python学习笔记——爬虫中提取网页中的信息
1 数据类型
网页中的数据类型可分为结构化数据、半结构化数据、非结构化数据三种
1.1 结构化数据
常见的是MySQL,表现为二维形式的数据
1.2 半结构化数据
是结构化数据的一种形式,并不符合关系型数据库或其他数据表的形式关联起来的数据模型结构,但包含相关标记,用来分隔语义元素以及对记录和字段进行分层。因此,它也被称为自描述的结构。常见的半结构数据有HTML,XML和JSON等,实际上是以树或者图的结构来存储的。
<person>
<name>A</name>
<age>13</age>
<class>aid1710</class>
<gender>female</gender>
</person>
结点中属性的顺序是不重要的,不同的半结构化数据的属性的个数是不一定一样的。
这样的数据格式,可以自由地表达很多有用的信息,包括自描述信息(元数据)。所以,半结构化数据的扩展性很好,特别适合于在互联网中大规模传播。
1.3 非结构化数据
就是没有固定结构的数据。各种文档、图片、视频/音频等都属于非结构化数据。对于这类数据,我们一般直接整体进行存储,而且一般存储为二进制的数据格式;除了结构化和半结构数据之外的数据都是非结构化数据
2 关于XML,HTML,DOM和JSON文件
2.1 XML
XML(Extentsible Markup Language)(可扩展标记语言),是用来定义其它语言的一种元语言,其前身是SGML(标准通用标记语言)。它没有标签集(tagset),也没有语法规则(grammatical rule),但是它有句法规则(syntax rule)。任何XML文档对任何类型的应用以及正确的解析都必须是良构的(well-formed),即每一个打开的标签都必须有匹配的结束标签,不得含有次序颠倒的标签,并且在语句构成上应符合技术规范的要求。XML文档可以是有效的(valid),但并非一定要求有效。所谓有效文档是指其符合其文档类型定义(DTD)的文档。如果一个文档符合一个模式(schema)的规定,那么这个文档是模式有效的(schema valid)。
2.2 HTML
HTML(Hyper Text Mark-up Language)即超文本标记语言,是WWW的描述语言。
2.3 DOM
文档对象模型(Document Object Model,简称DOM),是W3C组织推荐的处理可扩展标志语言的标准编程接口。在网页上,组织页面(或文档)的对象被组织在一个树形结构中,用来表示文档中对象的标准模型就称为DOM
2.4 JSON
JSON(JavaScript Object Notation, JS对象标记) 是一种轻量级的数据交换格式。它基于 ECMAScript (w3c制定的JS规范)的一个子集,采用完全独立于编程语言的文本格式来存储和表示数据。简洁和清晰的层次结构使得 JSON 成为理想的数据交换语言。 易于人阅读和编写,同时也易于机器解析和生成,并有效地提升网络传输效率。
JSON是 JS对象的字符串表示法,它使用文本表示一个 JS 对象的信息,本质是一个字符串
3 提取网页中的信息
3.1 安装lxml库
lxml的官方文档:http://lxml.de/index.html
lxml是一个用来处理XML的第三方python库,它在底层封装了由C语言编写的libxml和libxslt,并以建档强大的python API,兼容Element Tree API。
lxml库的安装:
(一)Linux条件下安装lxml
(1)安装系统
CentOS,redHat
(2)安装步骤
wget --no-check-certificate https://github.com/pypa/pip/archive/1.5.5.tar.gz
tar zvxf 1.5.5.tar.gz
cd pip-1.5.5/
python setup.py install
(3)安装依赖库
yum install libxml2
yum install libxslt-devel
(4)安装lxml
pip install lxml
(5)问题及处理方式
(a)处理 error: command 'gcc' failed with exit status 1
yum install gcc python-devel 或 yum install gcc libffi-devel python-devel openssl-devel
(b)处理 from setuptools import setup, find_packages ImportError: No module named set
wget http://peak.telecommunity.com/dist/ez_setup.py
python ez_setup.py
(二)windows条件下安装
(1)以管理员身份打开 “ 命令提示符 ” (注:已经安装 Anaconda)
否则会报错:Consider using the `--user` option or check the permissions.
(2)首先安装 ipykernel :pip install ipykernel
否则在安装lxml时会报错:
notebook 5.4.0 requires ipykernel, which is not installed.
jupyter 1.0.0 requires ipykernel, which is not installed.
jupyter-console 5.2.0 requires ipykernel, which is not installed.
ipywidgets 7.1.1 requires ipykernel>=4.5.1, which is not installed.
(3)安装lxml pip install lxml。
另外,网上还有一种解决办法,
用于Python扩展包的非官方Windows二进制文件(Unofficial Windows Binaries for Python Extension Packages)文件上cp标识版本号,cp后面是Python的版本号,27表示2.7,根据你的Python版本选择下载。
原文件:win7上 python 安装 lxml,解决各种python库无法安装的问题,直接安装编译文件
python 安装lxml 问题与办法(Linux和Windows均有涉及)
3.2 lxml的应用
使用示例:
from lxml import etree
xml = """<bookstore>
<book>
<title lang="en">Harry Potter</title>
</book>
</bookstore>
"""
root = etree.fromstring(xml)
print(root) #<Element bookstore at 0xa6af6c8>
而不是
import lxml
xml = """<bookstore>
<book>
<title lang="en">Harry Potter</title>
</book>
</bookstore>
"""
root = lxml.etree.fromstring(xml) #此处报错,module 'lxml' has no attribute 'etree'
print(root)
原因
Help on package lxml:
NAME
lxml - # this is a package
PACKAGE CONTENTS # 包装内容
ElementInclude
_elementpath
builder
cssselect
doctestcompare
etree
html (package)
includes (package)
isoschematron (package)
objectify
pyclasslookup
sax
usedoctest
FUNCTIONS #函数/方法
get_include()
Returns a list of header include paths (for lxml itself, libxml2
:
注意“库”和‘类’的区别。在库中的包装内容PACKAGE CONTENTS是无法通过直接引用的,如lxml.etree会报错一样。
实际上导入lxml库时,尽可以直接使用lxml.get_incude()方法。

lxml的包装内容可以通过from lxml import etree 的方式导入包装内容
3. 2 XPath
安装:pip install lxml
使用:from lxml import etree
(1)XPath是一门在XML文档中查找信息的语言,是通过XML中的元素和属性进行遍历查询的
(2)XPath使用路径表达式来选取XML文档中的节点或节点集
(3)XPath包含一个标准函数库,超过100个内建的函数,这些函数用于字符串值、数值、日期和时间比较、节点和QName处理、序列处理、逻辑值等
3.2.1 XPath节点
在XPath语境中,XML 文档被视作节点树,节点树的根节点也被称作文档节点。
XPath 将节点树中的节点(Node)分为七类:
元素(Element)
属性(Attribute)
文本(Text)
命名空间(Namespace)
处理指令(Processing-instruction)
注释(Comment)
文档节点(Document nodes)。
看一下 XML 文档例子:
<?xml version="1.0" encoding="ISO-8859-1"?> <bookstore> <book> <title lang="en">Harry Potter</title> <author>J K. Rowling</author> <year>2005</year> <price>29.99</price> </book> </bookstore>
以上的XML文档中:
<bookstore> (“根”)
<author>J K. Rowling</author> (“元素”)
lang="en" (“属性”)
text = J K. Rowling(“文本”)
3.2.2 节点之间的关系
父(Parent):每个元素都有一个父节点,最顶层父节点为根节点;每个属性也都有一个父节点,其父节点为该属性修饰的元素。
子(Children):元素都有0个或多个子节点。
同胞(Sibling):同一个父节点的子节点互称为同胞
先辈(Ancestor):某节点的父节点(含)以上的所有节点
后代(Descendant):某节点的子节点(含)以下的所有节点
3.2.3 选取节点
基本路径表达式,其与Linux环境中路径切换原理是一样的;XPath的路径表达都是基于某个节点的,一般最初的当前节点为根节点。
表达式描述:
nodename:已匹配节点下名为nodename的子节点
/ :如果以 / 开头,表示从根节点作为选取起点。
// :在已匹配节点后代中选取节点,不考虑目标节点的位置。
. :选取当前节点。
.. :选取当前节点的父元素节点。
@ :选取属性。
3.2.4 通配符
* : 匹配任何元素。
@* :匹配任何属性。
node():匹配任何类型的节点。
3.2.5 预判(Predicates)或 条件选取
预判是用来查找某个特定的节点或者符合某种条件的节点,预判表达式位于方括号中。使用 “|” 运算符,你可以选取符合“或”条件的若干路径。
3.2.6 坐标轴
XPath 坐标轴:坐标轴用于定义当对当前节点的节点集合。
坐标轴名称 含义
ancestor 选取当前节点的所有先辈元素及根节点。
ancestor-or-self 选取当前节点的所有先辈以及当前节点本身。
ttibute 选取当前节点的所有属性。
child 选取当前节点的所有子元素。
descendant 选取当前节点的所有后代元素。
descendant-or-self 选取当前节点的所有后代元素以及当前节点本身。
following 选取文档中当前节点的结束标签之后的所有节点。
following-sibling 选取当前节点之后的所有同级节点。
namespace 选取当前节点的所有命名空间节点。
parent 选取当前节点的父节点。
preceding 选取当前节点的开始标签之前的所有节点。
preceding-sibling 选取当前节点之前的所有同级节点。
self 选取当前节点。
3.2.7 位置路径的表达式
位置路径可以是绝对路径,也可以是相对路径。绝对路径以“/” 开头。每条路径包括一个或多个步,每步之间以“/”分隔。
绝对路径:/step/step/…
相对路径:step/step/…
每步根据当前节点集合中的节点计算。
步(step)包括三部分:
坐标轴(axis): 定义所选节点与当前节点之间的关系。
节点测试(node-test):识别某个坐标轴内部的节点。
预判(predicate): 提出预判条件对节点集合进行筛选。
4 示例
(1)fromstring 和 XPath 的应用
from lxml import etree
xml = """<bookstore>
<book>
<title lang="en">Harry Potter</title>
<price>29.99</price>
<pageNumer>102</pageNumer>
</book>
<book>
<title lang="ch">Python爬虫</title>
<price>39.9</price>
</book>
</bookstore>
"""
root = etree.fromstring(xml)
print(root) #<Element bookstore at 0xa6af6c8>
# 不关心节点层次关系的细节,取属性
elements = root.xpath("//@lang")
print(elements)
运行
<Element bookstore at 0x7fcc4d101bc8> ['en', 'ch']
注:关于xpath的定位可以在网页中直接找出
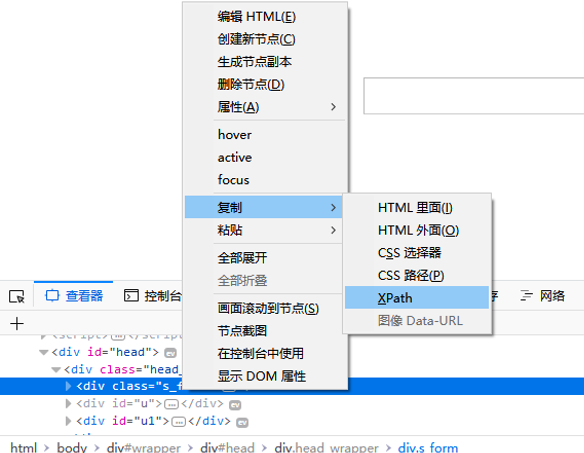
将其取出后直接填在xpath中
from lxml import etree
xml = """<bookstore>
<book>
<title lang="en">Harry Potter</title>
<price>29.99</price>
<pageNumer>102</pageNumer>
</book>
<book>
<title lang="ch">Python爬虫</title>
<price>39.9</price>
</book>
</bookstore>
"""
root = etree.fromstring(xml)
取price的text信息
priceElements = root.xpath("/bookstore/book[price>35]/title")
for i in priceElements:
print(i.text)
运行 Python爬虫
(2) 其他属性
from lxml import etree
xml = """<bookstore>
<book>
<title lang="en">Harry Potter</title>
<price>29.99</price>
<pageNumer>102</pageNumer>
</book>
<book>
<title lang="ch">Python爬虫</title>
<price>39.9</price>
</book>
</bookstore>
"""
root = etree.fromstring(xml)
# book element
c1 = root.getchildren()[0]
print(c1) # <Element book at 0x7f7e1158ac48>
cc1 = c1.getchildren()[0]
print(cc1.text) # Harry Potter
print(cc1.attrib) # {'lang': 'en'}
cc1c = c1.getchildren()[2]
c2 = root.getchildren()[1]
cc2 = c2.getchildren()[0]
print(cc2.text) #Python爬虫
print(cc2.attrib) #{'lang': 'ch'}
python学习笔记——爬虫中提取网页中的信息的更多相关文章
- python学习笔记——爬虫学习中的重要库urllib
1 urllib概述 1.1 urllib库中的模块类型 urllib是python内置的http请求库 其提供了如下功能: (1)error 异常处理模块 (2)parse url解析模块 (3)r ...
- [Python学习笔记]爬虫
要使用Python 抓取网页,首先我们要学习下面四个模块: 包 作用 webbrowser 打开浏览器获取指定页面: requests 从因特网下载文件和网页: Beautiful Soup 解析HT ...
- python学习笔记二:(python3 logging函数中format说明)
背景,在学习logging时总是遇到无法理解的问题,总结,尝试一下更清晰明了了,让我们开始吧! logging模块常用format格式说明 %(levelno)s: 打印日志级别的数值 %(level ...
- Python学习笔记:关于脚本文件中的 if __name__ = '__main__'
这两天自己写了一个Python脚本文件,但是直接运行这个.py之后发现里面的函数并没有执行,参考别人的代码之后,发现原来要加入以下代码: if name == 'main': 函数名1 函数名2 .. ...
- Python学习笔记(三)——文件系统中的常用方法
OS模块中关于文件/目录常用的函数使用方法 函数名 使用方法 getcwd() 返回当前工作目录 chdir() 改变工作目录 listdir(path='.') 列举指定目录中的文件名('.'表示当 ...
- 【Python学习笔记七】从配置文件中读取参数
将一些需要更改或者固定的内容存放在配置文件中,通过读取配置文件来获取参数,这样修改以及使用起来比较方便 1.首先是配置文件的写法如下一个environment.ini文件: 里面“[]”存放的是sec ...
- python学习笔记--Django入门一 网页显示时间
我的笔记是学习http://djangobook.py3k.cn/ 课程时做的,这个上边的文章讲的确实是非常的详细,非常感谢你们提供的知识. 上一篇随笔中已经配置好了Django环境,现在继续跟随ht ...
- Python学习笔记之爬取网页保存到本地文件
爬虫的操作步骤: 爬虫三步走 爬虫第一步:使用requests获得数据: (request库需要提前安装,通过pip方式,参考之前的博文) 1.导入requests 2.使用requests.get ...
- Python学习笔记五(读取提取写入文件)
#Python打开读取一个文件内容,然后写入一个新的文件中,并对某些字段进行提取,写入新的字段的脚本,与大家共同学习. import os import re def get_filelist(dir ...
随机推荐
- [JUnit] Introduce to Junit and it annotations
Check the get started guid https://junit.org/junit5/docs/current/user-guide/#overview-getting-help p ...
- [React] Validate React Forms with Formik and Yup
Validating forms in React can take several lines of code to build. However, Formik's ErrorMessage co ...
- artTemplate子模板include
art.Template:https://github.com/aui/art-template 下面来实现利用模版来实现递归调用生成tree <script type="text/h ...
- 5个经典的JavaScript面试题
在IT界中公司对JavaScript开发者的要求还是比较高的,但是如果JavaScript开 发者的技能和经验都达到了一定的级别,那他们还是很容易跳到优秀的公司的,当然薪水就更不是问题了.但是在面试之 ...
- php基础系列:从用户登录处理程序学习mysql扩展基本操作
用户注册和登录是网站开发最基本的功能模块之一,现在通过登录处理程序代码来学些下php对mysql的基本操作. 本身没有难点,主要是作为开发人员,应该能做到手写这些基本代码,算是自己加强记忆,同时希望能 ...
- iPad Air 2全然评測:可怕的三核CPU、六核GPU
在了解了三核心A8X的基本情况后.我们再来通过測试数据,全面地了解一下iPad Air 2的性能表现,包含CPU.GPU.存储.电池.屏幕.摄像头.导航等等. [CPU性能測试:三核太可怕了] 移动处 ...
- 玩转Bootstrap
一:bootstrap基本模版 <!DOCTYPE html> <html lang="en"> <head> <meta charset ...
- ORA-00942 表或视图不存在
场景:跨scheme创建视图,提示ORA-00942 表或视图不存在 1. 创建两个用户 CREATE USER ODI_SRC IDENTIFIED BY ODI_SRC CREATE USER O ...
- oracle列自增实现(1)-Sequence+Trigger实现Oracle列自增
Sequence+Trigger实现Oracle列自增 序列的语法格式为: CREATE SEQUENCE 序列名 [INCREMENT BY n] [START WITH n] [{MAXVALUE ...
- Spring Aspect实现AOP切面
百度搜索的大部分的文章(demo)都只是对简单的方法进行切面(例如:public String say(String name)),却未介绍在入参是不固定的时候改怎么处理,后来查到可以使用org.as ...