Spark(Hive) SQL中UDF的使用(Python)【转】
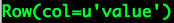
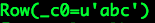





Spark(Hive) SQL中UDF的使用(Python)【转】的更多相关文章
- Spark(Hive) SQL中UDF的使用(Python)
相对于使用MapReduce或者Spark Application的方式进行数据分析,使用Hive SQL或Spark SQL能为我们省去不少的代码工作量,而Hive SQL或Spark SQL本身内 ...
- Spark(Hive) SQL数据类型使用详解(Python)
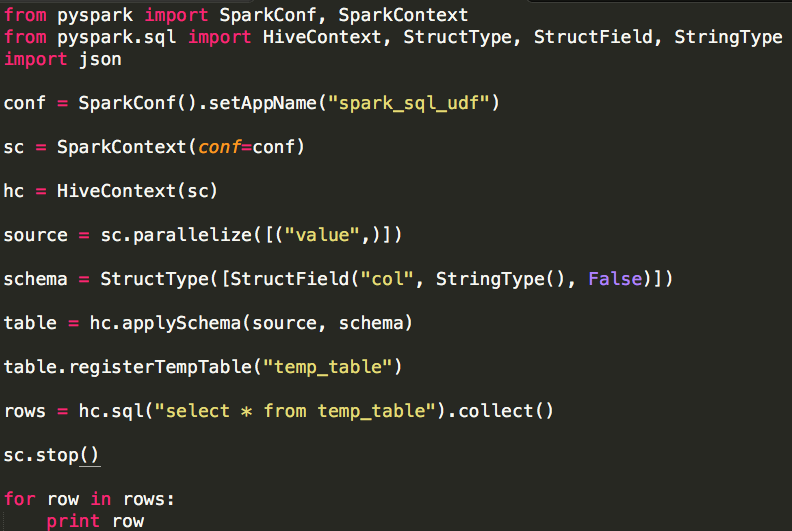
Spark SQL使用时需要有若干“表”的存在,这些“表”可以来自于Hive,也可以来自“临时表”.如果“表”来自于Hive,它的模式(列名.列类型等)在创建时已经确定,一般情况下我们直接通过Spar ...
- Spark SQL中UDF和UDAF
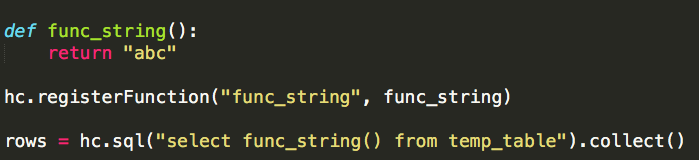
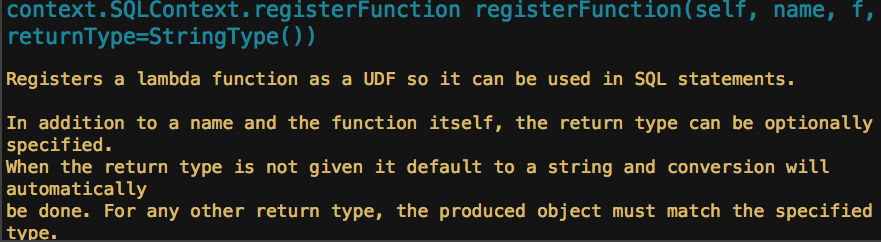
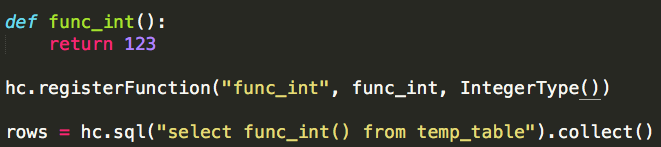
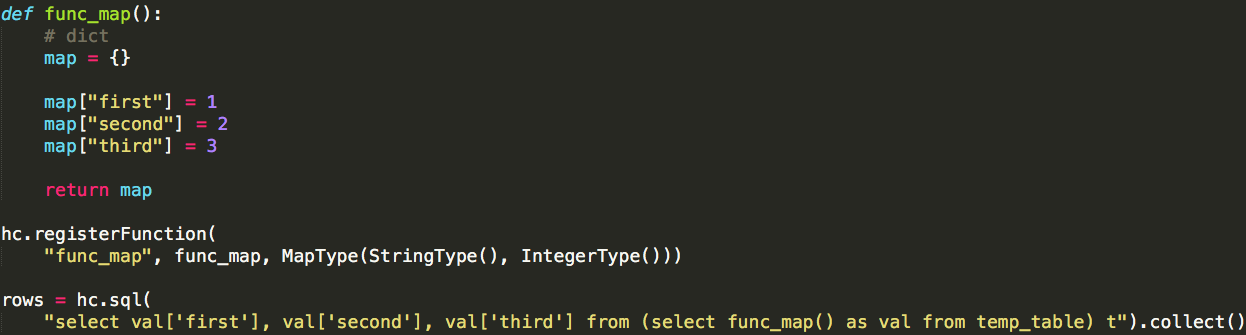
转载自:https://blog.csdn.net/u012297062/article/details/52227909 UDF: User Defined Function,用户自定义的函数,函数 ...
- 两种方式— 在hive SQL中传入参数
第一种: sql = sql.format(dt=dt) 第二种: item_third_cate_cd_list = " 发发发 " ...... ""&qu ...
- Hive SQL 编译过程
转自:http://www.open-open.com/lib/view/open1400644430159.html Hive跟Impala貌似都是公司或者研究所常用的系统,前者更稳定点,实现方式是 ...
- 【转】Hive SQL的编译过程
Hive是基于Hadoop的一个数据仓库系统,在各大公司都有广泛的应用.美团数据仓库也是基于Hive搭建,每天执行近万次的Hive ETL计算流程,负责每天数百GB的数据存储和分析.Hive的稳定性和 ...
- Hive SQL的编译过程
文章转自:http://tech.meituan.com/hive-sql-to-mapreduce.html Hive是基于Hadoop的一个数据仓库系统,在各大公司都有广泛的应用.美团数据仓库也是 ...
- 转:Hive SQL的编译过程
Hive是基于Hadoop的一个数据仓库系统,在各大公司都有广泛的应用.美团数据仓库也是基于Hive搭建,每天执行近万次的Hive ETL计算流程,负责每天数百GB的数据存储和分析.Hive的稳定性和 ...
- Hive SQL的编译过程[转载自https://tech.meituan.com/hive-sql-to-mapreduce.html]
https://tech.meituan.com/hive-sql-to-mapreduce.html Hive是基于Hadoop的一个数据仓库系统,在各大公司都有广泛的应用.美团数据仓库也是基于Hi ...
随机推荐
- web安全之渗透测试
本次渗透测试使用工具列表如下: 漏洞扫描器 (主机/Web) 绿盟RAS漏洞扫描器 商用 端口扫描器 NMAP 开源 网络抓包 Fiddler 开源 暴力破解工具 Hydra 开源 数据库注入工具 S ...
- ubuntu安装wkhtmltopdf
下载安装wkhtmltox系统环境 http://wkhtmltopdf.org/downloads.html wget https://bitbucket.org/wkhtmltopdf/wkhtm ...
- TCP_NODELAY 和 TCP_NOPUSH的解释
一.问题的来源 今天看到 huoding 大哥分享的 lamp 面试题,其中一点提到了: Nginx 有两个配置项: TCP_NODELAY 和 TCP_NOPUSH ,请说明它们的用途及注意事项. ...
- Sketch Measure
Sketch Measure 让创建规范成为开发者和团队协作的乐趣 http://sketch.im/plugins/1 安装 下载安装包 双击 Sketch Measure.sketchplugin ...
- 对于不返回任何键列信息的 selectcommand 不支持 updatecommand 的动态 sql 生成
大家知道,DataSet保存的数据是位于服务器内存里面的原数据库的“副本”.所以用DataSet更新数据的过程就是先对“副本”进行更新,然后 在将“原本”更新,按照我的理解就是把“原本”覆盖掉.具体到 ...
- Linux VFS数据结构
先说明一下,linux内核中各种数据结构也不停的在变,所以不同版本的内核各个数据结构的定义可能会差别很大,这一组关于linux 文件系统的文章中的代码都摘自linux-2.6.34.1. VFS依赖于 ...
- Python 爬虫实例(11)—— 爬虫 苏宁易购
# coding:utf-8 import json import redis import time import requests session = requests.session() imp ...
- Spring Hibernate JPA 联表查询 复杂查询(转)
今天刷网,才发现: 1)如果想用hibernate注解,是不是一定会用到jpa的? 是.如果hibernate认为jpa的注解够用,就直接用.否则会弄一个自己的出来作为补充. 2)jpa和hibern ...
- nmap 端口扫描工具
nmap工具介绍 一.简介 nmap :也就是Network Mapper,最早是Linux下的网络扫描和嗅探工具包. nmap是一个网络连接端扫描软件,用来扫描网上电脑开放的网络连接端.确定哪些服务 ...
- wget常见用法
1.很多软件官网会有安装脚本,并把脚本搞成raw模式,方便下载后直接运行的shell文件.比如docker wget -qO- get.docker.com | bash -q的含义是:--quiet ...