Spark性能优化总结
1. 避免重复加载RDD
比如一份从HDFS中加载的数据 val rdd1 = sc.textFile("hdfs://url:port/test.txt"),这个test.txt只应该在你的程序中被加载一次,避免多次加载造成的性能开销。
2. 重复使用的RDD需要被缓存
Spark有数据持久化的几种策略,可以将RDD中的数据保存到内存或者磁盘中,后续对这个RDD的操作不会根据RDD lineage重新计算,而是直接从缓存中提取。
如果要对一个RDD进行持久化,只需要对这个RDD调用cache()和persist(),cache()方法表示:使用非序列化的方式将RDD中的数据全部尝试持久化到内存中,
但是生产环境中处理的数据量往往很难全部存储在内存中,需注意虚拟机OOM;persist()方法表示需要手动选择StorageLevel(持久化级别),并使用指定的方式
进行持久化,如序列化到磁盘等(注意,有时候数据全部序列化到磁盘比重新计算一次更慢!)
3. 警惕shuffle操作性能问题
类似MapReduce中的shuffle过程(MapReduce浅析),同一个父RDD的分区传入到不同的子RDD分区中,shuffle过程往往会造成跨节点数据传输(即官网所说的宽依赖问题):
各个节点上的相同key首先写入本地磁盘文件中,然后其他节点需要通过网络根据路由函数传输拉取各个节点上的磁盘文件中的相同key。而且相同key都拉取到同一个节点进行聚合
操作时,还有可能会因为一个节点上处理的key过多,导致内存不够存放,溢写到磁盘文件中。。
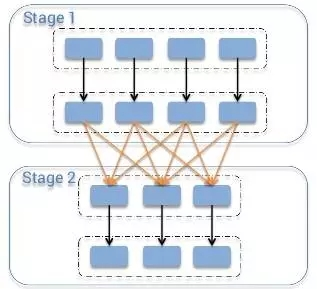
图1.Spark的shuffle过程
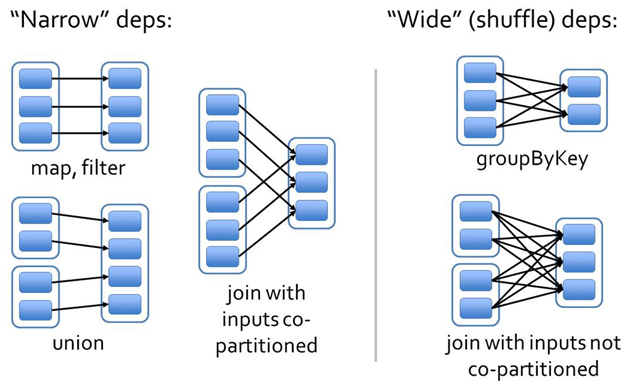
图2. 宽依赖和窄依赖
解决方式有以下两种:
1. 如果可以,先使用filter对RDD先做一定程度的 ‘缩小’
2. 在Map端预先对数据进行聚合,类似传统MapReduce中的Combiner,在Spark中使用reduceByKey或者aggregateByKey会对数据在Map端聚合,
反之,groupByKey会导致全部数据在集群中跨节点传输,性能较差。
4. 广播变量
类似于MapReduce中的DistributeCache。默认情况下Spark会将程序中依赖的变量复制多个副本,分发到各个task中,每个task都有一个副本。如果
变量本身比较大的话,那么大量的变量副本在网络中传输的性能开销,以及在各个节点的Executor中占用过多内存导致的频繁GC,都会极大地影响性能。
而Spark中的广播变量作用是一个Executor中的所有task共享一个副本。
5. 序列化
Spark可以使用Kryo优化序列化过程。
Spark性能优化总结的更多相关文章
- 【转载】Spark性能优化指南——高级篇
前言 数据倾斜调优 调优概述 数据倾斜发生时的现象 数据倾斜发生的原理 如何定位导致数据倾斜的代码 查看导致数据倾斜的key的数据分布情况 数据倾斜的解决方案 解决方案一:使用Hive ETL预处理数 ...
- 【转载】 Spark性能优化指南——基础篇
转自:http://tech.meituan.com/spark-tuning-basic.html?from=timeline 前言 开发调优 调优概述 原则一:避免创建重复的RDD 原则二:尽可能 ...
- 【转】【技术博客】Spark性能优化指南——高级篇
http://mp.weixin.qq.com/s?__biz=MjM5NjQ5MTI5OA==&mid=2651745207&idx=1&sn=3d70d59cede236e ...
- 【转】Spark性能优化指南——基础篇
http://mp.weixin.qq.com/s?__biz=MjM5NDMwNjMzNA==&mid=2651805828&idx=1&sn=2f413828d1fdc6a ...
- Spark性能优化指南——高级篇(转载)
前言 继基础篇讲解了每个Spark开发人员都必须熟知的开发调优与资源调优之后,本文作为<Spark性能优化指南>的高级篇,将深入分析数据倾斜调优与shuffle调优,以解决更加棘手的性能问 ...
- Spark性能优化指南——基础篇(转载)
前言 在大数据计算领域,Spark已经成为了越来越流行.越来越受欢迎的计算平台之一.Spark的功能涵盖了大数据领域的离线批处理.SQL类处理.流式/实时计算.机器学习.图计算等各种不同类型的计算操作 ...
- Spark性能优化指南-高级篇
转自https://tech.meituan.com/spark-tuning-pro.html,感谢原作者的贡献 前言 继基础篇讲解了每个Spark开发人员都必须熟知的开发调优与资源调优之后,本文作 ...
- Spark性能优化指南——基础篇
本文转自:http://tech.meituan.com/spark-tuning-basic.html 感谢原作者 前言 在大数据计算领域,Spark已经成为了越来越流行.越来越受欢迎的计算平台之一 ...
- Spark性能优化指南——高级篇
本文转载自:https://tech.meituan.com/spark-tuning-pro.html 美团技术点评团队) Spark性能优化指南——高级篇 李雪蕤 ·2016-05-12 14:4 ...
- Spark记录-Spark性能优化解决方案
Spark性能优化的10大问题及其解决方案 问题1:reduce task数目不合适解决方式:需根据实际情况调节默认配置,调整方式是修改参数spark.default.parallelism.通常,r ...
随机推荐
- 【Luogu3919】可持久化数组(主席树)
题面戳我 题解 放一个板子在这里 用主席树维护一下每个版本就可以啦... #include<iostream> #include<cstdio> #include<cst ...
- Linux中“is not in the sudoers file”解决方法
当在终端执行sudo命令时,系统提示"hadoop is not in the sudoers file": 其实就是没有权限进行sudo,解决方法如下(这里假设用户名是cuser ...
- python数据库连接池设计
一.背景: 传统访问资源,一般分为一下几个步骤: 1.实例数据驱动对象与链接资源.2.实例操作资源游标.3.获取资源.4.关闭链接资源. 根据以上步骤,我们可以很简单使用这个原始方法来访问资源为我们业 ...
- python自动拉取备份压缩包并删除3天前的旧备份
业务场景,异地机房自动拉取已备份好的tar.gz数据库压缩包,并且只保留3天内的压缩包文件,用python实现 #!/usr/bin/env python import requests,time,o ...
- 【Unity与23种设计模式】访问者模式(Visitor)
GoF中定义: "定义一个能够在一个对象结构中对于所有元素执行的操作.访问者让你可以定义一个新的操作,而不必更改到被操作元素的类接口." 暂时没有完全搞明白 直接上代码 //访问者 ...
- 使用Quartz 2D擦除图片
Quartz 2D 是一个强大的二位图像绘制引擎,在开发中如果遇到需要高度自定义的控件,我们就可能需要用Core Graphics进行绘制. 这几天一同事开发一个聊天中的一个子模块,A 画一幅图,然后 ...
- 部署Flask项目到腾讯云服务器CentOS7
部署Flask项目到腾讯云服务器CentOS7 安装git yum install git 安装依赖包 支持SSL传输协议 解压功能 C语言解析XML文档的 安装gdbm数据库 实现自动补全功能 sq ...
- 手把手的SpringBoot教程,SpringBoot创建web项目(五)
这一节,我们来演示如何在SpringBoot项目中连接数据库,并且自动创建一张表. 按照惯例,数据库我们依然使用mysql,至于什么是jpa呢? jpa是sun推出的持久化规范(java persis ...
- Vue之九数据劫持实现MVVM的数据双向绑定
vue是通过数据劫持的方式来做数据绑定的,其中最核心的方法便是通过Object.defineProperty()来实现对属性的劫持,达到监听数据变动的目的. 如果不熟悉defineProperty,猛 ...
- Java DualPivotQuickSort 双轴快速排序 源码 笔记
DualPivotQuicksort source code 这个算法是Arrays.java中给基本类型的数据排序使用的具体实现.它针对每种基本类型都做了实现,实现的方式有稍微的差异,但是思路都是相 ...