吴恩达深度学习第1课第4周-任意层人工神经网络(Artificial Neural Network,即ANN)(向量化)手写推导过程(我觉得已经很详细了)
学习了吴恩达老师深度学习工程师第一门课,受益匪浅,尤其是吴老师所用的符号系统,准确且易区分.
遵循吴老师的符号系统,我对任意层神经网络模型进行了详细的推导,形成笔记.
有人说推导任意层MLP很容易,我表示怀疑啊.难道又是我智商的问题嘛╮(╯_╰)╭.
推导神经网络, 我用了一天.最后完成了,我就放心了,可以进行下一部分学习了:)
推这玩意是个脏活累活,直接记住向量化表示(结果)也是极好的.
顺便说一下,本文的图片若看不清,可以另存为本地文件放大看(scan的时候我定了较高的精度),更清楚^^
该笔记目的为:记录推导过程,供自己复习.
0. 为推导顺利而总结的经验
该部分内容是我推导后才总结的.但我觉得应该放在最前面,最显眼的位置,里面的内容还是很重要的.

1. 搭建实例,明确符号系统,理顺正向、反向传播过程,明确 loss function
需要说明的是,loss function, dAL和任务有关.
我们模型输出层就1个单元,且为sigmoid单元. (原因是假定模型要跑一个二分类任务)
其他层用什么单元就无所谓了(我们的符号系统都能表示,如\(A^{[l]}=g^{[l]}(Z^{[l]})\)里面的\(g^{[l]}(\cdot)\)表示的就是模型中第\(l\)层所用的 activation function),如 sigmoid, relu, tanh单元或其他改进的relu单元.这些东西在吴老师的课程中都有详细讲解.

2. 考察dAL

3. 与大牛不符之dAL中的\(\frac{1}{m}\)为啥消失了?
dAL中的\(\frac{1}{m}\)为啥消失了?吴老师的推导中是没有\(\frac{1}{m}\)的,而我的推导里是有的.和超级大牛的答案不符,那就是我错了?(我错的地方请指出,谢谢啦)
**这个问题解决了,我的推导是对的!原因是:2017.11.13这天,我正在做吴恩达深度学习工程师第二课第一周编程作业,发现Ng老师提供的init_utils.py文件里的 backward_propagation(X, Y, cache)函数(关于一个三隐层神经网络的反向传播函数)中有这样一句话:dz3 = 1./m * (a3 - Y),因此,我的推导是正确的,dAL应该有\(\frac{1}{m}\)这一项.
另外,根据链式法则,dAL若有1/m,那么后续的 dZ, dW, db就都不需要加1/m了.Andrew Ng 老师第一门课中,虽然 dAL 没有加 1/m,但后续的 dW, db都分别加了 1/m, 结果也是对的.
** init_utils.py的函数 backward_propagation(X, Y, cache)的完整代码如下:
def backward_propagation(X, Y, cache):
"""
Implement the backward propagation presented in figure 2.
Arguments:
X -- input dataset, of shape (input size, number of examples)
Y -- true "label" vector (containing 0 if cat, 1 if non-cat)
cache -- cache output from forward_propagation()
Returns:
gradients -- A dictionary with the gradients with respect to each parameter, activation and pre-activation variables
"""
m = X.shape[1]
(z1, a1, W1, b1, z2, a2, W2, b2, z3, a3, W3, b3) = cache
dz3 = 1./m * (a3 - Y) # <----------- 就是这句话,表明我的推导是正确的.
dW3 = np.dot(dz3, a2.T)
db3 = np.sum(dz3, axis=1, keepdims = True)
da2 = np.dot(W3.T, dz3)
dz2 = np.multiply(da2, np.int64(a2 > 0))
dW2 = np.dot(dz2, a1.T)
db2 = np.sum(dz2, axis=1, keepdims = True)
da1 = np.dot(W2.T, dz2)
dz1 = np.multiply(da1, np.int64(a1 > 0))
dW1 = np.dot(dz1, X.T)
db1 = np.sum(dz1, axis=1, keepdims = True)
gradients = {"dz3": dz3, "dW3": dW3, "db3": db3,
"da2": da2, "dz2": dz2, "dW2": dW2, "db2": db2,
"da1": da1, "dz1": dz1, "dW1": dW1, "db1": db1}
return gradients
我的推导:

4. 假定吴老师正确推导了dAL的前提下,推导dZL

5. \(dZ^{[l]}\)推\(dW^{[l]}\)(上)
推导dW以及后续参数时,我只管每一步有意义(仔细看笔记,您就能明白我的意思),并能编程实现(虽然不是向量化的). 但最后推导的结果是可以向量化表示的(就能向量化编程喽)!
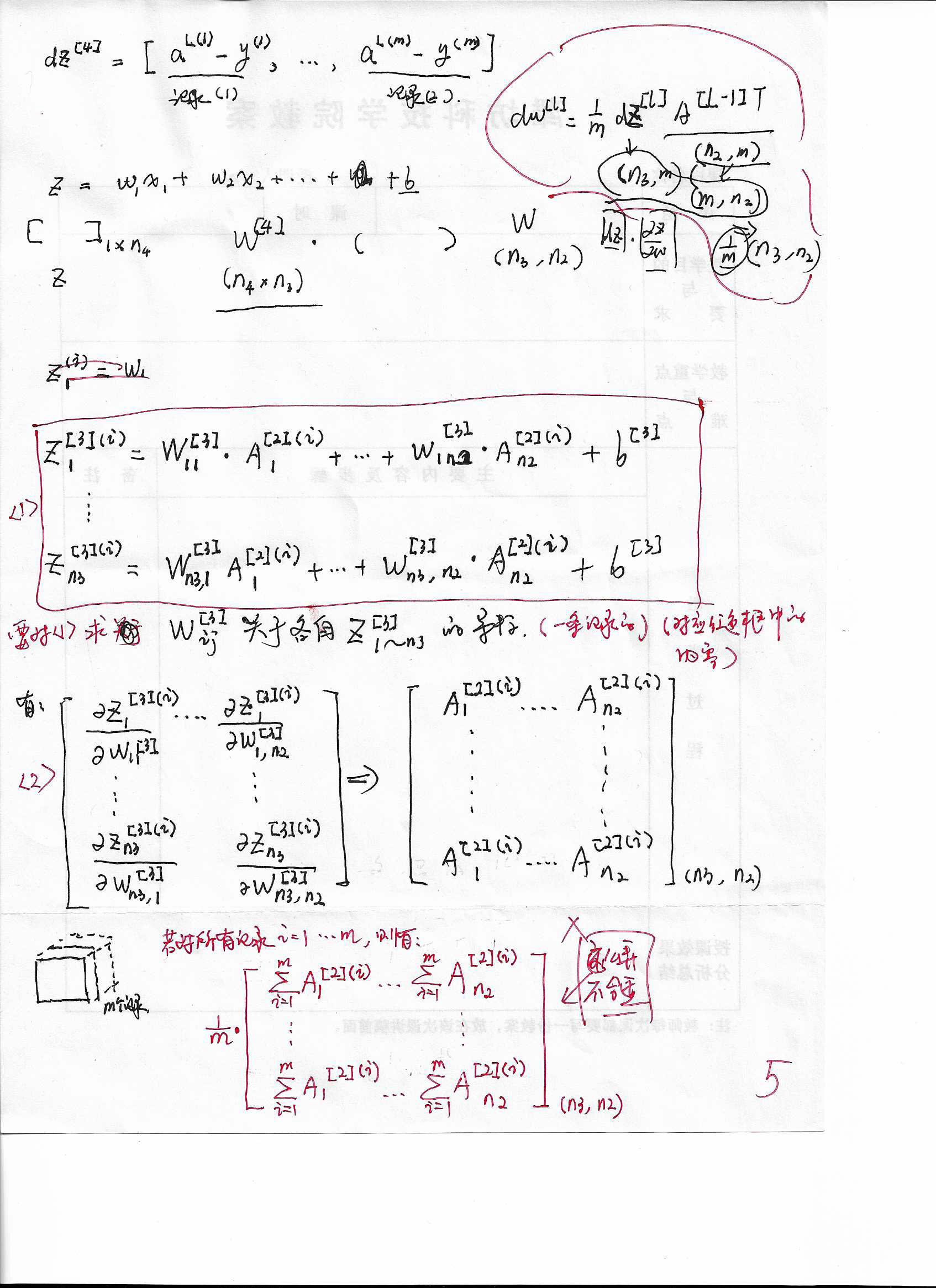
6. \(dZ^{[l]}\)推\(dW^{[l]}\)(中)

7. \(dZ^{[l]}\)推\(dW^{[l]}\)(下)

8. \(dZ^{[l]}\)推\(db^{[l]}\)

9. \(dZ^{[l]}\)推\(dA^{[l-1]}\)(上)

10. \(dZ^{[l]}\)推\(dA^{[l-1]}\)(下)

11. \(dA^{[l]}\)推\(dZ^{[l]}\)

吴恩达深度学习第1课第4周-任意层人工神经网络(Artificial Neural Network,即ANN)(向量化)手写推导过程(我觉得已经很详细了)的更多相关文章
- 吴恩达深度学习第4课第3周编程作业 + PIL + Python3 + Anaconda环境 + Ubuntu + 导入PIL报错的解决
问题描述: 做吴恩达深度学习第4课第3周编程作业时导入PIL包报错. 我的环境: 已经安装了Tensorflow GPU 版本 Python3 Anaconda 解决办法: 安装pillow模块,而不 ...
- 吴恩达深度学习第2课第2周编程作业 的坑(Optimization Methods)
我python2.7, 做吴恩达深度学习第2课第2周编程作业 Optimization Methods 时有2个坑: 第一坑 需将辅助文件 opt_utils.py 的 nitialize_param ...
- 吴恩达深度学习第2课第3周编程作业 的坑(Tensorflow+Tutorial)
可能因为Andrew Ng用的是python3,而我是python2.7的缘故,我发现了坑.如下: 在辅助文件tf_utils.py中的random_mini_batches(X, Y, mini_b ...
- 吴恩达深度学习第1课第3周编程作业记录(2分类1隐层nn)
2分类1隐层nn, 作业默认设置: 1个输出单元, sigmoid激活函数. (因为二分类); 4个隐层单元, tanh激活函数. (除作为输出单元且为二分类任务外, 几乎不选用 sigmoid 做激 ...
- 【Deeplearning.ai 】吴恩达深度学习笔记及课后作业目录
吴恩达深度学习课程的课堂笔记以及课后作业 代码下载:https://github.com/douzujun/Deep-Learning-Coursera 吴恩达推荐笔记:https://mp.weix ...
- 吴恩达深度学习 反向传播(Back Propagation)公式推导技巧
由于之前看的深度学习的知识都比较零散,补一下吴老师的课程希望能对这块有一个比较完整的认识.课程分为5个部分(粗体部分为已经看过的): 神经网络和深度学习 改善深层神经网络:超参数调试.正则化以及优化 ...
- 深度学习 吴恩达深度学习课程2第三周 tensorflow实践 参数初始化的影响
博主 撸的 该节 代码 地址 :https://github.com/LemonTree1994/machine-learning/blob/master/%E5%90%B4%E6%81%A9%E8 ...
- Coursera 吴恩达 深度学习 学习笔记
神经网络和深度学习 Week 1-2 神经网络基础 Week 3 浅层神经网络 Week 4 深层神经网络 改善深层神经网络 Week 1 深度学习的实用层面 Week 2 优化算法 Week 3 超 ...
- 吴恩达深度学习笔记(deeplearning.ai)之卷积神经网络(一)
Padding 在卷积操作中,过滤器(又称核)的大小通常为奇数,如3x3,5x5.这样的好处有两点: 在特征图(二维卷积)中就会存在一个中心像素点.有一个中心像素点会十分方便,便于指出过滤器的位置. ...
随机推荐
- 200行Py代码带你实现"打飞机"
前言 多年前,你我在一起"打飞机".为了实现真正的打飞机,在下一年前踏足帝都学习了无所不能的Python,辣么接下来带你在俩个小时用200行代码学会打飞机. python中提供了一 ...
- python常用运算符
1. / 浮点除法,就算分子分母都是int类型,也返回float类型,比如我们用4/2,返回2.0 2. // 整数除法,根据分子分母的不同组合,返回的值有差异. 正数//正数,取整,比如5//3,返 ...
- python isinstance 函数
isinstance是Python中的一个内建函数 语法: isinstance(object, classinfo) 如果参数object是classinfo的实例,或者object是class ...
- leetcode算法:Island Perimeter
You are given a map in form of a two-dimensional integer grid where 1 represents land and 0 represen ...
- java集合小知识的复习
*Map接口 Map<k,v>接口中接收两个泛型,key和value的两个数据类型 Map中的集合中的元素都是成对存在的每个元素由键与值两部分组成,通过键可以找对所对应的值.值可以重复,键 ...
- Mysql中给有记录的表添加唯一索引
ALTER IGNORE TABLE neeqs ADD UNIQUE KEY `unique` (`seccode`, `enddate`, `f002v`);
- 工作笔记 | Visual Studio 调用 Web Service
引言 最近笔者负责ERP财务系统跟中粮集团财务公司的财务系统做对接,鉴于ERP系统中应付结算单结算量比较大,而且管理相对集中,ERP系统与中粮财务公司的支付平台系统对接,实现银企直联,将网银录入的环节 ...
- ThreadLocal原理分析与使用场景
什么是ThreadLocal变量 ThreadLoal 变量,线程局部变量,同一个 ThreadLocal 所包含的对象,在不同的 Thread 中有不同的副本.这里有几点需要注意: 因为每个 Thr ...
- [LeetCode] Prime Number of Set Bits in Binary Representation 二进制表示中的非零位个数为质数
Given two integers L and R, find the count of numbers in the range [L, R] (inclusive) having a prime ...
- [LeetCode] Second Minimum Node In a Binary Tree 二叉树中第二小的结点
Given a non-empty special binary tree consisting of nodes with the non-negative value, where each no ...