C# 高性能的数组 高性能数组队列实战 HslCommunication的SharpList类详解
本文将使用一个gitHub开源的组件技术来实现这个功能
github地址:https://github.com/dathlin/HslCommunication 
 如果喜欢可以star或是fork,还可以打赏支持。
如果喜欢可以star或是fork,还可以打赏支持。
官网地址:http://www.hslcommunication.cn/ 打赏请认准官网
场景需求
我们会有对缓存数据的需求。C#本身提供了固定长度的数组 T[] , 可变长度的List<T> 当然还有先入先出,后入后出的队列。
通常实际中,我们需要维护一个缓存的数组队列,比如一个int数组,长度为1000个,当我们读取到数据后,需要往里面添加数据,然后所有的数据都是往左挪动。最后这个数据是线程安全的操作。
第一种写法,就是循环挪动数据:
int[] buffer = new int[1000];
hybirdLock.Enter( );
for (int j = 0; j < buffer.Length - 1; j++)
{
buffer[j] = buffer[j + 1];
}
buffer[999] = 100;
hybirdLock.Leave( );
第二种写法,批量挪动数据
int[] buffer = new int[1000];
hybirdLock.Enter( );
int[] newbuffer = new int[1000];
Array.Copy( buffer, 0, newbuffer, 0, 999 );
newbuffer[999] = 100;
buffer = newbuffer;
hybirdLock.Leave( );
第三种写法,就是List泛型类,和先入先出的用法差不多
int[] buffer = new int[1000];
List<int> list = new List<int>( buffer ); hybirdLock.Enter( ); list.Add( 100 );
list.RemoveAt( 0 ); hybirdLock.Leave( );
第四种写法:SharpList<T> 类型实现
SharpList<int> sharpList = new SharpList<int>( 1000, true );
sharpList.Add( 1000 );
初步对比,SharpList代码上更加精简。因为内置了线程安全,自动挪动数据。
上述代码我们定义了一个长度为1000的int类型的数组对象。实例化之后,其本身就是一个1000个长度的 int[] 数组,当 Add(100);时,最右侧就多了一个100的数据。
SharpList<T> 提供了几个方法来方便快捷的操作数据。比如根据索引为访问:
int value = sharpList[0]; // 得到0
int value2 = sharpList[999]; // 得到100 int[] tmp = sharpList.ToArray(); // 得到数组数据的副本。[0,,,,,,,,,,999]
当新增数据的时候,也支持批量的新增。
性能对比
我们将上述的四种方式各自运行100W次,查看下各自的性能差异,具体运行时间取决于cpu型号,内存,等因数,此处仅仅是一个参考。
SimpleHybirdLock hybirdLock = new SimpleHybirdLock( );
int[] buffer = new int[1000];
DateTime start = DateTime.Now;
for (int i = 0; i < 1000000; i++)
{
hybirdLock.Enter( );
for (int j = 0; j < buffer.Length - 1; j++)
{
buffer[j] = buffer[j + 1];
}
buffer[999] = i;
hybirdLock.Leave( );
}
Console.WriteLine( (DateTime.Now - start).TotalMilliseconds );
start = DateTime.Now;
for (int i = 0; i < 1000000; i++)
{
hybirdLock.Enter( );
int[] newbuffer = new int[1000];
Array.Copy( buffer, 0, newbuffer, 0, 999 );
newbuffer[999] = i;
buffer = newbuffer;
hybirdLock.Leave( );
}
Console.WriteLine( (DateTime.Now - start).TotalMilliseconds );
List<int> list = new List<int>( buffer );
start = DateTime.Now;
for (int i = 0; i < 1000000; i++)
{
hybirdLock.Enter( );
list.Add( i );
list.RemoveAt( 0 );
hybirdLock.Leave( );
}
Console.WriteLine( (DateTime.Now - start).TotalMilliseconds );
SharpList<int> sharpList = new SharpList<int>( 1000, true );
start = DateTime.Now;
for (int i = 0; i < 1000000; i++)
{
sharpList.Add( i );
}
Console.WriteLine( (DateTime.Now - start).TotalMilliseconds );
int[] data = sharpList.ToArray( );
Console.ReadLine( );
我们跑三次,对比结果。


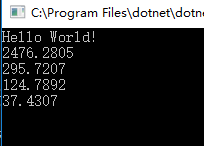
我们看到SharpList<T> 类仅仅消耗了37ms,完成了100W次数据的新增和挪动。
为什么会有那么大的性能差异呢?就要深入源代码查看了。
深度剖析
超高的性能的本质在于减少大块的数据移动,先内部实例化一个远比需求还大的多的数据对象
array = new T[capacity + count];
当有数据新增进来的时候,实际不需要移动
/// <summary>
/// 新增一个数据值
/// </summary>
/// <param name="value">数据值</param>
public void Add( T value )
{
hybirdLock.Enter( ); if(lastIndex < (capacity + count))
{
array[lastIndex++] = value;
}
else
{
// 需要重新挪位置了
T[] buffer = new T[capacity + count];
Array.Copy( array, capacity, buffer, 0, count );
array = buffer;
lastIndex = count;
} hybirdLock.Leave( );
}
先进行自然的赋值,这时的性能就非常快了,然后提高游标的索引。当缓存都不够时,再去复制挪动一次数据。
当然,当要获取数据时,就需要进行根据当前的活动游标进行获取到正确的数据。
/// <summary>
/// 获取数据的数组值
/// </summary>
/// <returns>数组值</returns>
public T[] ToArray( )
{
T[] result = null;
hybirdLock.Enter( ); if (lastIndex < count)
{
result = new T[lastIndex];
Array.Copy( array, 0, result, 0, lastIndex );
}
else
{
result = new T[count];
Array.Copy( array, lastIndex - count, result, 0, count );
}
hybirdLock.Leave( );
return result;
}
相关的话题,后续补充。
C# 高性能的数组 高性能数组队列实战 HslCommunication的SharpList类详解的更多相关文章
- 最佳实战Docker持续集成图文详解
最佳实战Docker持续集成图文详解 这是一种真正的容器级的实现,这个带来的好处,不仅仅是效率的提升,更是一种变革:开发人员第一次真正为自己的代码负责——终于可以跳过运维和测试部门,自主维护运行环境( ...
- shell编程系列23--shell操作数据库实战之mysql命令参数详解
shell编程系列23--shell操作数据库实战之mysql命令参数详解 mysql命令参数详解 -u 用户名 -p 用户密码 -h 服务器ip地址 -D 连接的数据库 -N 不输出列信息 -B 使 ...
- Redis实战 | 5种Redis数据类型详解
我们知道Redis是目前非常主流的KV数据库,它因高性能的读写能力而著称,其实还有另外一个优势,就是Redis提供了更加丰富的数据类型,这使得Redis有着更加广泛的使用场景.那Redis提供给用户的 ...
- PHP数组的交集array_intersect(),array_intersect_assoc(),array_inter_key()函数详解
求两个数组的交集问题可以使用 array_intersect(),array_inersect_assoc,array_intersect_key来实现,其中 array_intersect()函数是 ...
- 遍历查找集合或者数组中的某个元素的值 java代码 详解 Android开发
import java.util.Scanner; public class Test21 { public static void main(String[] args) { //定义并初始化数组 ...
- Kafka高性能揭秘:sequence IO、PageCache、SendFile的应用详解
大家都知道Kafka是将数据存储于磁盘的,而磁盘读写性能往往很差,但Kafka官方测试其数据读写速率能达到600M/s,那么为什么Kafka性能会这么高呢? 首先producer往broker发送消息 ...
- Hadoop实战之二~ hadoop作业调度详解(1)
对Hadoop的最感兴趣的地方,也就在于Hadoop的作业调度了,在正式介绍如何搭建Hadoop之前,深入理解一下Hadoop的作业调度很有必要.我们不一定能用得上Hadoop,但是如果理通顺Hado ...
- reactjs入门到实战(五)---- props详解
1>>>基础的props使用 不可修改父属性 getDefaultProps 对于外界/父组件的属性值,无法直接修改,它是只读的. <script type= ...
- reactjs入门到实战(四)---- state详解
this.props 表示那些一旦定义,就不再改变的特性,而 this.state 是会随着用户互动而产生变化的特性. 组件免不了要与用户互动,React 的一大创新,就是将组件看成是一个状态机,一开 ...
随机推荐
- Java中带标签的break,continue
首先不带标签的break,continue 就不介绍了.大家平时用的最多的也就是这样的情况了. 首先Java中没有goto,但是可以利用带标签的break, continue来实现类似的跳转. 首先来 ...
- Python 获取文件的创建时间,修改时间和访问时间
# 用到的知识# os.path.getatime(file) 输出文件访问时间# os.path.getctime(file) 输出文件的创建时间# os.path.getmtime(file) 输 ...
- Jmeter高阶学习,运用NotePad++编写工程,随意复制多个工程到同一个工程
Jmeter创建了工程之后,保存文件后就是一个jmx后缀的文件,你有没有试过单独用文本编辑器打开文件,编辑文件? Step1: 最简单的Jmeter工程,只有一个测试计划 <?xml versi ...
- MongoDB(课时11 嵌套集合)
3.4.2.6 嵌套集合运算 MongoDB数据库里每个集合数据可以继续保存其它的集合数据.例如:有些学生信息中需要保存家长信息. 范例: 增加数据 db.students.insert({" ...
- 使用R内置函数操作数据框
我们已经学习了数据框的基础,这里回顾一下用于筛选数据框的内置函数.尽管数据框本质上是一个由向量构成的列表,由于各列长度相同,所以可以将其看作矩阵进行访问和操作.选择满足特定条件的行,需要为 [ ] 的 ...
- 《F4+2》—团队项目系统设计改进与详细设计
一.团队项目系统设计改进: 1.分析项目系统设计说明书初稿的不足,特别是软件系统结构模型建模不完善内容 在上一次的项目系统设计说明书中没有很好的完成软件系统结构模型的建模设计,只做了基本的系统项目原型 ...
- js 中的几个假值
1. 使用场景 if分支语句 / 短路语句while循环语句for里的第二个语句 2. 6个假值 (都属于 原始类型数据的一部分内容,非原始类型即对象都是真值,如:对象.数组.正则.函数 . ...
- linux上python安装相关
[CentOS上安装python2.7和ipython]1,安装依赖库yum install readline-devel 2,按装python2.7和ipython //使用ipython需要先安装 ...
- C#中简单的文件操作实例
using System; using System.IO; namespace Demo { class Program { static string tmpPath = @"D:/Lg ...
- laravel时间判断
$now = Carbon::now(); if ($now >= '2019-01-02') { }