hadoop系列 第一坑: hdfs JournalNode Sync Status
今天早上来公司发现cloudera manager出现了hdfs的警告,如下图:
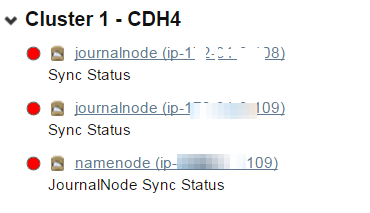




IPC Server handler on , call org.apache.hadoop.hdfs.qjournal.protocol.QJournalProtocol.getEditLogManifest from 172.31.13.29:: error: org.apache.hadoop.hdfs.qjournal.protocol.JournalNotFormattedException: Journal Storage Directory /hadop-cdh-data/jddfs/nn/journalhdfs1 not formatted
org.apache.hadoop.hdfs.qjournal.protocol.JournalNotFormattedException: Journal Storage Directory /hadop-cdh-data/jddfs/nn/journalhdfs1 not formatted
at org.apache.hadoop.hdfs.qjournal.server.Journal.checkFormatted(Journal.java:)
at org.apache.hadoop.hdfs.qjournal.server.Journal.getEditLogManifest(Journal.java:)
at org.apache.hadoop.hdfs.qjournal.server.JournalNodeRpcServer.getEditLogManifest(JournalNodeRpcServer.java:)
at org.apache.hadoop.hdfs.qjournal.protocolPB.QJournalProtocolServerSideTranslatorPB.getEditLogManifest(QJournalProtocolServerSideTranslatorPB.java:)
at org.apache.hadoop.hdfs.qjournal.protocol.QJournalProtocolProtos$QJournalProtocolService$.callBlockingMethod(QJournalProtocolProtos.java:)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:)
at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:)
at org.apache.hadoop.ipc.Server$Handler$.run(Server.java:)
at org.apache.hadoop.ipc.Server$Handler$.run(Server.java:)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:)
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:)
IPC Server handler on , call org.apache.hadoop.hdfs.qjournal.protocol.QJournalProtocol.heartbeat from 172.31.9.109:: error: java.io.FileNotFoundException: /hadop-cdh-data/jddfs/nn/journalhdfs1/current/last-promised-epoch.tmp (No such file or directory)
java.io.FileNotFoundException: /hadop-cdh-data/jddfs/nn/journalhdfs1/current/last-promised-epoch.tmp (No such file or directory)
at java.io.FileOutputStream.open(Native Method)
at java.io.FileOutputStream.<init>(FileOutputStream.java:)
at java.io.FileOutputStream.<init>(FileOutputStream.java:)
at org.apache.hadoop.hdfs.util.AtomicFileOutputStream.<init>(AtomicFileOutputStream.java:)
at org.apache.hadoop.hdfs.util.PersistentLongFile.writeFile(PersistentLongFile.java:)
at org.apache.hadoop.hdfs.util.PersistentLongFile.set(PersistentLongFile.java:)
at org.apache.hadoop.hdfs.qjournal.server.Journal.updateLastPromisedEpoch(Journal.java:)
at org.apache.hadoop.hdfs.qjournal.server.Journal.checkRequest(Journal.java:)
at org.apache.hadoop.hdfs.qjournal.server.Journal.heartbeat(Journal.java:)
at org.apache.hadoop.hdfs.qjournal.server.JournalNodeRpcServer.heartbeat(JournalNodeRpcServer.java:)
at org.apache.hadoop.hdfs.qjournal.protocolPB.QJournalProtocolServerSideTranslatorPB.heartbeat(QJournalProtocolServerSideTranslatorPB.java:)
at org.apache.hadoop.hdfs.qjournal.protocol.QJournalProtocolProtos$QJournalProtocolService$.callBlockingMethod(QJournalProtocolProtos.java:)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:)
at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:)
at org.apache.hadoop.ipc.Server$Handler$.run(Server.java:)
at org.apache.hadoop.ipc.Server$Handler$.run(Server.java:)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:)
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:)
scp -r -i /root/xxxxxxx.pem root@ip-xxx-xx-xx-111:/hadop-cdh-data/jddfs/nn/journalhdfs1 ./
chown -R hdfs:hdfs journalhdfs1
hadoop系列 第一坑: hdfs JournalNode Sync Status的更多相关文章
- hadoop系列二:HDFS文件系统的命令及JAVA客户端API
转载请在页首明显处注明作者与出处 一:说明 此为大数据系列的一些博文,有空的话会陆续更新,包含大数据的一些内容,如hadoop,spark,storm,机器学习等. 当前使用的hadoop版本为2.6 ...
- Hadoop优化 第一篇 : HDFS/MapReduce
比较惭愧,博客很久(半年)没更新了.最近也自己搭了个博客,wordpress玩的还不是很熟,感兴趣的朋友可以多多交流哈!地址是:http://www.leocook.org/ 另外,我建了个QQ群:3 ...
- hadoop系列 第二坑: hive hbase关联表问题
关键词: hive创建表卡住了 创建hive和hbase关联表卡住了 其实针对这一问题在info级别的日志下是看出哪里有问题的(为什么只能在debug下才能看见呢,不太理解开发者的想法). 以调试模式 ...
- hadoop系列三:mapreduce的使用(一)
转载请在页首明显处注明作者与出处 http://www.cnblogs.com/zhuxiaojie/p/7224772.html 一:说明 此为大数据系列的一些博文,有空的话会陆续更新,包含大数据的 ...
- hadoop系列一:hadoop集群安装
转载请在页首明显处注明作者与出处 http://www.cnblogs.com/zhuxiaojie/p/6384393.html 一:说明 此为大数据系列的一些博文,有空的话会陆续更新,包含大数据 ...
- Hadoop 系列(一)—— 分布式文件系统 HDFS
一.介绍 HDFS (Hadoop Distributed File System)是 Hadoop 下的分布式文件系统,具有高容错.高吞吐量等特性,可以部署在低成本的硬件上. 二.HDFS 设计原理 ...
- Hadoop 系列文章(二) Hadoop配置部署启动HDFS及本地模式运行MapReduce
接着上一篇文章,继续我们 hadoop 的入门案例. 1. 修改 core-site.xml 文件 [bamboo@hadoop-senior hadoop-2.5.0]$ vim etc/hadoo ...
- hadoop系列四:mapreduce的使用(二)
转载请在页首明显处注明作者与出处 一:说明 此为大数据系列的一些博文,有空的话会陆续更新,包含大数据的一些内容,如hadoop,spark,storm,机器学习等. 当前使用的hadoop版本为2.6 ...
- Hadoop系列007-HDFS客户端操作
title: Hadoop系列007-HDFS客户端操作 date: 2018-12-6 15:52:55 updated: 2018-12-6 15:52:55 categories: Hadoop ...
随机推荐
- RPC的基础:调研EOS插件http_plugin
区块链的应用是基于http服务,这种能力在EOS中是依靠http_plugin插件赋予的. 关键字:通讯模式,add_api,http server,https server,unix server, ...
- 简明awk教程(Simple awk tutorial)
整理翻译.原文地址:http://www.hcs.harvard.edu/~dholland/computers/awk.html 简明awk教程 为什么选awk? awk小巧.快速.简单.awk语言 ...
- Java基础系列--final、finally关键字
原创作品,可以转载,但是请标注出处地址:http://www.cnblogs.com/V1haoge/p/8482909.html 一.概述 final是Java关键字中最常见之一,表示“最终的,不可 ...
- maven教程5(聚合工程)
所谓聚合项目,实际上就是对项目分模块,互联网项目一般来说按照业务分(订单模块.VIP模块.支付模块.CMS模块...),传统的软件项目,大多采用分层的方式(Dao.Serivce.Controller ...
- Fibonacci快速实现(优化)
斐波那契数列的通俗解法是利用递推公式进行递归求解,我们可以更优化的去解决它. 方法一:通项公式 斐波那契数列的递推公式是f(n)=f(n-1)+f(n-2),特征方程为:x2=x+1,解该方程得(1+ ...
- [翻译]EntityFramework Core 2.2 发布
原文来源 TechViews 今天我们将推出EF Core 2.2的最终版本,以及ASP.NET Core 2.2和.NET Core 2.2 .这是我们的开源和跨平台对象数据库映射技术的最新版本. ...
- WINAPI实现简易扫雷游戏
//扫雷 #include <windows.h> #include <windowsx.h> #include <strsafe.h> #include < ...
- ECMAScript 引用类型
Object对象 新建对象 var obj = new Object() var obj ={} var obj={age:23} ... hasOwnProperty(property) 方法 va ...
- Spark知识点小结
函数在driver端定义.在executor端被调用执行
- Oracle数据库如何提高访问性能
A,避免在索引列上使用 IS NULL 和 IS NOT NULL 操作 避免在索引中使用然后可以为空的列,ORACLE将无法使用该索引.对于单列索引 如果包含空值,索引将不存在此记录.对于复合索引 ...