The perception and large margin classifiers
假设样例按照到来的先后顺序依次定义为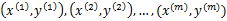 。
。为样本特征,
为类别标签。任务是到来一个样例
,给出其类别结果
的预测值,之后我们会看到真实值
,然后根据真实值来重新调整模型参数,整个过程是重复迭代的过程,直到所有的样例完成。这么看来,我们也可以将原来用于批量学习的样例拿来作为在线学习的样例。在在线学习中,我们主要关注在整个预测过程中预测错误的样例数。
用表示正例,
表示负例,支持向量机中提到的感知算法(perception algorithm),我们的假设函数为:
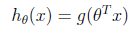
其中,x是n维特征向量,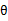 是n+1维参数权重。函数g用来将
是n+1维参数权重。函数g用来将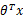 计算结果映射到-1和1上。具体公式如下:
计算结果映射到-1和1上。具体公式如下:
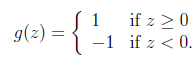
提出一个在线学习算法如下:
新来一个样例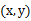 ,我们先用从之前样例学习到的
,我们先用从之前样例学习到的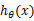 来得到样例的预测值y,如果
来得到样例的预测值y,如果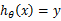 (即预测正确),那么不改变
(即预测正确),那么不改变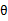 ,反之
,反之
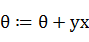
如果对于预测错误的样例,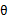 进行调整时只需加上(实际上为正例)或者减去(实际负例)样本特征x值即可。
进行调整时只需加上(实际上为正例)或者减去(实际负例)样本特征x值即可。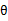 初始值为向量0。这里我们关心的是
初始值为向量0。这里我们关心的是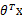 的符号,而不是它的具体值。调整方法非常简单,然而这个简单的调整方法还是很有效的,它的错误率不仅是有上界的,而且这个上界不依赖于样例数和特征维度。
的符号,而不是它的具体值。调整方法非常简单,然而这个简单的调整方法还是很有效的,它的错误率不仅是有上界的,而且这个上界不依赖于样例数和特征维度。
下面定理阐述了错误率上界:
定理(Block and Novikoff):
给定按照顺序到来的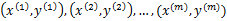 样例。假设对于所有的样例
样例。假设对于所有的样例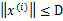 ,也就是说特征向量长度有界为D。更进一步,假设存在一个单位长度向量
,也就是说特征向量长度有界为D。更进一步,假设存在一个单位长度向量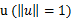 且
且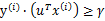 。也就是说对于y=1的正例,
。也就是说对于y=1的正例,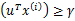 ,反例
,反例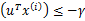 ,u能够有
,u能够有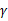 的间隔将正例和反例分开。那么感知算法的预测的错误样例数不超过
的间隔将正例和反例分开。那么感知算法的预测的错误样例数不超过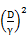 。
。
根据对SVM的理解,这个定理就可以阐述为:如果训练样本线性可分,并且几何间距至少是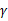 ,样例样本特征向量最长为D,那么感知算法错误数不会超过
,样例样本特征向量最长为D,那么感知算法错误数不会超过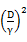 。这个定理是62年提出的,63年Vapnik提出SVM,可见提出也不是偶然的,感知算法也许是当时的热门。
。这个定理是62年提出的,63年Vapnik提出SVM,可见提出也不是偶然的,感知算法也许是当时的热门。
下面主要讨论这个定理的证明:
感知算法只在样例预测错误时进行更新,定义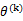 是第k次预测错误时使用的样本特征权重,
是第k次预测错误时使用的样本特征权重,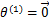 初始化为0向量。假设第k次预测错误发生在样例
初始化为0向量。假设第k次预测错误发生在样例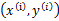 上,利用
上,利用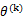 计算
计算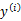 值时得到的结果不正确(也就是说
值时得到的结果不正确(也就是说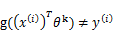 ,调换x和
,调换x和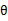 顺序主要是为了书写方便)。也就是说下面的公式成立:
顺序主要是为了书写方便)。也就是说下面的公式成立:
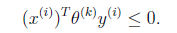
根据感知算法的更新方法,我们有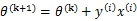 。这时候,两边都乘以u得到
。这时候,两边都乘以u得到
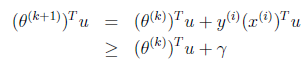
两个向量做内积的时候,放在左边还是右边无所谓,转置符号标注正确即可。
这个式子是个递推公式,就像等差数列一样f(n+1)=f(n)+d,由此我们可得:
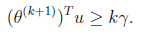
因为初始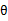 为0,下面我们利用前面推导出的
为0,下面我们利用前面推导出的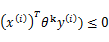 和
和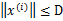 得到
得到
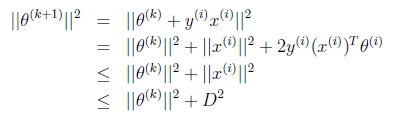
也就是说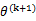 的长度平方不会超过
的长度平方不会超过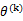 与D的平方和。
与D的平方和。
又是一个等差不等式,得到:
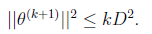
两边开根号得:
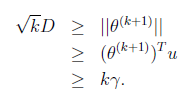
其中第二步可能有点迷惑,我们细想u是单位向量的话,
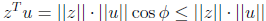
因此上面的不等式成立,最后得到:
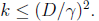
也就是预测错误的数目不会超过样本特征向量x的最长长度与几何间隔的平方,实际上整个调整过程中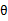 就是x的线性组合。
就是x的线性组合。
整个感知算法应该是在线学习中最简单的一种了。
The perception and large margin classifiers的更多相关文章
- 基于Caffe的Large Margin Softmax Loss的实现(中)
小喵的唠叨话:前一篇博客,我们做完了L-Softmax的准备工作.而这一章,我们开始进行前馈的研究. 小喵博客: http://miaoerduo.com 博客原文: http://www.miao ...
- 基于Caffe的Large Margin Softmax Loss的实现(上)
小喵的唠叨话:在写完上一次的博客之后,已经过去了2个月的时间,小喵在此期间,做了大量的实验工作,最终在使用的DeepID2的方法之后,取得了很不错的结果.这次呢,主要讲述一个比较新的论文中的方法,L- ...
- Large Margin Softmax Loss for Speaker Verification
[INTERSPEECH 2019接收] 链接:https://arxiv.org/pdf/1904.03479.pdf 这篇文章在会议的speaker session中.本文主要讨论了说话人验证中的 ...
- cosface: large margin cosine loss for deep face recognition
目录 概 主要内容 Wang H, Wang Y, Zhou Z, et al. CosFace: Large Margin Cosine Loss for Deep Face Recognition ...
- Large Margin DAGs for Multiclass Classification
Abstract We present a new learning architecture: the Decision Directed Acyclic Graph (DDAG), which i ...
- 吴恩达机器学习笔记43-SVM大边界分类背后的数学(Mathematics Behind Large Margin Classification of SVM)
假设我有两个向量,
- 吴恩达机器学习笔记42-大边界的直观理解(Large Margin Intuition)
这是我的支持向量机模型的代价函数,在左边这里我画出了关于
- Kemaswill 机器学习 数据挖掘 推荐系统 Ranking SVM 简介
Ranking SVM 简介 排序一直是信息检索的核心问题之一,Learning to Rank(简称LTR)用机器学习的思想来解决排序问题(关于Learning to Rank的简介请见我的博文Le ...
- Coursera, Machine Learning, SVM
Support Vector Machine (large margin classifiers ) 1. cost function and hypothesis 下面那个紫色线就是SVM 的cos ...
随机推荐
- nio 序列化
1.序列化 public class SerializeUtils<T extends Serializable> { public byte[] serialize(T t) { byt ...
- Php基本类型——布尔类型
1)简介 布尔类型,这是最简单的类型,bollean表达了真值,可以为true或false,它是php4引进的. 2)语法 要指定一个布尔值,使用关键字true或false,两个都不区分大小写. &l ...
- coursera-斯坦福-机器学习-吴恩达-笔记week4
1 神经网络的提出 线性回归和逻辑回归能很好的解决特征变量较少的问题,但对于变量数量增加的复杂非线性问题,单纯增加二次项和三次项等特征项的方法计算代价太高. 2 神经网络算法 2.1 神经元 模拟神经 ...
- 如何把已有SQLSERVER数据库更名而且附加到数据库中?
如何把已有SQLSERVER数据库更名而且附加到数据库中? 例如:已有数据库:zrmaa,希望更名为jjsh 特别提醒:数据库名中不能加入下划线,因为数据库日志文件有下划线. 把数据库文件mdf和数据 ...
- Java 作业6
我总算,又双叒叕拾起了Java,啊! 1.编写一个JApplet程序,包含一个JLabel对象,并显示用户的姓名. package experiment; import java.awt.Border ...
- mysql中外键的创建与删除
外键的创建 方法1:创建表的时候设置(外键名随机生成) 1.前提条件,必须要有一个主表,这里设为persons 2.主表中必须设置主键字段primary key,这里设为id_p //创建数据库dat ...
- 2.oracle之用户管理sql
--创建用户--create user 用户名 identified by 密码;create user jojo identified by bean; --给用户授权--grant conn ...
- Dubbo的全局Filter配置
前言: 之前也写过dubbo的filter的文章, 后来和同事也有过交流, 才发生自己对dubbo的filter的机制, 还是存在一些误解, 尤其是自定义filter的定位, 不是那么清晰. 本文主要 ...
- Win10+Ubuntu双系统删除Ubuntu方法
前情提要 Win10下试了许多种方法,什么MbrFix.EasyBCD.亦或是Boot Option.都不行.前两者不行,操作之后重启无法直接进入Windows,后者也不行,找不到所谓的Delete ...
- centos7 ssh连接慢
指的是连接到centos7,输入密码后要等很久才会返回.之前很多人遇到的问题都是由于/etc/ssh/sshd_config的UseDNS配置项和GSSAPIAuthentication配置项引起的, ...