐的一定是要会的 因为真正的爬虫工作数据量都特别大
python3下scrapy爬虫(第十二卷:解决scrapy数据存储大量数据时阻塞问题)的更多相关文章
- 爬虫(十二):scrapy中spiders的用法
Spider类定义了如何爬去某个网站,包括爬取的动作以及如何从网页内容中提取结构化的数据,总的来说spider就是定义爬取的动作以及分析某个网页 工作流程分析 以初始的URL初始化Request,并设 ...
- scrapy爬虫学习系列二:scrapy简单爬虫样例学习
系列文章列表: scrapy爬虫学习系列一:scrapy爬虫环境的准备: http://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_python_00 ...
- 爬虫系列(十二) selenium的基本使用
一.selenium 简介 随着网络技术的发展,目前大部分网站都采用动态加载技术,常见的有 JavaScript 动态渲染和 Ajax 动态加载 对于爬取这些网站,一般有两种思路: 分析 Ajax 请 ...
- Spring Boot 揭秘与实战(二) 数据存储篇 - 数据访问与多数据源配置
文章目录 1. 环境依赖 2. 数据源 3. 单元测试 4. 源代码 在某些场景下,我们可能会在一个应用中需要依赖和访问多个数据源,例如针对于 MySQL 的分库场景.因此,我们需要配置多个数据源. ...
- python3下scrapy爬虫(第十卷:scrapy数据存储进mysql)
上一卷中我将爬取的数据文件直接写入文本文件中,现在我将数据存储到mysql中,我依然用的是pymysql,这个很麻烦建表需要在外面建 这次代码只需要改变pipyline就行 来 现在看下结果: 对比发 ...
- python3下scrapy爬虫(第十四卷:scrapy+scrapy_redis+scrapyd打造分布式爬虫之执行)
现在我们现在一个分机上引入一个SCRAPY的爬虫项目,要求数据存储在MONGODB中 现在我们需要在SETTING.PY设置我们的爬虫文件 再添加PIPELINE 注释掉的原因是爬虫执行完后,和本地存 ...
- 爬虫(十六):scrapy爬取知乎用户信息
一:爬取思路 首先我们应该找到一个账号,这个账号被关注的人和关注的人都相对比较多的,就是下图中金字塔顶端的人,然后通过爬取这个账号的信息后,再爬取他关注的人和被关注的人的账号信息,然后爬取被关注人的账 ...
- scrapy爬虫框架实例二
本实例主要通过抓取慕课网的课程信息来展示scrapy框架抓取数据的过程. 1.抓取网站情况介绍 抓取网站:http://www.imooc.com/course/list 抓取内容:要抓取的内容是全部 ...
- python3 练习题100例 (十二)
题目十二:打印出所有的"水仙花数",所谓"水仙花数"是指一个三位数,其各位数字立方和等于该数本身.例如:153是一个"水仙花数",因为153 ...
随机推荐
- SeetaFaceQt:Qt多线程
为什么要做多线程,说个最简单的道理就是我们不希望在软件处理数据的时候界面处于无法响应的假死状态.有些处理是灰常花时间的,如果把这样的处理放到主线程中执行,就会导致软件一条路走到底,要等到处理完才能接收 ...
- python刷LeetCode:5. 最长回文子串
难度等级:中等 题目描述: 给定一个字符串 s,找到 s 中最长的回文子串.你可以假设 s 的最大长度为 1000. 示例 1: 输入: "babad"输出: "bab& ...
- openlayers基础用例
http://weilin.me/ol3-primer/ch03/03-01.html#http://weilin.me/ol3-primer/ //地址http://openlayers.org/ ...
- python开源库——h5py快速指南
1. 核心概念 一个HDF5文件是一种存放两类对象的容器:dataset和group. Dataset是类似于数组的数据集,而group是类似文件夹一样的容器,存放dataset和其他group.在使 ...
- BSC软件交流-BS
管理体系的提升公司.部门 关键指标 体系EXCEL记录的方式 较老,不够系统化BSC模式 测评.咨询.绩效软件目标地图 ,任务 目标 分解 平台?手机端? 集成 钉钉? paas平台?基础数据的获取团 ...
- ServiceComb 集成 Shiro 实践|火影专场发布
Shiro简介 Apache Shiro是一款功能强大.易用的轻量级开源Java安全框架,它主要提供认证.鉴权.加密和会话管理等功能.Spring Security可能是业界用的最广泛的安全框架,但是 ...
- Consul集群版容器化部署与应用集成
背景 由于公司目前的主要产品使用的注册中心是consul,consul需要用集群来保证高可用,传统的方式(Nginx/HAProxy)会有单点故障问题,为了解决该问题,我开始研究如何只依赖consul ...
- 吴裕雄--天生自然 PHP开发学习:表单和用户输入
<html> <head> <meta charset="utf-8"> <title>菜鸟教程(runoob.com)</t ...
- PAT Advanced 1081 Rational Sum (20) [数学问题-分数的四则运算]
题目 Given N rational numbers in the form "numerator/denominator", you are supposed to calcu ...
- VMware下的Ubuntu16设置连接主机网络,设置主机下可以通过xshell访问 VMware下的Ubuntu
NAT模式连接 1. 2. 3. 4. 5. 6.