【深度学习】之Caffe的solver文件配置(转载自csdn)
原文: http://blog.csdn.net/czp0322/article/details/52161759
今天在做FCN实验的时候,发现solver.prototxt文件一直用的都是model里自带的,一直都对里面的参数不是很了解,所以今天认真学习了一下里面各个参数的意义。
DL的任务中,几乎找不到解析解,所以将其转化为数学中的优化问题。sovler的主要作用就是交替调用前向传导和反向传导 (forward & backward) 来更新神经网络的连接权值,从而达到最小化loss,实际上就是迭代优化算法中的参数。
Caffe的solver类提供了6种优化算法,配置文件中可以通过type关键字设置:
- Stochastic Gradient Descent (type: “SGD”)
- AdaDelta (type: “AdaDelta”)
- Adaptive Gradient (type: “AdaGrad”)
- Adam (type: “Adam”)
- Nesterov’s Accelerated Gradient (type: “Nesterov”)
- RMSprop (type: “RMSProp”)
简单地讲,solver就是一个告诉caffe你需要网络如何被训练的一个配置文件。
Solver.prototxt 流程
- 首先设计好需要优化的对象,以及用于学习的训练网络和测试网络的prototxt文件(通常是train.prototxt和test.prototxt文件)
- 通过forward和backward迭代进行优化来更新参数
- 定期对网络进行评价
- 优化过程中显示模型和solver的状态
solver参数
base_lr
这个参数代表的是此网络最开始的学习速率(Beginning Learning rate),一般是个浮点数,根据机器学习中的知识,lr过大会导致不收敛,过小会导致收敛过慢,所以这个参数设置也很重要。
lr_policy
这个参数代表的是learning rate应该遵守什么样的变化规则,这个参数对应的是字符串,选项及说明如下:
- “step” - 需要设置一个stepsize参数,返回base_lr * gamma ^ ( floor ( iter / stepsize ) ),iter为当前迭代次数
- “multistep” - 和step相近,但是需要stepvalue参数,step是均匀等间隔变化,而multistep是根据stepvalue的值进行变化
- “fixed” - 保持base_lr不变
- “exp” - 返回base_lr * gamma ^ iter, iter为当前迭代次数
- “poly” - 学习率进行多项式误差衰减,返回 base_lr ( 1 - iter / max_iter ) ^ ( power )
- “sigmoid” - 学习率进行sigmod函数衰减,返回 base_lr ( 1/ 1+exp ( -gamma * ( iter - stepsize ) ) )
gamma
这个参数就是和learning rate相关的,lr_policy中包含此参数的话,需要进行设置,一般是一个实数。
stepsize
This parameter indicates how often (at some iteration count) that we should move onto the next “step” of training. This value is a positive integer.
stepvalue
This parameter indicates one of potentially many iteration counts that we should move onto the next “step” of training. This value is a positive integer. There are often more than one of these parameters present, each one indicated the next step iteration.
max_iter
最大迭代次数,这个数值告诉网络何时停止训练,太小会达不到收敛,太大会导致震荡,为正整数。
momentum
上一次梯度更新的权重,real fraction
weight_decay
权重衰减项,用于防止过拟合。
solver_mode
选择CPU训练或者GPU训练。
snapshot
训练快照,确定多久保存一次model和solverstate,positive integer。
snapshot_prefix
snapshot的前缀,就是model和solverstate的命名前缀,也代表路径。
net
path to prototxt (train and val)
test_iter
每次test_interval的test的迭代次数,假设测试样本总数为10000张图片,一次性执行全部的话效率很低,所以将测试数据分为几个批次进行测试,每个批次的数量就是batch_size。如果batch_size=100,那么需要迭代100次才能将10000个数据全部执行完,所以test_iter设置为100。
test_interval
测试间隔,每训练多少次进行一次测试。
display
间隔多久对结果进行输出
iter_size
这个参数乘上train.prototxt中的batch size是你实际使用的batch size。 相当于读取batchsize * itersize个图像才做一下gradient decent。 这个参数可以规避由于gpu内存不足而导致的batchsize的限制 因为你可以用多个iteration做到很大的batch 即使单次batch有限。
average_loss
取多次foward的loss作平均,进行显示输出。
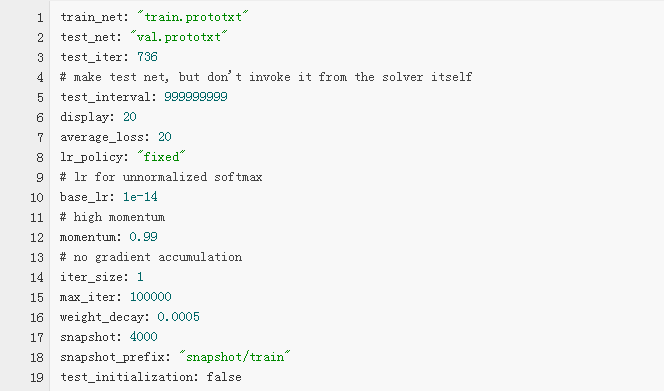
FCN的solver.prototxt文件
【深度学习】之Caffe的solver文件配置(转载自csdn)的更多相关文章
- 【转】Caffe的solver文件配置
http://blog.csdn.net/czp0322/article/details/52161759 solver.prototxt 今天在做FCN实验的时候,发现solver.prototxt ...
- 深度学习框架Caffe的编译安装
深度学习框架caffe特点,富有表达性.快速.模块化.下面介绍caffe如何在Ubuntu上编译安装. 1. 前提条件 安装依赖的软件包: CUDA 用来使用GPU模式计算. 建议使用 7.0 以上最 ...
- 深度学习框架-caffe安装-环境[Mac OSX 10.12]
深度学习框架-caffe安装 [Mac OSX 10.12] [参考资源] 1.英文原文:(使用GPU) [http://hoondy.com/2015/04/03/how-to-install-ca ...
- 深度学习框架-caffe安装-Mac OSX 10.12
p.p1 { margin: 0.0px 0.0px 0.0px 0.0px; font: 12.0px ".PingFang SC"; color: #454545 } p.p2 ...
- 常用深度学习框——Caffe/ TensorFlow / Keras/ PyTorch/MXNet
常用深度学习框--Caffe/ TensorFlow / Keras/ PyTorch/MXNet 一.概述 近几年来,深度学习的研究和应用的热潮持续高涨,各种开源深度学习框架层出不穷,包括Tenso ...
- Caffe学习系列(7):solver及其配置
solver算是caffe的核心的核心,它协调着整个模型的运作.caffe程序运行必带的一个参数就是solver配置文件.运行代码一般为 # caffe train --solver=*_slover ...
- caffe(7) solver及其配置
solver算是caffe的核心的核心,它协调着整个模型的运作.caffe程序运行必带的一个参数就是solver配置文件.运行代码一般为 # caffe train --solver=*_slover ...
- 【神经网络与深度学习】Caffe使用step by step:caffe框架下的基本操作和分析
caffe虽然已经安装了快一个月了,但是caffe使用进展比较缓慢,果然如刘老师说的那样,搭建起来caffe框架环境比较简单,但是完整的从数据准备->模型训练->调参数->合理结果需 ...
- 开源深度学习架构Caffe
Caffe 全称为 Convolutional Architecture for Fast Feature Embedding,是一个被广泛使用的开源深度学习框架(在 TensorFlow 出现之前一 ...
随机推荐
- HW职责 (Hardware Engineer)
硬件设计就是根据产品经理的需求PRS(Product Requirement Specification),在COGS(Cost of Goods Sale)的要求下,利用目前业界成熟的芯片方案或者技 ...
- django进行model字段的自定义
相信大家一定有web应用被攻击的经历,数据库安全是一个网站的必须课.django有很好的orm,但sql注入,或其他方式的攻击都是无法完全屏蔽的. 所以一般数据库都会对用户数据,如text类型的数据进 ...
- varnish 内置函数详细说明
Subroutine列表 •vcl_recv 在请求开始时候被调用,在请求已经被接收到并且解析后调用.目的就是决定是否处理这个请求,怎么处理,使用哪个后端.vcl_recv以return结束,参数可以 ...
- 1st贝塞尔函数的使用
x=-100:0.1:100; y1=besselj(7,x);y2=besselj(10,x);y3=besselj(20,x);y4=besselj(40,x);y5=besselj(60,x); ...
- elasticsearch-PHP第一天
遇到很大的问题就是,给边做边找原因,看官方文档,全英文看不懂.只能慢慢一步一步去做. 性子太急,真的不行,跨越性太大,卡一个小时多,才发现,连安装都没搞明白. 首先需要一个JAVA环境,上百度 ...
- 创建【哆啦A梦】风格字体
学习canvas,为作画.对于一个毫无逻辑思维的人简直遭罪啊~想象坐标坐标坐标啊- - 好啦言归正传,基于本月16号,在春熙路IFS展出120只哆啦a梦,以及canvas的作用,在此介绍一种PS的美化 ...
- android 返回键 操作
cocos2dx项目移植到android平台上对于 android手机返回键,主菜单键等键的相关操作,本篇详细对返回键做个简单的介绍说明, 不足不对之处,请同猿们指出. 首先在主activity下,即 ...
- K - Least Common Multiple
Time Limit:1000MS Memory Limit:32768KB 64bit IO Format:%I64d & %I64u Submit Status Descr ...
- C++学习笔记30:模板与型式参数化
转型操作 接受目标型式作为模板参数 Programmer *p = dynamic_cast<Programmer*>(e) 模板工作原理 使用template<typename T ...
- Spike Notes on Lock based Concurrency Concepts
Motivation 承并发编程笔记Outline,这篇文章专注于记录学习基于锁的并发概念的过程中出现的一些知识点,为并发高层抽象做必要的准备. 尽管存在Doug Lee开山之作Concurrent ...