The perception and large margin classifiers
假设样例按照到来的先后顺序依次定义为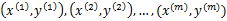 。
。为样本特征,
为类别标签。任务是到来一个样例
,给出其类别结果
的预测值,之后我们会看到真实值
,然后根据真实值来重新调整模型参数,整个过程是重复迭代的过程,直到所有的样例完成。这么看来,我们也可以将原来用于批量学习的样例拿来作为在线学习的样例。在在线学习中,我们主要关注在整个预测过程中预测错误的样例数。
用表示正例,
表示负例,支持向量机中提到的感知算法(perception algorithm),我们的假设函数为:
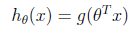
其中,x是n维特征向量,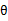 是n+1维参数权重。函数g用来将
是n+1维参数权重。函数g用来将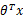 计算结果映射到-1和1上。具体公式如下:
计算结果映射到-1和1上。具体公式如下:
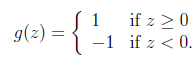
提出一个在线学习算法如下:
新来一个样例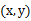 ,我们先用从之前样例学习到的
,我们先用从之前样例学习到的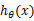 来得到样例的预测值y,如果
来得到样例的预测值y,如果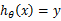 (即预测正确),那么不改变
(即预测正确),那么不改变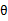 ,反之
,反之
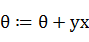
如果对于预测错误的样例,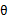 进行调整时只需加上(实际上为正例)或者减去(实际负例)样本特征x值即可。
进行调整时只需加上(实际上为正例)或者减去(实际负例)样本特征x值即可。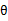 初始值为向量0。这里我们关心的是
初始值为向量0。这里我们关心的是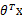 的符号,而不是它的具体值。调整方法非常简单,然而这个简单的调整方法还是很有效的,它的错误率不仅是有上界的,而且这个上界不依赖于样例数和特征维度。
的符号,而不是它的具体值。调整方法非常简单,然而这个简单的调整方法还是很有效的,它的错误率不仅是有上界的,而且这个上界不依赖于样例数和特征维度。
下面定理阐述了错误率上界:
定理(Block and Novikoff):
给定按照顺序到来的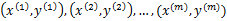 样例。假设对于所有的样例
样例。假设对于所有的样例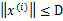 ,也就是说特征向量长度有界为D。更进一步,假设存在一个单位长度向量
,也就是说特征向量长度有界为D。更进一步,假设存在一个单位长度向量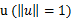 且
且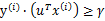 。也就是说对于y=1的正例,
。也就是说对于y=1的正例,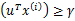 ,反例
,反例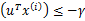 ,u能够有
,u能够有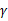 的间隔将正例和反例分开。那么感知算法的预测的错误样例数不超过
的间隔将正例和反例分开。那么感知算法的预测的错误样例数不超过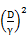 。
。
根据对SVM的理解,这个定理就可以阐述为:如果训练样本线性可分,并且几何间距至少是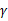 ,样例样本特征向量最长为D,那么感知算法错误数不会超过
,样例样本特征向量最长为D,那么感知算法错误数不会超过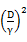 。这个定理是62年提出的,63年Vapnik提出SVM,可见提出也不是偶然的,感知算法也许是当时的热门。
。这个定理是62年提出的,63年Vapnik提出SVM,可见提出也不是偶然的,感知算法也许是当时的热门。
下面主要讨论这个定理的证明:
感知算法只在样例预测错误时进行更新,定义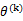 是第k次预测错误时使用的样本特征权重,
是第k次预测错误时使用的样本特征权重,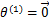 初始化为0向量。假设第k次预测错误发生在样例
初始化为0向量。假设第k次预测错误发生在样例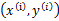 上,利用
上,利用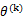 计算
计算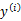 值时得到的结果不正确(也就是说
值时得到的结果不正确(也就是说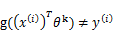 ,调换x和
,调换x和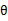 顺序主要是为了书写方便)。也就是说下面的公式成立:
顺序主要是为了书写方便)。也就是说下面的公式成立:
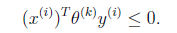
根据感知算法的更新方法,我们有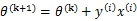 。这时候,两边都乘以u得到
。这时候,两边都乘以u得到
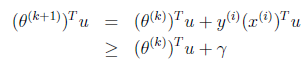
两个向量做内积的时候,放在左边还是右边无所谓,转置符号标注正确即可。
这个式子是个递推公式,就像等差数列一样f(n+1)=f(n)+d,由此我们可得:
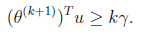
因为初始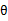 为0,下面我们利用前面推导出的
为0,下面我们利用前面推导出的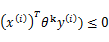 和
和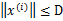 得到
得到
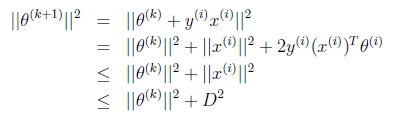
也就是说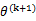 的长度平方不会超过
的长度平方不会超过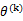 与D的平方和。
与D的平方和。
又是一个等差不等式,得到:
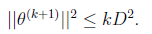
两边开根号得:
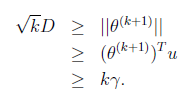
其中第二步可能有点迷惑,我们细想u是单位向量的话,
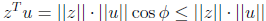
因此上面的不等式成立,最后得到:
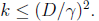
也就是预测错误的数目不会超过样本特征向量x的最长长度与几何间隔的平方,实际上整个调整过程中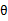 就是x的线性组合。
就是x的线性组合。
整个感知算法应该是在线学习中最简单的一种了。
The perception and large margin classifiers的更多相关文章
- 基于Caffe的Large Margin Softmax Loss的实现(中)
小喵的唠叨话:前一篇博客,我们做完了L-Softmax的准备工作.而这一章,我们开始进行前馈的研究. 小喵博客: http://miaoerduo.com 博客原文: http://www.miao ...
- 基于Caffe的Large Margin Softmax Loss的实现(上)
小喵的唠叨话:在写完上一次的博客之后,已经过去了2个月的时间,小喵在此期间,做了大量的实验工作,最终在使用的DeepID2的方法之后,取得了很不错的结果.这次呢,主要讲述一个比较新的论文中的方法,L- ...
- Large Margin Softmax Loss for Speaker Verification
[INTERSPEECH 2019接收] 链接:https://arxiv.org/pdf/1904.03479.pdf 这篇文章在会议的speaker session中.本文主要讨论了说话人验证中的 ...
- cosface: large margin cosine loss for deep face recognition
目录 概 主要内容 Wang H, Wang Y, Zhou Z, et al. CosFace: Large Margin Cosine Loss for Deep Face Recognition ...
- Large Margin DAGs for Multiclass Classification
Abstract We present a new learning architecture: the Decision Directed Acyclic Graph (DDAG), which i ...
- 吴恩达机器学习笔记43-SVM大边界分类背后的数学(Mathematics Behind Large Margin Classification of SVM)
假设我有两个向量,
- 吴恩达机器学习笔记42-大边界的直观理解(Large Margin Intuition)
这是我的支持向量机模型的代价函数,在左边这里我画出了关于
- Kemaswill 机器学习 数据挖掘 推荐系统 Ranking SVM 简介
Ranking SVM 简介 排序一直是信息检索的核心问题之一,Learning to Rank(简称LTR)用机器学习的思想来解决排序问题(关于Learning to Rank的简介请见我的博文Le ...
- Coursera, Machine Learning, SVM
Support Vector Machine (large margin classifiers ) 1. cost function and hypothesis 下面那个紫色线就是SVM 的cos ...
随机推荐
- Electron "jQuery/$ is not defined" 解决方法
参考问题:https://stackoverflow.com/questions/32621988/electron-jquery-is-not-defined <!-- Insert this ...
- redis-sentinel主从复制高可用
Redis-Sentinel Redis-Sentinel是redis官方推荐的高可用性解决方案,当用redis作master-slave的高可用时,如果master本身宕机,redis本身或者客户端 ...
- tar 命令 简易使用方法
创建压缩文件方法 tar zcf 压缩包存放位置 压缩那个目录/内容 (压缩) 例:在/data目录下压缩/etc/目录,并创建名称为etc.tar.gz [root@web01 /]# tar zc ...
- OO课程中IDEA相关插件的使用
写在前面 由于OO课程博客作业的需要分析代码的复杂度并绘制UML图,但是课件上推荐的分析工具(http://metrics.sourceforge.net )经过自己几个小时的折腾还是没有安装成功 ...
- web 页面上纯js实现按钮倒计数功能(实时计时器也可以)
需求构思:本功能想实现的是,一个按钮在页面载入就显示提醒续费,,,倒数60秒后,完成提醒功能,可以按另外一个页面跳转到主页. 参考网上的大神,实现如下:Button2倒数,Button3跳转,在页面上 ...
- Java 内存模型简单剖析
Java 内存模型试图屏蔽各种硬件和操作系统的内存访问差异,以实现让 Java 程序在各种平台下都能达到一致的内存访问效果. 主内存与工作内存 处理器上的寄存器的读写的速度比内存快几个数量级,为了解决 ...
- 7--Python入门--条件和循环
5.1 条件语句 条件语句基本框架如下:if 判断语句1: 执行语句块1elif 判断语句2: 执行语句块2else: 执行语句块3 a = 10 if a%2 == 0 : #这里使用了取余函数% ...
- FOR XML PATH 简单介绍
FOR XML PATH 有的人可能知道有的人可能不知道,其实它就是将查询结果集以XML形式展现,有了它我们可以简化我们的查询语句实现一些以前可能需要借助函数活存储过程来完成的工作.那么以一个实例为主 ...
- 单例模式demo
package com.test; /** * * @author Administrator *我的发现:调用这个的时候,不能直接实例化了;需要=null;然后get; 这样安全些; *然后仔细找了 ...
- Centos6.5搭建Elasticsearch
ElasticSearch是基于Lucene的搜索服务.支持分布式多用户能力的全文搜索引擎,提供RESTful web接口.Elasticsearch是用Java开发的,Apache旗下开源项目,支持 ...