简单的基于矩阵分解的推荐算法-PMF, NMF
介绍:
推荐系统中最为主流与经典的技术之一是协同过滤技术(Collaborative Filtering),它是基于这样的假设:用户如果在过去对某些项目产生过兴趣,那么将来他很可能依然对其保持热忱。其中协同过滤技术又可根据是否采用了机器学习思想建模的不同划分为基于内存的协同过滤(Memory-based CF)与基于模型的协同过滤技术(Model-based CF)。其中基于模型的协同过滤技术中尤为矩阵分解(Matrix Factorization)技术最为普遍和流行,因为它的可扩展性极好并且易于实现,因此接下来我们将梳理下推荐系统中出现过的经典的矩阵分解方法。
矩阵分解:
首先对于推荐系统来说存在两大场景即评分预测(rating prediction)与Top-N推荐(item recommendation,item ranking)。评分预测场景主要用于评价网站,比如用户给自己看过的电影评多少分(MovieLens),或者用户给自己看过的书籍评价多少分(Douban)。其中矩阵分解技术主要应用于该场景。Top-N推荐场景主要用于购物网站或者一般拿不到显式评分信息的网站,即通过用户的隐式反馈信息来给用户推荐一个可能感兴趣的列表以供其参考。其中该场景为排序任务,因此需要排序模型来对其建模。因此,我们接下来更关心评分预测任务。
对于评分预测任务来说,我们通常将用户和项目(以电影为例)表示为二维矩阵的形式,其中矩阵中的某个元素表示对应用户对于相应项目的评分,1-5分表示喜欢的程度逐渐增加,?表示没有过评分记录。推荐系统评分预测任务可看做是一个矩阵补全(Matrix Completion)的任务,即基于矩阵中已有的数据(observed data)来填补矩阵中没有产生过记录的元素(unobserved data)。值得注意的是,这个矩阵是非常稀疏的(Sparse),稀疏度一般能达到90%以上,因此如何根据极少的观测数据来较准确的预测未观测数据一直以来都是推荐系统领域的关键问题。
基础背景:SVD 和 FunkSVD
SVD
当然SVD分解的形式为3个矩阵相乘,左右两个矩阵分别表示用户/项目隐含因子矩阵,中间矩阵为奇异值矩阵并且是对角矩阵,每个元素满足非负性,并且逐渐减小。因此我们可以只需要前 个因子来表示它。
如果想运用SVD分解的话,有一个前提是要求矩阵是稠密的,即矩阵里的元素要非空,否则就不能运用SVD分解。很显然我们的任务还不能用SVD,所以一般的做法是先用均值或者其他统计学方法来填充矩阵,然后再运用SVD分解降维。
公式如下
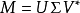
FUNKSVD
SVD首先需要填充矩阵,然后再进行分解降维,同时由于需要求逆操作(复杂度O(n^3)),存在计算复杂度高的问题,所以后来Simon Funk提出了FunkSVD的方法,它不在将矩阵分解为3个矩阵,而是分解为2个低秩的用户项目矩阵,同时降低了计算复杂度:
它借鉴线性回归的思想,通过最小化观察数据的平方来寻求最优的用户和项目的隐含向量表示。同时为了避免过度拟合(Overfitting)观测数据,又提出了带有L2正则项的FunkSVD:
SVD 和 FUNKSVD 的最优化函数都可以通过梯度下降或者随机梯度下降法来寻求最优解。
PMF:
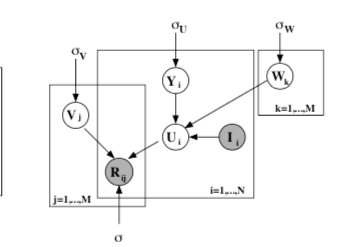
PMF是对于FunkSVD的概率解释版本,它假设评分矩阵中的元素 是由用户潜在偏好向量 和物品潜在属性向量 的内积决定的:
则观测到的评分矩阵条件概率为:

同时,假设用户偏好向量与物品偏好向量服从于均值都为0,方差分别为 , 的正态分布:
根据贝叶斯公式,可以得出潜变量U,V的后验概率为:

接着,等式两边取对数 后得到:
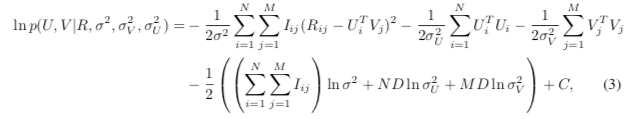
最后,经过推导,我们可以发现PMF确实是FunkSVD的概率解释版本,它两个的形式一样一样的。
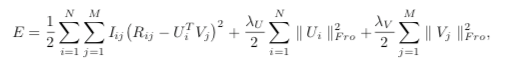
NMF
在普通的SVD的运算过程中,会得到一些负数的embedding,这里,提出了一个假设:分解出来的小矩阵应该满足非负约束。
因为在大部分方法中,原始矩阵 被近似分解为两个低秩矩阵 相乘的形式,这些方法的共同之处是,即使原始矩阵的元素都是非负的,也不能保证分解出的小矩阵都为非负,这就导致了推荐系统中经典的矩阵分解方法可以达到很好的预测性能,但不能做出像User-based CF那样符合人们习惯的推荐解释(即跟你品味相似的人也购买了此商品)。在数学意义上,分解出的结果是正是负都没关系,只要保证还原后的矩阵元素非负并且误差尽可能小即可,但负值元素往往在现实世界中是没有任何意义的。比如图像数据中不可能存在是负数的像素值,因为取值在0~255之间;在统计文档的词频时,负值也是无法进行解释的。因此提出带有非负约束的矩阵分解是对于传统的矩阵分解无法进行科学解释做出的一个尝试。
其中, 分解的两个矩阵中的元素满足非负约束。
简单的基于矩阵分解的推荐算法-PMF, NMF的更多相关文章
- HAWQ + MADlib 玩转数据挖掘之(四)——低秩矩阵分解实现推荐算法
一.潜在因子(Latent Factor)推荐算法 本算法整理自知乎上的回答@nick lee.应用领域:"网易云音乐歌单个性化推荐"."豆瓣电台音乐推荐"等. ...
- SVD++:推荐系统的基于矩阵分解的协同过滤算法的提高
1.背景知识 在讲SVD++之前,我还是想先回到基于物品相似的协同过滤算法.这个算法基本思想是找出一个用户有过正反馈的物品的相似的物品来给其作为推荐.其公式为:
- (转) 基于MapReduce的ItemBase推荐算法的共现矩阵实现(一)
转自:http://zengzhaozheng.blog.51cto.com/8219051/1557054 一.概述 这2个月为公司数据挖掘系统做一些根据用户标签情况对用户的相似度进行评估,其中涉及 ...
- 【笔记5】用pandas实现矩阵数据格式的推荐算法 (基于物品的协同)
''' 基于物品的协同推荐 矩阵数据 说明: 1.修正的余弦相似度是一种基于模型的协同过滤算法.我们前面提过,这种算法的优势之 一是扩展性好,对于大数据量而言,运算速度快.占用内存少. 2.用户的评价 ...
- 【笔记3】用pandas实现矩阵数据格式的推荐算法 (基于用户的协同)
原书作者使用字典dict实现推荐算法,并且惊叹于18行代码实现了向量的余弦夹角公式. 我用pandas实现相同的公式只要3行. 特别说明:本篇笔记是针对矩阵数据,下篇笔记是针对条目数据. ''' 基于 ...
- Mahout分布式运行实例:基于矩阵分解的协同过滤评分系统(一个命令实现文件格式的转换)
Apr 08, 2014 Categories in tutorial tagged with Mahout hadoop 协同过滤 Joe Jiang 前言:之前配置Mahout时测试过一个简 ...
- Eigen学习之简单线性方程与矩阵分解
Eigen提供了解线性方程的计算方法,包括LU分解法,QR分解法,SVD(奇异值分解).特征值分解等.对于一般形式如下的线性系统: 解决上述方程的方式一般是将矩阵A进行分解,当然最基本的方法是高斯消元 ...
- 预测算法:基于UCF的电影推荐算法
#基于用户的推荐类算法 from math import sqrt #计算两个person的欧几里德距离 def sim_distance(prefs,person1,person2): si = { ...
- 推荐算法——非负矩阵分解(NMF)
一.矩阵分解回想 在博文推荐算法--基于矩阵分解的推荐算法中,提到了将用户-商品矩阵进行分解.从而实现对未打分项进行打分. 矩阵分解是指将一个矩阵分解成两个或者多个矩阵的乘积.对于上述的用户-商品矩阵 ...
随机推荐
- TTS
CLASS_SpVoice: TGUID = '{96749377-3391-11D2-9EE3-00C04F797396}'; http://blog.sina.com.cn/s/blog_4fce ...
- python_07 函数作用域、匿名函数
函数的作用域:无论在哪个地方调用函数,函数运行过程中的作用域只跟定义的时候有关,跟在哪个地方调用无关. name='alex' def foo(): name = 'linhaifeng' def b ...
- Android中五大字符串总结(String、StringBuffer、StringBuilder、Spanna
https://www.aliyun.com/jiaocheng/2861.html?spm=5176.100033.1.35.2ed56b03CbsYFK 摘要:String.StringBuffe ...
- cleos
[cleos] 1.在.bashrc中加入以下代码,方便直接使用 cleos,7777是nodeos端口,5555是keosd端口. alias cleos='docker exec -it eosi ...
- mysql_day04
MySQL-Day03回顾1.索引 1.普通索引 index 2.唯一索引(UNI,字段值不允许重复,但可以为NULL) 1.创建 1.字段名 数据类型 unique 2.unique(字段名), u ...
- 浅析AnyCast网络技术
什么是BGP AnyCast? BGP anycast就是利用一个(多个) as号码在不同的地区广播相同的一个ip段.利用bgp的寻路原则,短的as path 会选成最优路径(bgp寻路原则之n),从 ...
- idea2017启动ssm项目卡在build阶段后报outofmemory
如上图,设置build process heap size(Mbytes)(构建过程堆大小(单位MB))为4000,即约4GB.之前设置的是700,修改之后问题解决. 补充:导入新项目后,此参数会初始 ...
- 数据库类型空间效率探索(五)- decimal/float/double/varchar
以下测试为userinfo增加一列,列类型分别为decimal.float.double.varchar.由于innodb不支持optimize,所以每次测试,都会删除表test.userinfo,重 ...
- Python学习之MacBook Pro中PyCharm安装pip以及itchat
前言:Mac中自带的python没有用,自己安装了一个PyCharm,网上很多人说安装Itchat后会安装到自带的Python中去.本文记录怎么安装到自己安装的Python3.7中去.主要技术来源于h ...
- django.core.exceptions.ImproperlyConfigured: Requested setting DEFAULT_INDEX_TABLESPACE, but settings are not configured. You must either define the environment variable DJANGO_SETTINGS_MODULE or call
Error info: django.core.exceptions.ImproperlyConfigured: Requested setting DEFAULT_INDEX_TABLESPACE, ...