hadoop系列 第一坑: hdfs JournalNode Sync Status
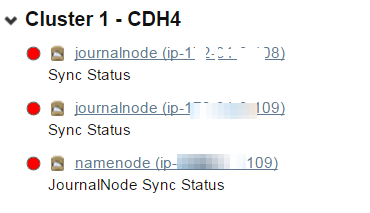
今天早上来公司发现cloudera manager出现了hdfs的警告,如下图:




IPC Server handler on , call org.apache.hadoop.hdfs.qjournal.protocol.QJournalProtocol.getEditLogManifest from 172.31.13.29:: error: org.apache.hadoop.hdfs.qjournal.protocol.JournalNotFormattedException: Journal Storage Directory /hadop-cdh-data/jddfs/nn/journalhdfs1 not formatted
org.apache.hadoop.hdfs.qjournal.protocol.JournalNotFormattedException: Journal Storage Directory /hadop-cdh-data/jddfs/nn/journalhdfs1 not formatted
at org.apache.hadoop.hdfs.qjournal.server.Journal.checkFormatted(Journal.java:)
at org.apache.hadoop.hdfs.qjournal.server.Journal.getEditLogManifest(Journal.java:)
at org.apache.hadoop.hdfs.qjournal.server.JournalNodeRpcServer.getEditLogManifest(JournalNodeRpcServer.java:)
at org.apache.hadoop.hdfs.qjournal.protocolPB.QJournalProtocolServerSideTranslatorPB.getEditLogManifest(QJournalProtocolServerSideTranslatorPB.java:)
at org.apache.hadoop.hdfs.qjournal.protocol.QJournalProtocolProtos$QJournalProtocolService$.callBlockingMethod(QJournalProtocolProtos.java:)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:)
at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:)
at org.apache.hadoop.ipc.Server$Handler$.run(Server.java:)
at org.apache.hadoop.ipc.Server$Handler$.run(Server.java:)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:)
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:)
IPC Server handler on , call org.apache.hadoop.hdfs.qjournal.protocol.QJournalProtocol.heartbeat from 172.31.9.109:: error: java.io.FileNotFoundException: /hadop-cdh-data/jddfs/nn/journalhdfs1/current/last-promised-epoch.tmp (No such file or directory)
java.io.FileNotFoundException: /hadop-cdh-data/jddfs/nn/journalhdfs1/current/last-promised-epoch.tmp (No such file or directory)
at java.io.FileOutputStream.open(Native Method)
at java.io.FileOutputStream.<init>(FileOutputStream.java:)
at java.io.FileOutputStream.<init>(FileOutputStream.java:)
at org.apache.hadoop.hdfs.util.AtomicFileOutputStream.<init>(AtomicFileOutputStream.java:)
at org.apache.hadoop.hdfs.util.PersistentLongFile.writeFile(PersistentLongFile.java:)
at org.apache.hadoop.hdfs.util.PersistentLongFile.set(PersistentLongFile.java:)
at org.apache.hadoop.hdfs.qjournal.server.Journal.updateLastPromisedEpoch(Journal.java:)
at org.apache.hadoop.hdfs.qjournal.server.Journal.checkRequest(Journal.java:)
at org.apache.hadoop.hdfs.qjournal.server.Journal.heartbeat(Journal.java:)
at org.apache.hadoop.hdfs.qjournal.server.JournalNodeRpcServer.heartbeat(JournalNodeRpcServer.java:)
at org.apache.hadoop.hdfs.qjournal.protocolPB.QJournalProtocolServerSideTranslatorPB.heartbeat(QJournalProtocolServerSideTranslatorPB.java:)
at org.apache.hadoop.hdfs.qjournal.protocol.QJournalProtocolProtos$QJournalProtocolService$.callBlockingMethod(QJournalProtocolProtos.java:)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:)
at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:)
at org.apache.hadoop.ipc.Server$Handler$.run(Server.java:)
at org.apache.hadoop.ipc.Server$Handler$.run(Server.java:)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:)
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:)
scp -r -i /root/xxxxxxx.pem root@ip-xxx-xx-xx-111:/hadop-cdh-data/jddfs/nn/journalhdfs1 ./
chown -R hdfs:hdfs journalhdfs1
hadoop系列 第一坑: hdfs JournalNode Sync Status的更多相关文章
- hadoop系列二:HDFS文件系统的命令及JAVA客户端API
转载请在页首明显处注明作者与出处 一:说明 此为大数据系列的一些博文,有空的话会陆续更新,包含大数据的一些内容,如hadoop,spark,storm,机器学习等. 当前使用的hadoop版本为2.6 ...
- Hadoop优化 第一篇 : HDFS/MapReduce
比较惭愧,博客很久(半年)没更新了.最近也自己搭了个博客,wordpress玩的还不是很熟,感兴趣的朋友可以多多交流哈!地址是:http://www.leocook.org/ 另外,我建了个QQ群:3 ...
- hadoop系列 第二坑: hive hbase关联表问题
关键词: hive创建表卡住了 创建hive和hbase关联表卡住了 其实针对这一问题在info级别的日志下是看出哪里有问题的(为什么只能在debug下才能看见呢,不太理解开发者的想法). 以调试模式 ...
- hadoop系列三:mapreduce的使用(一)
转载请在页首明显处注明作者与出处 http://www.cnblogs.com/zhuxiaojie/p/7224772.html 一:说明 此为大数据系列的一些博文,有空的话会陆续更新,包含大数据的 ...
- hadoop系列一:hadoop集群安装
转载请在页首明显处注明作者与出处 http://www.cnblogs.com/zhuxiaojie/p/6384393.html 一:说明 此为大数据系列的一些博文,有空的话会陆续更新,包含大数据 ...
- Hadoop 系列(一)—— 分布式文件系统 HDFS
一.介绍 HDFS (Hadoop Distributed File System)是 Hadoop 下的分布式文件系统,具有高容错.高吞吐量等特性,可以部署在低成本的硬件上. 二.HDFS 设计原理 ...
- Hadoop 系列文章(二) Hadoop配置部署启动HDFS及本地模式运行MapReduce
接着上一篇文章,继续我们 hadoop 的入门案例. 1. 修改 core-site.xml 文件 [bamboo@hadoop-senior hadoop-2.5.0]$ vim etc/hadoo ...
- hadoop系列四:mapreduce的使用(二)
转载请在页首明显处注明作者与出处 一:说明 此为大数据系列的一些博文,有空的话会陆续更新,包含大数据的一些内容,如hadoop,spark,storm,机器学习等. 当前使用的hadoop版本为2.6 ...
- Hadoop系列007-HDFS客户端操作
title: Hadoop系列007-HDFS客户端操作 date: 2018-12-6 15:52:55 updated: 2018-12-6 15:52:55 categories: Hadoop ...
随机推荐
- PHP算法之快速排序、冒泡排序
快速排序 <?php Class Sort { //快速排序 public function quickly($array) { //判断排序的数组是否大于1 if (count($array) ...
- 【学习笔记】深入理解HTTP协议
参考:关于HTTP协议,一篇就够了,感谢作者认真细致的总结,本文在理解的基础上修改了内容,加深印象的同时也希望对大家有所帮助 HTTP是什么? HTTP协议是Hyper Text Transfer P ...
- DataGridView样式生成器使用说明
啥都不说先看图 一. 功能介绍 1. winform DataGridView样式代码可视化即时生成,所见即所得 2. 预置DataGridView样式代码方案 预置三 ...
- c#cookie读取写入操作
public static void SetCookie(string cname, string value, int effective) { HttpCookie cookie = new Ht ...
- [PHP] 算法-合并两个有序链表为一个有序链表的PHP实现
合并两个有序的链表为一个有序的链表: 类似归并排序中合并两个数组的部分 1.遍历链表1和链表2,比较链表1和2中的元素大小 2.如果链表1结点大于链表2的结点,该结点放入第三方链表 3.链表1往下走一 ...
- CentOS7 config aliyun yum repository
https://www.cnblogs.com/lpbottle/p/7875400.html 1. 备份原来的yum源 mv /etc/yum.repos.d/CentOS-Base.repo /e ...
- 【Mybatis】1、Mybatis拦截器学习资料汇总
MyBatis拦截器原理探究 http://www.cnblogs.com/fangjian0423/p/mybatis-interceptor.html [myBatis]Mybatis中的拦截器 ...
- MEF 插件式开发之 WPF 初体验
MEF 在 WPF 中的简单应用 MEF 的开发模式主要适用于插件化的业务场景中,C/S 和 B/S 中都有相应的使用场景,其中包括但不限于 ASP.NET MVC .ASP WebForms.WPF ...
- 【Mybatis】一对一实例
①创建数据库和表,数据库为mytest,表为father和child DROP TABLE IF EXISTS child; DROP TABLE IF EXISTS father; CREATE T ...
- NIO学习笔记四 :SocketChannel 和 ServerSocketChannel
Java NIO中的SocketChannel是一个连接到TCP网络套接字的通道.可以通过以下2种方式创建SocketChannel: 打开一个SocketChannel并连接到互联网上的某台服务器. ...