增量数据同步中间件DataLink分享(已开源)
项目介绍
名称: DataLink['deitə liŋk]
译意: 数据链路,数据(自动)传输器
语言: 纯java开发(JDK1.8+)
定位: 满足各种异构数据源之间的实时增量同步,一个分布式、可扩展的数据同步系统
开源地址:https://github.com/ucarGroup/DataLink
此次开源为去除内部依赖后的版本(开源的是增量同步子系统),在集团内部datalink和阿里的datax还进行了深度集成,增量(datalink)+全量(datax)共同组成统一的数据交换平台
项目背景
随着神州优车集团业务的高速发展,各种各样的数据同步场景应运而生,原有的系统架构难以支撑复杂多变的业务需求,so,从2016年底开始,团队内部开始酝酿datalink这个产品。着眼于未来,我们的目标是打造一个新平台,满足各种异构数据源之间的实时增量同步,支撑公司业务的快速发展。在充分调研的基础之上,我们发现,没有任何一款开源产品能轻易的满足我们的目标,每个产品都有其明显的短板和局限性,所以最终的选项只有"自行设计"。但自行设计并不是凭空设计,现有的数据交换平台、已有的经验、大大小小的开源产品都是我们的设计根基,与其说是自行设计,倒不如说是站在巨人的肩膀上做了一次飞跃。由此诞生了DataLink这样一个产品,其产品特性主要如下:
- 满足各种异构数据源之间的实时增量同步,提供抽象模型,支持高可扩展
- 平台提供统一的基础设施(高可用、动态负载、同步任务管理、插件管理、监控报警、公用业务组件等等),让设计人员专注于同步插件开发,一次投入,长久受益
- 吸收、整合业内经验,在架构模型、设计方法论、功能特性、可运维、易用性上进行全面的升级,在前瞻性和扩展性上下足功夫,满足公司未来5-10年内的各种同步需求
应用现状
DataLink从2016年12月开始立项,第一版于2017年5月份上线,在神州优车集团内部服役到现在,基本上满足了公司所有业务线的同步需求,目前内部的同步规模大体如下
- 日均数据同步量800G+
- 涉及272个数据库实例之间的3208个同步映射
- 60台Worker+2台Manager机器的集群规模
架构简介
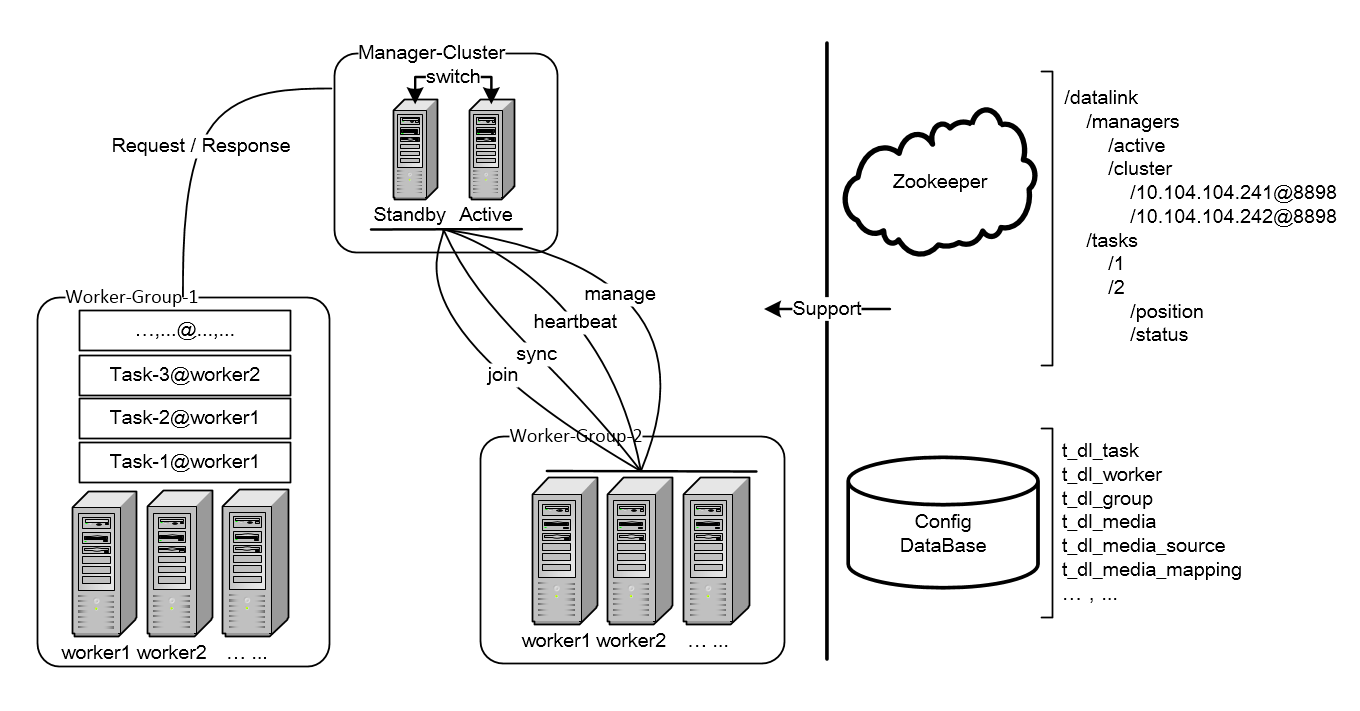
DataLink是典型管理系统架构,Manager(Web管理)+Worker(工作节点):
a. Manager负责Worker的负载均衡、集群的配置管理和系统监控
b. Worker核心功能是管理Task的生命周期,并配合Manager进行Re-Balance
下面对DataLink架构模型重点模块做概要介绍:
Manager
- Manager是整个DataLink集群的大脑
- Manager有三个核心功能
- 担任整个集群的负载均衡协调器:当集群出现状态变更时,第一时间进行Re-Balance
- 负责整个集群的配置管理:提供管理后台,配置发生变更时进行事件通知、缓存刷新等操作,保证系统能够获取到最新的变更
- 监控整个集群的健康状况,主要有:同步是否出现延迟、同步是否出现异常、数据同步TPS、数据同步吞吐量、机器健康状况检查等等
Group
- 分组是DataLink的一个核心概念,Worker和Task在运行之前必须先知道自己属于哪个分组
- 分组的目的是:实现组内自治、组间隔离,不同分组会有不同的参数配置、运行策略、高可用级别等等
Worker
- Worker必须归属于某个分组
- Worker的核心功能是管理Task的生命周期,并配合Manager进行Re-Balance
- Worker运行哪些Task受Manager的分配
Task
- Task的核心功能是进行数据同步
- 一个Task由一个TaskReader和多个TaskWriter组成,Reader和Writer使用独立的Classloader
- Task必须归属于某个分组
(Re-)Balance
- (Re-)Balance的定义:通过一定的负载均衡策略,使Task在Worker节点上均衡的分布
- (Re-)Balance的单位是Group,一个分组发生(Re-)Balance不会影响其它分组的正常运行
- 发生(Re-)Balance的时机
- Manager发生主备切换
- 新的Worker加入分组
- 某个Worker离开分组
- 新增Task
- 删除Task
Plugin
- 插件模型最大的意义在于解耦和复用,只需要提供一套基础框架,开发一系列同步插件,通过配置组合便可以支持"无限多"的同步场景
- 插件划分为两种:Reader插件和Writer插件,插件之间通过Task串联起来
- Task运行时,每个插件都有自己独立的Classloader,保证插件之间的jar包隔离
Mysql
- DataLink的运行需要依赖各种配置信息,这些配置信息统一保存到Mysql中
- DataLink在运行过程中会动态产生监控和统计数据,这些数据也统一保存到Mysql中
- 存储的配置信息主要有: 同步任务信息、工作节点信息、分组信息、数据源配置信息、映射规则信息、监控信息、角色权限信息等
Zookeeper
- Manager的高可用需要依赖于zookeeper,通过抢占和监听"/datalink/managers/active"节点,实现秒级switch
注:Worker的高可用并不依赖zookeeper,只要manager能够保证高可用,worker就是高可用的 - Task会将运行时信息注册到zookeeper,注册信息主要有两类
- Task的状态信息(运行、暂停还是出错),通过状态信息可以监控task的健康状况
- Task的position信息,通过postion信息可以查看当前的同步进度,也可以实现故障恢复
Netty&Jetty
- Manager使用Netty提供Tcp服务,用来监听Worker端发送的Coordinator信息(注:Netty只用来做高可用和负载均衡)
- Manager使用Jetty提供Http服务,主要用来提供web管理功能和接收Worker发送的监控和统计数据
- Worker使用Jetty提供Http服务,主要用来接收Manager发送的管理指令
Kafka-Client
- DataLink套用了kafka的(Re-)balance协议
- 在Worker端和Manager端分别定义了各自的Coordinate模块,这些模块都需要依赖kafka的client包
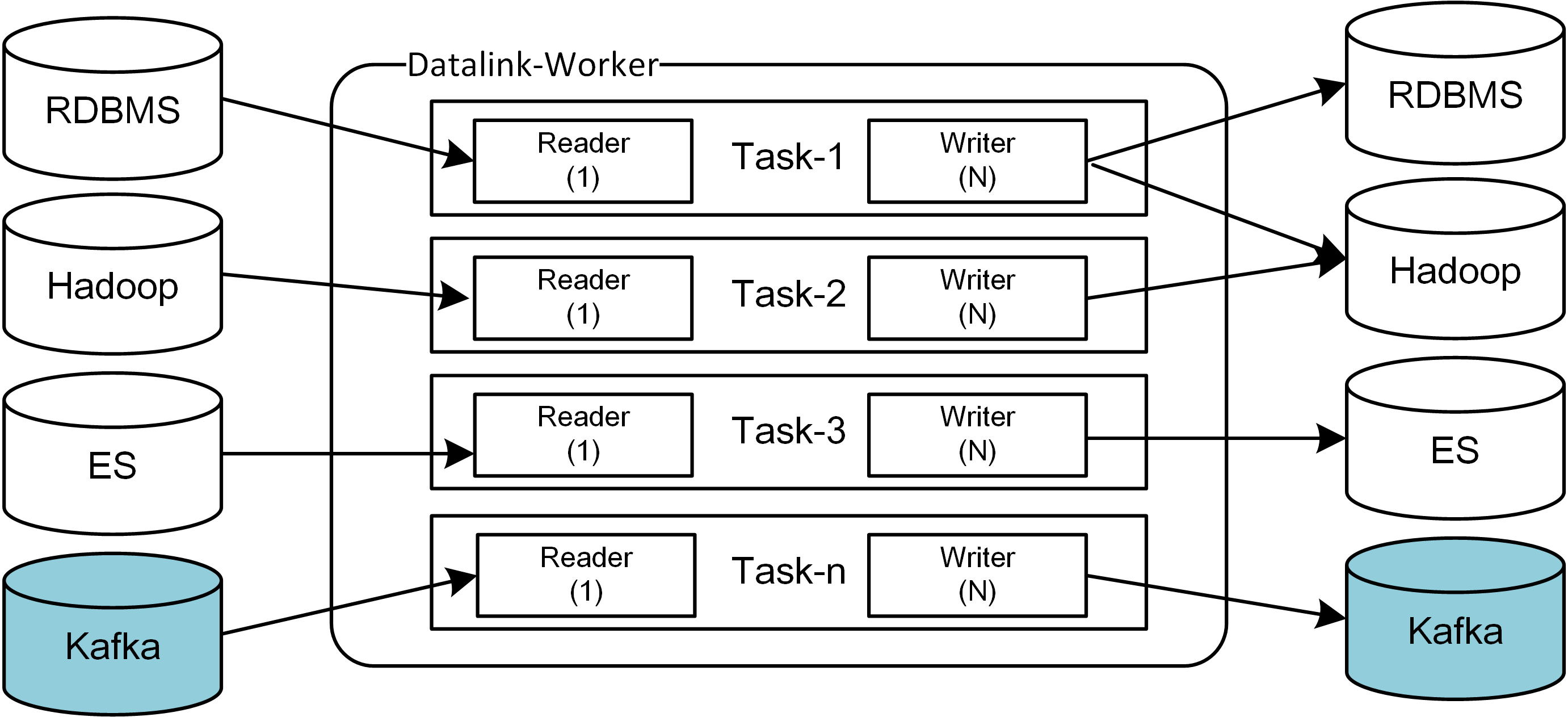
同步模型
插件体系
- 插件体系一般由两部分组成:Framework+Plugin,DataLink中的Framework主要指【TaskRuntime】,Plugin对应的是各种类型的【TaskReader&TaskWriter】
TaskRuntime
- 提供了Task的高层抽象、Task的运行时环境和Task的插件规范
TaskReader&TaskWriter
- 一个个具体的数据同步插件,遵从Task插件规范,功能自治,和TaskRuntime完全解耦,理论上插件数量可无限扩充
Task
DataLink中数据同步的基本单位是Task,一个Worker进程中可以运行一批Task,一个运行中的Task由一个TaskReader和至少一个TaskWriter组成,即有:
程序运行期,同一类型的插件在一个进程中可以有多个实例,实例个数取决于有多少个Task用到了该插件
程序运行期,插件的生命周期归属于Task,在不同的生命周期阶段,依照Task的配置信息或相关指令,进行创建、初始化、运行或销毁等操作
理论上,TaskReader和TaskWriter可动态任意组合(能否组合,主要取决于待组合的TaskWriter能否适配TaskReader的Record类型)
理论上,每新增一种插件,可支持的同步场景可以成倍数的增加(具体几倍,和插件类型和当前已有的插件数量有关系),新增一个TaskReader,可新增的同步场景数量取决于已有TaskWriter的数量,反之亦然
目前,DataLink的TaskReader支持的类型有MYSQL, FLEXIBLEQ, HBASE,TaskWriter支持的类型有Rdbms、ElasticSearch、Hdfs、HBase、FlexibleQ、SDDL
ClassLoader
Datalink-Worker进程中,每个类型的插件,都有自己独立的classloader和classpath。
原因很简单:class版本隔离的需要,DataLink中,可以开发任意多个插件,出现jar包冲突很正常,必须通过classloader隔离这些冲突。
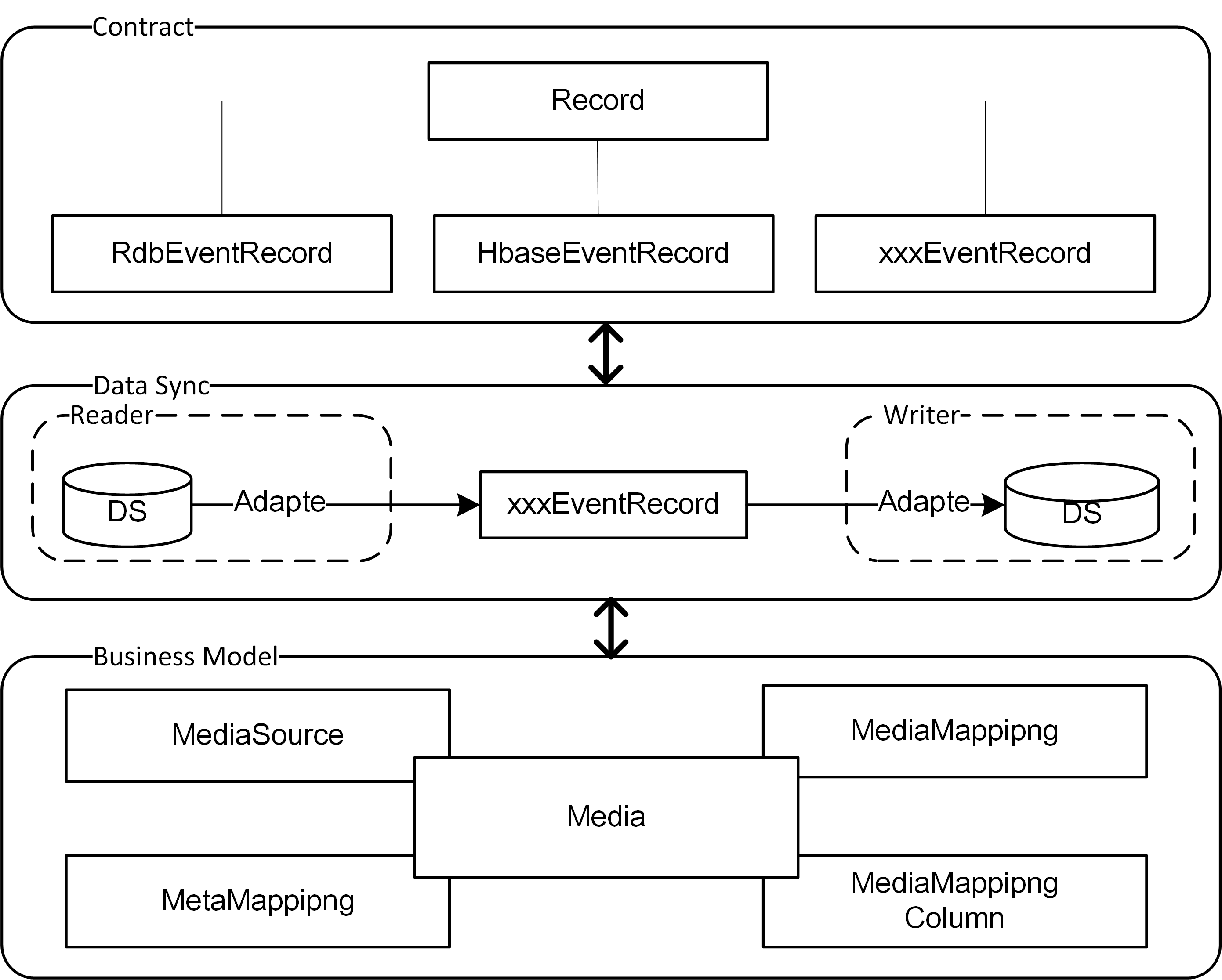
Contract
- Contract是针对某种类型的数据源定义的【数据模型】,是一份契约和规范,是最高层次的抽象,和编程语言无关,和具体平台无关,和DataLink也没有必然关系
- Contract是TaskReader和TaskWriter可任意组合的关键,TaskReader输出Contract数据,TaskWriter输入Contract数据,互不感知,但都理解Contract定义的【数据模型】
- Contract定义的【数据模型】的主要表现形式是Record,如:RdbEventRecord,HRecord
Adapt
TaskReader:
负责输出Contract数据,适配模式很简单,一对一,直接把底层数据组装成对应的Record即可,如:MysqlTaskReader对应RdbEventRecordTaskWriter:
负责输入Contract数据,并写入目标数据源。TaskWriter可以接收不同类型的【数据模型】,内部由不同的Handler把不同【数据模型】的数据写入目标数据源
应用场景
DataLink可以支撑的常见应用场景有:
- ReSharding
- BigData
- CQRS
- EDA
- SearchBuild
- 基础参数共享
- 实时归档
- 数据镜像
- 数据库的迁库、拆库、合库以及灾备等等
具体介绍可参见git文档:https://github.com/ucarGroup/DataLink/wiki/1.9_%E6%B7%B1%E5%85%A5%E5%9C%BA%E6%99%AF
项目未来
datalink项目借鉴了很多开源产品的思想,这里要重点感谢的产品有:canal,otter,datax,yugong,databus,kafka-connect,ersatz
站在巨人的肩膀上,我们进行了开源,一方面回馈社区,一方面抛砖引玉
展望未来,我们希望这个项目能够活跃起来,为社区做出更大的贡献,内部的各种新特性也会尽快同步到开源版本,同时也希望有更多的人参与进来
目前内部正在规划中的功能有:
- 双机房(中心)同步
- 通用审计功能
- 各种同步工具
- 等
问题反馈
目前有关datalink的问题交流方式有如下几种,欢迎各位加入进行技术讨论。
- qq交流群: 758937055
- 邮件交流: tech_plat_data@ucarinc.com
- 报告issue:issues

增量数据同步中间件DataLink分享(已开源)的更多相关文章
- 阿里Canal框架(数据同步中间件)初步实践
最近在工作中需要处理一些大数据量同步的场景,正好运用到了canal这款数据库中间件,因此特意花了点时间来进行该中间件的的学习和总结. 背景介绍 早期,阿里巴巴B2B公司因为存在杭州和美国双机房部署,存 ...
- 微服务之数据同步Porter
Porter是一款数据同步中间件,主要用于解决同构/异构数据库之间的表级别数据同步问题. 背景 在微服务架构模式下深刻的影响了应用和数据库之间的关系,不像传统多个服务共享一个数据库,微服务架构下每个服 ...
- 数据同步Datax与Datax_web的部署以及使用说明
一.DataX3.0概述 DataX 是一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL.Oracle等).HDFS.Hive.ODPS.HBase.FTP等各种异构数据源之间稳定高 ...
- 基于 MySQL Binlog 的 Elasticsearch 数据同步实践 原
一.背景 随着马蜂窝的逐渐发展,我们的业务数据越来越多,单纯使用 MySQL 已经不能满足我们的数据查询需求,例如对于商品.订单等数据的多维度检索. 使用 Elasticsearch 存储业务数据可以 ...
- Mysql、ES 数据同步
数据同步中间件 不足:不支持 ES6.X 以上.Mysql 8.X 以上 ime 标识最大时间 logstash全量.增量同步解决方案 https://www.elastic.co/cn/downlo ...
- 基于MySQL Binlog的Elasticsearch数据同步实践
一.为什么要做 随着马蜂窝的逐渐发展,我们的业务数据越来越多,单纯使用 MySQL 已经不能满足我们的数据查询需求,例如对于商品.订单等数据的多维度检索. 使用 Elasticsearch 存储业务数 ...
- 全量、增量数据在HBase迁移的多种技巧实践
作者经历了多次基于HBase实现全量与增量数据的迁移测试,总结了在使用HBase进行数据迁移的多种实践,本文针对全量与增量数据迁移的场景不同,提供了1+2的技巧分享. HBase全量与增量数据迁移的方 ...
- SSIS数据同步实践
SSIS数据同步实践 背景 在已初步验证不同实例下同构表数据同步方案之后,为了实现数据持续同步,需使用SSIS把之前的生成脚本和执行脚本的两个步骤组合在一起部署成包之后,通过JOB定时去执行: 测 ...
- Hbase实用技巧:全量+增量数据的迁移方法
摘要:本文介绍了一种Hbase迁移的方法,可以在一些特定场景下运用. 背景 在Hbase使用过程中,使用的Hbase集群经常会因为某些原因需要数据迁移.大多数情况下,可以跟用户协商用离线的方式进行迁移 ...
随机推荐
- NFS网络储存系统
为什么用NFS网络文件存储系统? 1)实现数据信息统一一致 2)节省局域网数据同步传输的带宽 3)节省网站架构中服务器硬盘资源 NFS系统存储原理介绍 RPC服务类似一个中介服务,NFS服务端与NFS ...
- Python模块:operator简单介绍
Python官方文档地址:https://docs.python.org/3.6/library/operator.html?highlight=operator Operator提供的函可用于对象比 ...
- thinkphp引入模板view
3.1 模板放在哪儿? 放在模块的view目录下并且每个控制器的模板,要在与控制器同名的目录下. 以 index.php/Home/User/add则对应的模板在 /Home/view/User/ad ...
- java——异常类、异常捕获、finally、异常抛出、自定义异常
编译错误:由于编写程序不符合程序的语法规定而导致的语法问题. 运行错误:能够顺利的编译通过,但是在程序运行过程中产生的错误. java异常类都是由Throwable类派生而来的,派生出来的两个分支分别 ...
- my.答题
20170821增加: http://www.119you.com/mhxy/yxgl/738653.shtml 1.三界奇缘 http://my.netease.com/forum.php?mod= ...
- ORACLE 12.2 RAC TNS-12520 遭遇连接风爆 (connection storm)
故障现象:数据库迁移到新环境刚过两天.今天生产核心数,断断继续的告警连接不上.这是问题! 如理思路:1.查看alert日志,日志无报错 2.查看连接数,参数设置的20 ...
- C# 利用ITextSharp导出PDF文件
最近项目中需要导出PDF文件,最后上网搜索了一下,发现ITextSharp比较好用,所以做了一个例子: public string ExportPDF() { //ITextSharp Usage / ...
- Android NDK开发 字符串(四)
几个概念首先要明确: java内部是使用16bit的unicode编码(UTF-16)来表示字符串的,无论中文英文都是2字节: jni内部是使用UTF-8编码来表示字符串的,UTF-8是变长编码的un ...
- [引]雅虎日历控件 Example: Two-Pane Calendar with Custom Rendering and Multiple Selection
本文转自:http://yuilibrary.com/yui/docs/calendar/calendar-multipane.html This example demonstrates how t ...
- jemeter的简单使用
建立测试计划 启动jmeter后,jmeter会自动生成一个空的测试计划,用户可以基于该测试计划建立自己的测试计划. 添加线程组 一个性能测试请求负载是基于一个线程组完成的.一个测试计划必须有一个线程 ...