企业级分布式存储应用与实战FastDFS实现
FASTDFS是什么
FastDFS是由国人余庆所开发,其项目地址:https://github.com/happyfish100
FastDFS是一个轻量级的开源分布式文件系统,主要解决了大容量的文件存储和高并发访问的问题,文件存取时实现了负载均衡。
FastDFS是一款类Google FS的开源分布式文件系统,它用纯C语言实现,支持Linux、FreeBSD、AIX等UNIX系统。它只能通过 专有API对文件进行存取访问,不支持POSIX接口方式,不能mount使用。准确地讲,Google FS以及FastDFS、mogileFS、 HDFS、TFS等类Google FS都不是系统级的分布式文件系统,而是应用级的分布式文件存储服务。
FastDFS的特性
1、分组存储,灵活简洁、对等结构,不存在单点
2、 文件ID由FastDFS生成,作为文件访问凭证。FastDFS不需要传统的name server
3、和流行的web server无缝衔接,FastDFS已提供apache和nginx扩展模块
4、大、中、小文件均可以很好支持,支持海量小文件存储
5、 支持多块磁盘,支持单盘数据恢复
6、 支持相同文件内容只保存一份,节省存储空间
7、 存储服务器上可以保存文件附加属性
8、 下载文件支持多线程方式,支持断点续传
|
指标 |
FastDFS |
mogileFS |
|
系统简洁性 |
简洁,只有两个角色:tracker和storage |
一般,有三个角色:tracker,storage和存储文件信息的mysql db |
|
系统性能 |
很高(没有数据库,文件同步直接点对点,不经过tracker中转) |
高(使用mysql来存储文件索引等信息文件同步通过tracker调度和中转) |
|
系统稳定性 |
高(c语言开发,可以支持高并发和高负载) |
一般(Perl语言开发,高并发和高负载支持一般) |
|
RAID方式 |
分组(组内冗余),灵活性大 |
动态冗余,灵活性一般 |
|
通信协议 |
专有协议 下载文件支持http |
http |
|
技术文档 |
较详细 |
较少 |
|
文件附加属性(meta data) |
支持 |
不支持 |
|
相同内容文件只保存一分 |
支持 |
不支持 |
|
下载文件时支持文件偏移量 |
支持 |
不支持 |
FastDFS和集中存储方式对比
|
指标 |
FastDFS |
NFS |
集中存储设备如:NetApp,NAS |
|
线性扩容性 |
高 |
差 |
差 |
|
文件高并发访问性能 |
高 |
差 |
一般 |
|
文件访问方式 |
专有API |
POSIX |
支持POSIX |
|
硬件成本 |
较低 |
中等 |
高 |
|
相同文件内容只保存一份 |
支持 |
不支持 |
不支持 |

工作方式:客户端向tracker发出请求,然后tracker从storage节点拿到源数据,返还给客户端,然后客户端根据源数据再去请求storage节点。
FastDFS架构解读
1.只有两个角色,tracker server和storage server,不需要存储文件索引信息
2.所有服务器都是对等的,不存在Master-Slave关系
3.存储服务器采用分组方式,同组内存储服务器上的文件完全相同(RAID 1)
4.不同组的storage server之间不会相互通信
5.由storage server主动向tracker server报告状态信息,tracker server之间通常不会相互通信
系统架构-上传文件流程图

1. client询问tracker上传到的storage;
2. tracker返回一台可用的storage;
3. client直接和storage通信完成文件上传,storage返回文件ID。
•系统架构-下载文件流程图
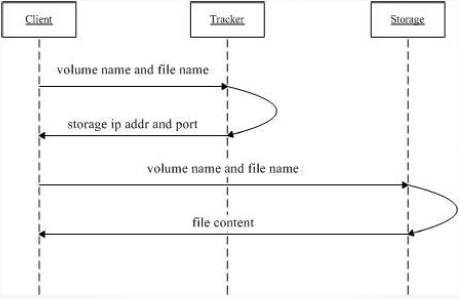
1. client询问tracker下载文件的storage,参数为文件ID(组名和文件名);
2. tracker返回一台可用的storage;
3. client直接和storage通信完成文件下载。
FastDFS同步机制
1.采用binlog文件记录更新操作,根据binlog进行文件同步同一组内的storage server之间是对等的,文件上传、删除等操作可以在任意一台storage server上进行;
2.文件同步只在同组内的storage server之间进行,采用push方式,即源服务器同步给目标服务器;
源头数据才需要同步,备份数据不需要再次同步,否则就构成环路了;
3.上述第二条规则有个例外,就是新增加一台storage server时,由已有的一台storage server将已有的所有数据(包括源头数据和备份数据)同步给该新增服务器。
FastDFS用户请求过程

FastDFS核心组件
Tracker:调度器,负责维持集群的信息,例如各group及其内部的storage node,这些信息也是storage node报告所生成;每个storage node会周期性向tracker发心跳信息;
storage server:以group为单位进行组织,任何一个storage server都应该属于某个group,一个group应该包含多个storage server;在同一个group内部,各storage server的数据互相冗余;
FastDFS运行机制
如何在组中挑选storage server:
1、rr;
2、以ip为次序,找第一个,即IP地址较小者;
3、以优先级为序,找第一个;
如何选择磁盘(存储路径):
1、rr;
2、剩余可用空间大者优先;
生成FID:
由源头storage server ip、创建时的时间戳、大小、文件的校验码和一个随机数进行hash计算后生成;最后基于base64
进行文本编码,转换为可打印字符;
groupID/MID/H1ID/H2ID/file_name
groupID:组编号
MID:存储路径(存储设备)编号
H1ID/H2ID:目录分层
file_name:文件名,不同于用户上传时使用文件名,而是由服务器生成hash文件名;
服务器IP、文件创建时的时间戳、文件大小、文件名和扩展名;
文件同步:
每个storage server在文件存储完成后,会将其信息存于binlog, binlog不包含数据,仅包含文件名等元数据信息;
binlog可用于同步;
FastDFS配置修改
tracker:
编辑tracker server配置文件tracker.conf,需要修改内容如下:
disabled=false(默认为false,表示是否无效)
port=22122(默认为22122)
base_path=/data/fastdfs/tracker
storage server:
disabled=false(默认为false,表示是否无效)
port=23000(默认为23000)
base_path=/data/fastdfs/storage
tracker_server=172.18.10.232:22122
store_path0=/data/fastdfs/storage
http.server_port=8888(默认为8888,nginx中配置的监听端口那之一致)
实验:企业级分布式存储应用与实战fastdfs实现
实验环境:3台机器,一台tracker调度器,两台storage节点服务器
(1)安装fastdfs
1.创建一个安装fastdfs所需软件包的目录
cd /app
mkdir fastdfs
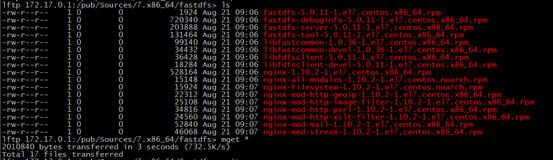
2.用lftp将安装fastdfs所需软件包下载到该目录里
lftp 172.17.0.1
lftp 172.17.0.1:/pub/Sources/7.x86_64/fastdfs> mget *
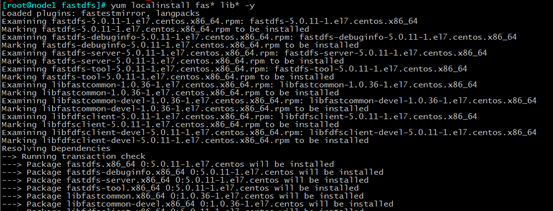
3.安装fastdfs
yum localinstall fastdfs* lib* -y 因为有依赖关系,所以和依赖的库文件包一起安装
4.另外两台机器也是如此
(2)配置tracker调度器
cd /etc/fdfs
cp tracker.conf.sample tracker.conf 在/etc/fdfs目录下有一个tracker配置文件模板,将其复制并改名为tracker.conf作为tarcker的配置文件
vim tracker.conf
disabled=false(默认为false,表示是否无效)
port=22122(默认为22122)
base_path=/data/fastdfs/tracker
mdkir /data/fastdfs/tracker -p
/etc/init.d/fdfs_trackerd start 启动tracker服务
注意:路径和创建的目录要一致,不要写错,否则tracker服务就会起不来
ss -ntl 查看是否有22122端口
ps -ef|grep fdfs 查看tracker进程

(3)配置storage节点服务器
cd /etc/fdfs
cp storage.conf.sample storage.conf 在/etc/fdfs目录下有一个storage配置文件模板,将其复制并改名为storage.conf作为storage的配置文件
vim storage.conf
disabled=false(默认为false,表示是否无效)
port=23000(默认为23000)
base_path=/data/fastdfs/storage
tracker_server=172.18.10.232:22122
store_path0=/data/fastdfs/storage
http.server_port=8888(默认为8888,nginx中配置的监听端口那之一致)
mkdir /data/fastdfs/storage -p
/etc/init.d/fdfs_storaged start 启动storage服务
注意:路径和创建的目录要一致,不要写错,否则storage服务就会起不来
ss -ntl 查看是否有23000端口
ps -ef|grep fdfs

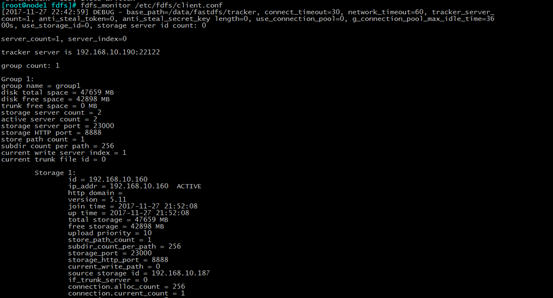
(4)查看存储节点状态,需要配置客户端配置文件
cd /etc/fdfs
cp client.conf.sample client.conf
vim client.conf
base_path=/data/fastdfs/tracker
tracker_server=192.168.10.190:22122
fdfs_monitor /etc/fdfs/client.conf 查看存储节点状态
(5)文件上传
fdfs_upload_file /etc/fdfs/client.conf /root/solo-2.2.0.war

在storage节点服务器上查看
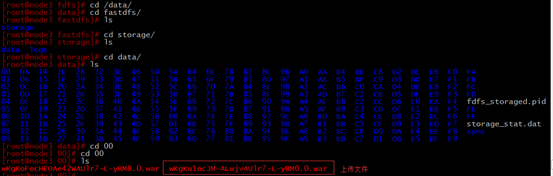
我们可以在tracker调度器上做md5校验
6.上传文件查看(在调度器上查看)
fdfs_file_info /etc/fdfs/client.conf group1/M00/00/00/wKgKu1ocsWGADh40AABakQQUHpk839.log

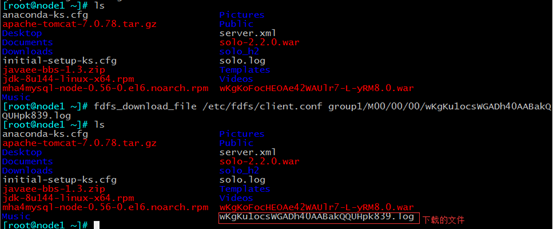
7.文件下载
fdfs_download_file /etc/fdfs/client.conf group1/M00/00/00/wKgKu1ocsWGADh40AABakQQUHpk839.log
8.FastDFS实现nginx代理(在storage节点)
1、安装nginx以及对应模块
cd /app/fastdfs
yum localinstall nginx* -y
2、修改nginx的location配置,映射路径和启动模块
location /group1/M00 {
root /data/fastdfs/storage/data;
ngx_fastdfs_module;
}
3、修改对应fastdfs模块
vim /etc/fdfs/mod_fastdfs.conf
url_have_group_name = true
tracker_server=192.168.10.190:22122
store_path0=/data/fastdfs/storage
4.启动nginx服务
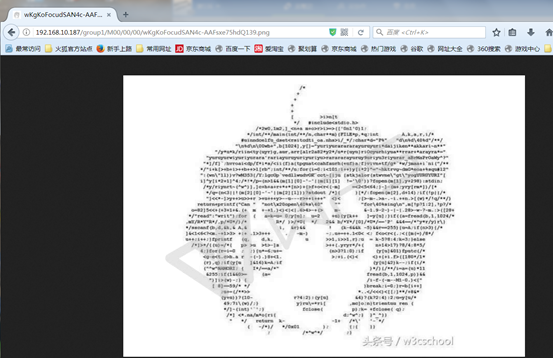
5.然后我上传一个图片文件

6.在浏览器上去访问,访问成功
企业级分布式存储应用与实战FastDFS实现的更多相关文章
- 项目实战9—企业级分布式存储应用与实战MogileFS、FastDFS
企业级分布式存储应用与实战-mogilefs 环境:公司已经有了大量沉淀用户,为了让这些沉淀用户长期使用公司平台,公司决定增加用户粘性,逐步发展基于社交属性的多样化业务模式,决定开展用户讨论区.卖家秀 ...
- 企业级分布式存储应用与实战MogileFS、FastDFS
项目实战9—企业级分布式存储应用与实战MogileFS.FastDFS 目录 实战一:企业级分布式存储应用与实战 mogilefs 实现 原理 1.环境准备 2.下载安装,每个机器都一样 3.数据 ...
- 实验:企业级分布式存储应用与实战-mogilefs实现
实验:企业级分布式存储应用与实战-mogilefs实现 (1)安装mogilefs 1.创建一个存放安装mogilefs所需的软件包的目录 cd /app/ mkdir mogilefs cd mog ...
- 企业级分布式存储应用与实战-mogilefs实现
Mogilefs是什么 MogileFS是一个开源的分布式文件存储系统,由LiveJournal旗下的Danga Interactive公司开发.Danga团队开发了包括 Memcached.Mogi ...
- Mysql实现企业级数据库主从复制架构实战
场景 公司规模已经形成,用户数据已成为公司的核心命脉,一次老王一不小心把数据库文件删除,通过mysqldump备份策略恢复用了两个小时,在这两小时中,公司业务中断,损失100万,老王做出深刻反省,公司 ...
- 项目实战7—Mysql实现企业级数据库主从复制架构实战
Mysql实现企业级数据库主从复制架构实战 环境背景:公司规模已经形成,用户数据已成为公司的核心命脉,一次老王一不小心把数据库文件删除,通过mysqldump备份策略恢复用了两个小时,在这两小时中,公 ...
- JAVA企业级应用服务器之TOMCAT实战
JAVA企业级应用服务器之TOMCAT实战 链接:https://pan.baidu.com/s/1c6pZjLeMQqc9t-OXvUM66w 提取码:uwak 复制这段内容后打开百度网盘手机App ...
- 企业级NginxWeb服务优化实战(下)
企业级NginxWeb服务优化实战(下) 4. Nginx站点目录及文件URL访问控制 4.1 根据扩展名限制程序和文件访问 Web2.0时代,绝大多数网站都是以用户为中心多的,例如:bbs,blog ...
- 企业级NginxWeb服务优化实战(上)
企业级NginxWeb服务优化实战(上) 1. Nginx基本安全优化 1.1 调整参数隐藏Nginx软件版本号信息 一般来说,软件的漏洞都和版本有关,这个很像汽车的缺陷,同一批次的要有问题就都有问题 ...
随机推荐
- Javascript中遍历数组方法的性能对比
Javascript中常见的遍历数组的方法 1.for循环 for(var i = 0; i < arr.length; i++) { // do something. } 2.for循环的改进 ...
- linux系统编辑神器 -vim用法大全
vim编辑器 文本编辑器,字处理器ASCII nano, sed vi: Visual Interfacevim: VI iMproved 全屏编辑器,模式化编辑器 vim模式:编辑模式(命令模式)输 ...
- 设计模式六大原则(PHP)
设计模式的目的是为了更好的代码重用性,可读性,可靠性和可维护性.常用的六大设计模式有:单一职责原则(SRP),里氏替换原则(LSP),依赖倒转原则(DIP),接口隔离原则(ISP),迪米特法则(LOD ...
- nodejs+express+mysql实现restful风格的增删改查示例
首先,放上项目github地址:https://github.com/codethereforam/express-mysql-demo 一.前言 之前学的java,一直用的ssm框架写后台.前段时间 ...
- gitignore样例解析
# 这是注释行 -- 被忽略 *.a # 忽略所有以 .a 为扩展名的文件 !lib.a # 但是lib.a 文件或目录不要忽略,即使前面设置了对*.a的忽略 /TODO # 只忽略此目录下的TODO ...
- Video Target Tracking Based on Online Learning—TLD单目标跟踪算法详解
视频目标跟踪问题分析 视频跟踪技术的主要目的是从复杂多变的的背景环境中准确提取相关的目标特征,准确地识别出跟踪目标,并且对目标的位置和姿态等信息精确地定位,为后续目标物体行为分析提供足 ...
- Android基础_web通信2
一.移动客服端实现对PC端数据的操作 在PC端模拟一个数据库,实现用户的增删改查,然后在移动客服端实现对PC端数据库的操作 在PC端建立三个表 用户表(Users),员工表(Emp), 部门表(Dep ...
- DQN算法
DQN算法:基础入门看看 # -*- coding: utf-8 -*- import random import gym import numpy as np from collections im ...
- 大数据Hadoop学习之了解Hadoop(1)
关于大数据,一看就懂,一懂就懵. 大数据的发展也有些年头了,如今正走在风口浪尖上,作为小白,我也来凑一份热闹. 大数据经过多年的发展,有着不同的实现方案和分支,不过,要说大数据实现方案中的翘楚,那就是 ...
- CTF---Web入门第三题 这个看起来有点简单!
这个看起来有点简单!分值:10 来源: 西普学院 难度:易 参与人数:10515人 Get Flag:3441人 答题人数:4232人 解题通过率:81% 很明显.过年过节不送礼,送礼就送这个 格式: ...