Hadoop、Spark 集群环境搭建问题汇总
Hadoop
问题1:
Hadoop Slave节点 NodeManager 无法启动
解决方法:
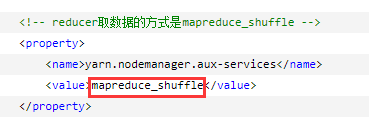
yarn-site.xml
reducer取数据的方式是mapreduce_shuffle
问题2:
启动hadoop,报错Error JAVA_HOME is not set and could not be found
解决方法:
因为JAVA_HOME环境没配置正确,还有一种情况是即使各结点都正确地配置了JAVA_HOME,但在集群环境下还是报该错误。
解决方法是 在 hadoop-env.sh中 显示地重新声明一遍JAVA_HOME。
问题3:
hadoop 执行start-dfs.sh后,datenode没有启动
解决方法:
上网查了下,有些文章说的解决办法是删掉数据文件,格式化,重启集群,但这办法实在太暴力,根本无法在生产环境实施,所以还是参考另一类文章的解决办法,修改clusterID:
step1:
查看hdfs-site.xml,找到存namenode元数据和datanode元数据的路径:
step2:
打开namenode路径下的current/VERSION文件
打开datanode路径下的current/VERSION文件
step3:
将data节点的 clusterID 修改成和 name 节点的 clusterID 一致,重启集群即可。
Spark
问题1:
Spark 集群启动后,Slave节点 Worker 进程一段时间后自动结束
解决方法:
修改各节点 /etc/hostname 文件中的主机名:
与 /etc/sysconfig/network 中的主机名保持一致。

重启机器。
问题2:
Spark只启动了Master,Worker没启动
解决方法:
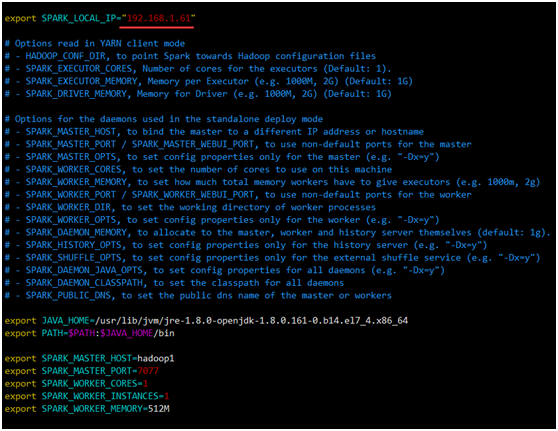
各节点 /home/hadoop/spark-2.2.1/conf/ spark-env.sh 中的 SPARK_LOCAL_IP 改为该节点自己的 IP。
问题3:
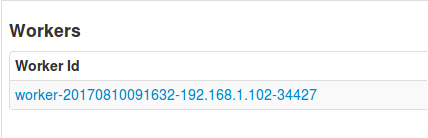
Spark集群启动后,Slave节点上有Worker进程,但打开webui,Workers列表却只显示有Master节点
解决方法:
关闭机器的防火墙
CentOS 7 默认采用新防火墙firewall,不再用iptables(service iptables status 查看防火墙状态 ,chkconfig iptables off 关闭防火墙)
systemctl stop firewalld.service #停止firewall systemctl disable firewalld.service #禁止firewall开机启动 firewall-cmd --state #查看默认防火墙状态(关闭后显示notrunning,开启后显示running)
问题4:
Spark shell退出操作以及出现问题的解决方法
解决方法:
退出的正确操作是:
:quit
Hadoop、Spark 集群环境搭建问题汇总的更多相关文章
- Hadoop+Spark:集群环境搭建
环境准备: 在虚拟机下,大家三台Linux ubuntu 14.04 server x64 系统(下载地址:http://releases.ubuntu.com/14.04.2/ubuntu-14.0 ...
- Spark集群环境搭建——Hadoop集群环境搭建
Spark其实是Hadoop生态圈的一部分,需要用到Hadoop的HDFS.YARN等组件. 为了方便我们的使用,Spark官方已经为我们将Hadoop与scala组件集成到spark里的安装包,解压 ...
- Spark 集群环境搭建
思路: ①先在主机s0上安装Scala和Spark,然后复制到其它两台主机s1.s2 ②分别配置三台主机环境变量,并使用source命令使之立即生效 主机映射信息如下: 192.168.32.100 ...
- Spark集群环境搭建——部署Spark集群
在前面我们已经准备了三台服务器,并做好初始化,配置好jdk与免密登录等.并且已经安装好了hadoop集群. 如果还没有配置好的,参考我前面两篇博客: Spark集群环境搭建--服务器环境初始化:htt ...
- Spark集群环境搭建——服务器环境初始化
Spark也是属于Hadoop生态圈的一部分,需要用到Hadoop框架里的HDFS存储和YARN调度,可以用Spark来替换MR做分布式计算引擎. 接下来,讲解一下spark集群环境的搭建部署. 一. ...
- Hadoop、Spark 集群环境搭建
1.基础环境搭建 1.1运行环境说明 1.1.1硬软件环境 主机操作系统:Windows 64位,四核8线程,主频3.2G,8G内存 虚拟软件:VMware Workstation Pro 虚拟机操作 ...
- Hadoop,HBase集群环境搭建的问题集锦(四)
21.Schema.xml和solrconfig.xml配置文件里參数说明: 參考资料:http://www.hipony.com/post-610.html 22.执行时报错: 23., /comm ...
- hadoop分布式集群环境搭建
参考 http://www.cnblogs.com/zhijianliutang/p/5736103.html 1 wget http://mirrors.shu.edu.cn/apache/hado ...
- Hadoop,HBase集群环境搭建的问题集锦(二)
10.艾玛, Datanode也启动不了了? 找到log: Caused by: java.net.UnknownHostException: Invalid host name: local hos ...
随机推荐
- 潭州课堂25班:Ph201805201 tornado 项目 第一课 项目介绍和创建 (课堂笔记)
tornado 相关说明 , 查找 python3 的路径: binbin@abc:~$ which python3/usr/bin/python3 创建虚拟环境 : 创建工程; 用 pycharm ...
- [HNOI2010]平面图判定
Description: 若能将无向图 \(G=(V, E)\) 画在平面上使得任意两条无重合顶点的边不相交,则称 \(G\) 是平面图.判定一个图是否为平面图的问题是图论中的一个重要问题.现在假设你 ...
- 种花 [JZOJ4726] [可撤销贪心]
Description 经过三十多个小时的长途跋涉,小Z和小D终于到了NOI现场——南山南中学.一进校园,小D就被花所吸引了(不要问我为什么),遍和一旁的种花园丁交(J)流(L)了起来. 他发现花的摆 ...
- 软件开发 [CJOJ 1101] [NOIP 模拟]
Description 一个软件开发公司同时要开发两个软件,并且要同时交付给用户,现在公司为了尽快完成这一任务,将每个软件划分成m个模块,由公司里的技术人员分工完成,每个技术人员完成同一软件的不同模块 ...
- JDK提供的几种线程池比较
JDK提供的几种线程池 newFixedThreadPool创建一个指定工作线程数量的线程池.每当提交一个任务就创建一个工作线程,如果工作线程数量达到线程池初始的最大数,则将提交的任务存入到池队列中. ...
- Docker容器内部端口映射到外部宿主机端口的方法小结
转自:https://www.cnblogs.com/kevingrace/p/9453987.html Docker允许通过外部访问容器或者容器之间互联的方式来提供网络服务.容器启动之后,容器中可以 ...
- 在python里调用java的py4j的使用方法
py4j可以使python和java互调 py4j并不会开启jvm,需要先启动jvm server,然后再使用python的client去连接jvm GatewayServer实例:允许python程 ...
- [Python设计模式] 第16章 上班,干活,下班,加班——状态模式
github地址:https://github.com/cheesezh/python_design_patterns 题目 用代码模拟一天的工作状态,上午状态好,中午想睡觉,下午渐恢复,加班苦煎熬. ...
- linux性能压测工具
http://benjr.tw/532 http://blog.yufeng.info/archives/2023 https://www.cnblogs.com/zhoujinyi/archive/ ...
- 第三天:MDN CSS学习笔记
一:CSS基础 1:DOM 当浏览器显示文档时,它必须将文档的内容与其样式信息结合.它分两个阶段处理文档: 浏览器将 HTML 和 CSS 转化成 DOM (文档对象模型).DOM在计算机内存中表示文 ...