序列化(pickle,shelve,json,configparser)
一,序列化
在我们存储数据或者网络传输数据的时候,需要对我们的对象进行处理,把对象处理成方便存储和传输的数据结构,这个过程叫序列化,不同的序列化,结果也不同,但是目的是一样的,都是为了存储和传输。
在python中存在三种序列化的方案。
1,pickle,可以将我们python中的任意数据类型转化成bytes并写入到文件中,同样也可以把文件中写好的bytes转换回我们python的数据,这个过程称为反序列化。
2,shelve,简单另类的一种序列化的方案,有点类似Redis,可以作为一种小型数据库来使用
3,json,将python中常见的字典,列表转化成字符串,是目前前后端数据交互使用频率最高的一种数据格式。
二,pickle(重点)
pickle就是把我们的python对象写入到文件中的一种解决方案。首先要引用pickle模块,主要是使用pickle.dumps()把对象转换成bytes;pickle.loads()把bytes转换成对象;

pickle.dump()把对象转换成bytes,然后写入文件中;pickle.load()从文件中读出,然后把bytes转换成对象。

多个对象写入和读


三,shelve
shelve提供python的持久化操作,就是把数据写到硬盘上,在操作shelve的时候非常像操作一个字典。

但是有个坑,在对内层的数据进行修改时,或者删除字典中的元素时,要用到writeback参数,不然操作后结果不会改变。

得到后的字典,可以完成字典所有操作,比如遍历,setdefault()


四,json(重点)
json就是前后端交互的枢纽,导入json模块,所使用的方法和pickle一样的。json.dumps()把字典转化成json字符串,json.loads()是把json字符串转化成字典。


json.dump()把字典转化成json字符串,然后写入文件中;json.load()把json字符串从文件中读出来,然后转换成字典。


对于多个字典的写入或者读,要采用以下办法。

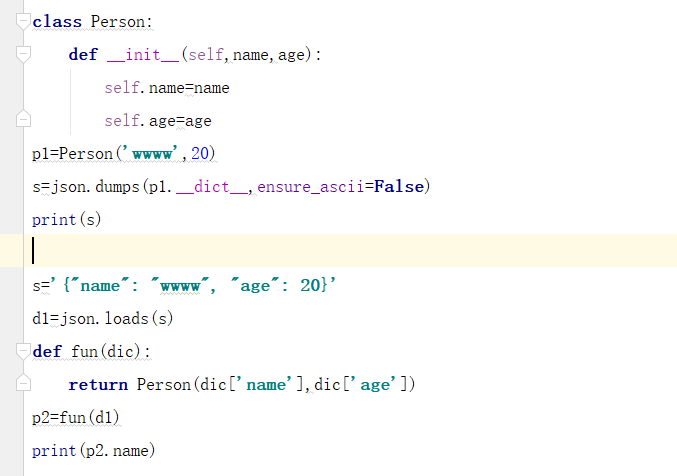
用json来处理对象
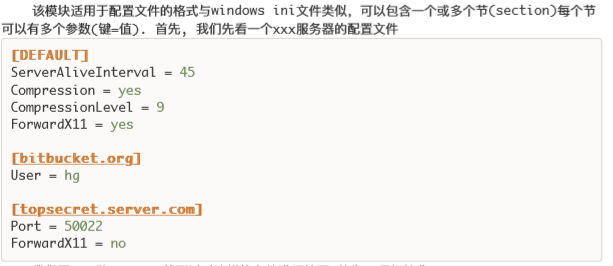
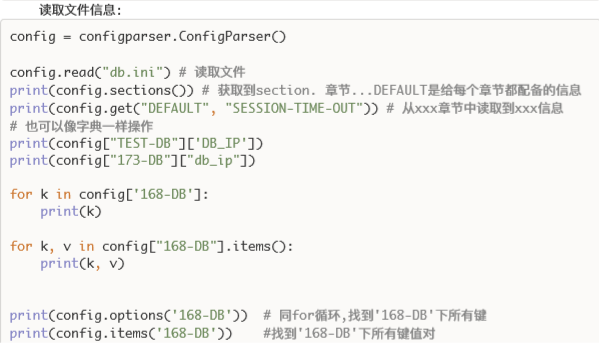
五,configparser模块




序列化(pickle,shelve,json,configparser)的更多相关文章
- python 序列化 pickle shelve json configparser
1. 什么是序列化 我们把变量从内存中变成可存储或传输的过程称之为序列化. 序列化之后,就可以把序列化后的内容写入磁盘,或者通过网络传输到别的机器上. 反过来,把变量内容从序列化的对象重新读到内存里称 ...
- 序列化 pickle shelve json configparser
模块pickle(皮考) dumps(当破死)序列化. 把对象转化成bytes loads(楼死) 反序列化. 吧bytes转化成对象 dic = {"jay": "周杰 ...
- Python 常用模块(2) 序列化(pickle,shelve,json,configpaser)
主要内容: 一. 序列化概述 二. pickle模块 三. shelve模块 四. json模块(重点!) 五. configpaser模块 一. 序列化概述1. 序列化: 将字典,列表等内容转换成一 ...
- 各类模块的粗略总结(time,re,os,sys,序列化,pickle,shelve.#!json )
***collections 扩展数据类型*** ***re 正则相关操作 正则 匹配字符串*** ***time 时间相关 三种格式:时间戳,格式化时间(字符串),时间元组(结构化时间).***`` ...
- python笔记-7(shutil/json/pickle/shelve/xml/configparser/hashlib模块)
一.shutil模块--高级的文件.文件夹.压缩包处理模块 1.通过句柄复制内容 shutil.copyfileobj(f1,f2)对文件的复制(通过句柄fdst/fsrc复制文件内容) 源码: Le ...
- json/pickle/shelve/xml/configparser/hashlib/subprocess - 总结
序列化:序列化指把内存里的数据类型转成字符串,以使其能存储到硬盘或通过网络传输到远程,因为硬盘或网络传输时只能接受bytes为什么要序列化:可以直接把内存数据(eg:10个列表,3个嵌套字典)存到硬盘 ...
- 模块 - json/pickle/shelve/xml/configparser
序列化: 序列化是指把内存里的数据类型转变成字符串,以使其能存储到硬盘或通过网络传输到远程,因为硬盘或网络传输时只能接受bytes. 为什么要序列化: 有种办法可以直接把内存数据(eg:10个列表,3 ...
- Python序列化-pickle和json模块
Python的“file-like object“就是一种鸭子类型.对真正的文件对象,它有一个read()方法,返回其内容.但是,许多对象,只要有read()方法,都被视为“file-like obj ...
- 序列化与反序列化,json,pickle,xml,shelve,configparser模块
序列化与反序列化 什么是序列化?序列化就是将内存中的数据结构转换成一种中间格式存储到硬盘或者基于网络传输.反序列化就是将硬盘中或者网络中传来的一种数据格式转换成内存中数据结构. 为什么要有? 1.可以 ...
- 模块简介:(random)(xml,json,pickle,shelve)(time,datetime)(os,sys)(shutil)(pyYamal,configparser)(hashlib)
Random模块: #!/usr/bin/env python #_*_encoding: utf-8_*_ import random print (random.random()) #0.6445 ...
随机推荐
- 2019.02.11 bzoj1568: [JSOI2008]Blue Mary开公司(线段树)
传送门 题意简述:维护整体加一条线段,求单点极值. 思路: 直接上李超线段树维护即可. 代码: #include<bits/stdc++.h> #define ri register in ...
- 2019.02.11 bzoj4818: [Sdoi2017]序列计数(矩阵快速幂优化dp)
传送门 题意简述:问有多少长度为n的序列,序列中的数都是不超过m的正整数,而且这n个数的和是p的倍数,且其中至少有一个数是质数,答案对201704082017040820170408取模(n≤1e9, ...
- GDB基础学习
GDB基础学习 要调试C/C++程序,首先在编译时,我们必须要把调试信息加到可执行文件中.使用编译器(cc/gcc/g++)的-g参数可以做到这一点,比如: gcc -g test.c -o test ...
- HTTPS抓包之Charles
这里对HTTP请求的抓包操作不做讲解了,只讲解HTTPS的抓包要进行的操作. [说明]:下面以MAC电脑示例,Windows版本可参考:http://weibo.com/ttarticle/p/sho ...
- MySQL--运维内参中的binlog_summary脚本
#!/bin/bash ##===================================================## ## 脚本出自<MySQL运维内参> ##===== ...
- Visual Studio 代码快捷键
目录 1.常用快捷键 2.快速生成代码 3.自定义代码片段 参考: https://blog.csdn.net/qq_32452623/article/details/53838393 https:/ ...
- 背水一战 Windows 10 (82) - 用户和账号: 获取用户的信息, 获取用户的同意
[源码下载] 背水一战 Windows 10 (82) - 用户和账号: 获取用户的信息, 获取用户的同意 作者:webabcd 介绍背水一战 Windows 10 之 用户和账号 获取用户的信息 获 ...
- c# 多线程实现ping 多线程控制控件
这个备份器放在项目目录下面,每次使用就双击一下,因为便捷性,就不采用xml等等储存信息,全部在面板内做,这样可以保证一个exe就运行了. 我发现运行起来还蛮快的,唯一没有实现的是ping通的电脑如果出 ...
- react中使用vw + antd-mobile进行移动端布局
首先create-react-app react-vw一顿简单操作生成个demo 1.cnpm run eject 暴露config文件,再cnpm run start报错 (报错... Canno ...
- maya2015卸载/安装失败/如何彻底卸载清除干净maya2015注册表和文件的方法
maya2015提示安装未完成,某些产品无法安装该怎样解决呢?一些朋友在win7或者win10系统下安装maya2015失败提示maya2015安装未完成,某些产品无法安装,也有时候想重新安装maya ...