Big Data(八)MapReduce的搭建和初步使用
---恢复内容开始---
回顾:
1.最终开发MR的计算程序
2.hadoop 2.x 出现了一个yarn:资源管理>>MR没有后台场服务
yarn模型:container 容器,里面会运行我们的AppMaster,map/reduce Task
解耦
mapreduce on yarn
架构:RM NM
搭建:
RM要和NN岔开,NM个数要和DN一样
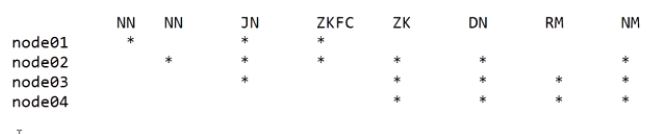
搭建图
----------通过官网:
mapred-site.xml > mapreduce on yarn
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
yarn-site.xml
//shuffle 洗牌 M -shuffle> R
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property> <property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>node02:,node03:,node04:</value>
</property> <property>
<name>yarn.resourcemanager.cluster-id</name>
<value>mashibing</value>
</property> <property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>node03</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>node04</value>
</property>
流程:
我hdfs等所有的都用root来操作的
node01:
cd $HADOOP_HOME/etc/hadoop
cp mapred-site.xml.template mapred-site.xml
vi mapred-site.xml
vi yarn-site.xml
scp mapred-site.xml yarn-site.xml node02:`pwd`
scp mapred-site.xml yarn-site.xml node03:`pwd`
scp mapred-site.xml yarn-site.xml node04:`pwd`
vi slaves //可以不用管,搭建hdfs时候已经改过了。。。
start-yarn.sh
node03~:
yarn-daemon.sh start resourcemanager
http://node03:8088
http://node04:8088
This is standby RM. Redirecting to the current active RM: http://node03:8088/
-------MR 官方案例使用:wc
实战:MR ON YARN 的运行方式:
hdfs dfs -mkdir -p /data/wc/input
hdfs dfs -D dfs.blocksize= -put data.txt /data/wc/input
cd $HADOOP_HOME
cd share/hadoop/mapreduce
hadoop jar hadoop-mapreduce-examples-2.6..jar wordcount /data/wc/input /data/wc/output
1)webui:
2)cli:
hdfs dfs -ls /data/wc/output
-rw-r--r-- root supergroup -- : /data/wc/output/_SUCCESS //标志成功的文件
-rw-r--r-- root supergroup -- : /data/wc/output/part-r- //数据文件
part-r-
part-m-
r/m : map+reduce r / map m
hdfs dfs -cat /data/wc/output/part-r-
hdfs dfs -get /data/wc/output/part-r- ./
抛出一个问题:
data.txt 上传会切割成2个block 计算完,发现数据是对的~!~?后边注意听源码分析~!~~
Big Data(八)MapReduce的搭建和初步使用的更多相关文章
- Spring学习笔记--环境搭建和初步理解IOC
Spring框架是一个轻量级的框架,不依赖容器就能够运行,像重量级的框架EJB框架就必须运行在JBoss等支持EJB的容器中,核心思想是IOC,AOP,Spring能够协同Struts,hiberna ...
- Android开发利器之Data Binding Compiler V2 —— 搭建Android MVVM完全体的基础
原创声明: 该文章为原创文章,未经博主同意严禁转载. 前言: Android常用的架构有:MVC.MVP.MVVM,而MVVM是唯一一个官方提供支持组件的架构,我们可以通过Android lifecy ...
- 【Big Data - Hadoop - MapReduce】通过腾讯shuffle部署对shuffle过程进行详解
摘要: 通过腾讯shuffle部署对shuffle过程进行详解 摘要:腾讯分布式数据仓库基于开源软件Hadoop和Hive进行构建,TDW计算引擎包括两部分:MapReduce和Spark,两者内部都 ...
- Redis总结(八)如何搭建高可用的Redis集群
以前总结Redis 的一些基本的安装和使用,大家可以这这里查看Redis 系列文章:https://www.cnblogs.com/zhangweizhong/category/771056.html ...
- Kubernetes 系列(八):搭建EFK日志收集系统
Kubernetes 中比较流行的日志收集解决方案是 Elasticsearch.Fluentd 和 Kibana(EFK)技术栈,也是官方现在比较推荐的一种方案. Elasticsearch 是一个 ...
- SpringCloud微服务实战——搭建企业级开发框架(三十八):搭建ELK日志采集与分析系统
一套好的日志分析系统可以详细记录系统的运行情况,方便我们定位分析系统性能瓶颈.查找定位系统问题.上一篇说明了日志的多种业务场景以及日志记录的实现方式,那么日志记录下来,相关人员就需要对日志数据进行 ...
- android开发教程(八)——环境搭建之java-ndk
目录 android ndk是android用于开发本地代码的开发工具包.它提供C/C++交叉编译工具.android内核.驱动.已有的C/C++代码,都需要ndk来支持开发. 目前支持以下平台:ar ...
- mybatis框架搭建学习初步
mybatis框架搭建步骤:1. 拷贝jar到lib目录下,而且添加到工程中2. 创建mybatis-config.xml文件,配置数据库连接信息 <environments default=& ...
- 【Big Data - Hadoop - MapReduce】hadoop 学习笔记:MapReduce框架详解
开始聊MapReduce,MapReduce是Hadoop的计算框架,我学Hadoop是从Hive开始入手,再到hdfs,当我学习hdfs时候,就感觉到hdfs和mapreduce关系的紧密.这个可能 ...
随机推荐
- c++ STL -- set和multiset
set和multiset 1.结构 set和multiset会根据特定的排序原则将元素排序.两者不同之处在于,multisets允许元素重复,而set不允许重复. 只要是assignable.copy ...
- leetcode172 阶乘后的零
对数算法:O(nlogn) /** 即为统计0-n中5,10,15,20,25的个数,因为肯定有足够的偶数使得存在x*5=10*n,25=5*5因此计数加2,5=1*5计数加一: 但如果挨个计数当n很 ...
- 使用ViewPager实现广告自动轮播的效果
package com.loaderman.viewpgerlunbodemo; import android.os.Bundle; import android.os.Handler; import ...
- SQL2008附加数据库报错
sql server 2008如何导入mdf,ldf文件 网上找了很多解决sql server导入其他电脑拷过来的mdf文件,多数是不全,遇到的解决方法不一样等问题,下边是找到的解决问题的最全面方法! ...
- flutter button
flutter button button类型: RaisedButton : 凸起的按钮,其实就是Android中的Material Design风格的Button ,继承自MaterialButt ...
- CTF—攻防练习之ssh私钥泄露
攻防练习1 ssh私钥泄露 靶场镜像:链接: https://pan.baidu.com/s/1xfKILyIzELi_ZgUw4aXT7w 提取码: 59g0 首先安装打开靶场机 没办法登录,也没法 ...
- Blue Star(日剧:今夜 可否拥你入怀歌词)
BLUE STAR-COLOR CREATION Oh I Know I need you in my life ひさしぶりの 译:时隔许久的 やわらかなかせがふきぬける 清风温柔吹拂 むねのおくの ...
- Egret入门学习日记 --- 第二篇 (书籍的选择 && 书籍目录 && 书中 3.3 节 内容)
第二篇 (书籍的选择 && 书籍目录 && 书中 3.3 节 内容) 既然选好了Egret,那我就要想想怎么学了. 开始第一步,先加个Q群先,这不,拿到了一本<E ...
- 描述下数据库中的事务--ACID各个的特点
1. 原子性(Atomicity) 在一个事务内的操作,要么全部成功,要么全部失败. 2. 一致性(Consistency) 数据库从一个一致性状态,转移到另一个一致性状态. 3. 隔离性(Isola ...
- Ubuntu安装并使用emacs
1. sudo add-apt-repository ppa:kelleyk/emacs 2. sudo apt update sudo apt install emacs26 3.安装完成,查看em ...