FastRCNN 训练自己数据集 (1编译配置)
http://www.cnblogs.com/louyihang-loves-baiyan/p/4885659.html
按照博客的教程配置,但自己在服务器上配置时,USE_CUDNN = 1会报错,注释掉反而能正常运行。
添加hdf5路径按照教程添加:
INCLUDE_DIRS := $(PYTHON_INCLUDE) /usr/local/include /usr/include/hdf5/serial
LIBRARY_DIRS := $(PYTHON_LIB) /usr/local/lib /usr/lib /usr/lib/x86_x64-linux-gnu/hdf5/serial
手动下载fast_rcnn_models模型会快很多,解压后将模型文件夹放到data目录下
直接运行demo.py会报错:no display name and no $DISPLAY environment variable
直接在服务器上成功的实现方式:backend还是TKAgg,在demo代码里加入import matplotlib matplotlib.use('Agg')两句。
用自己电脑连接服务器使用,backend必须改成Agg才不报错,demo里依旧加入import matplotlib matplotlib.use('Agg')两句,但不能正常显示图片。
https://my.oschina.net/swuly302/blog/94915
http://blog.csdn.net/oldjwu/article/details/5090549
http://www.jianshu.com/p/3f4b89aaf057
在编译过程中会出现如下警告:
服务器安装的是CUDA版本是8.0,从CUDA 8.0开始compute capability 2.0和2.1被弃用了,所以可以将Makefile.config中-gencode arch=compute_20,code=sm_20 和-gencode arch=compute_20,code=sm_21这两行删除,去除之后就没有警告了。
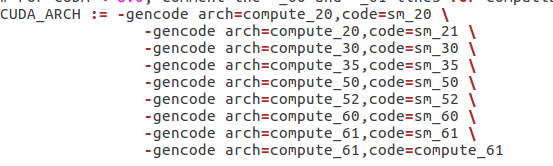
至于为何需要在lib文件夹make,然后在caffe文件夹make -j8 && make pycaffe,我认为是建立caffe的python接口。
FastRCNN 训练自己数据集 (1编译配置)的更多相关文章
- Fast RCNN 训练自己数据集 (1编译配置)
FastRCNN 训练自己数据集 (1编译配置) 转载请注明出处,楼燚(yì)航的blog,http://www.cnblogs.com/louyihang-loves-baiyan/ https:/ ...
- 实践详细篇-Windows下使用VS2015编译的Caffe训练mnist数据集
上一篇记录的是学习caffe前的环境准备以及如何创建好自己需要的caffe版本.这一篇记录的是如何使用编译好的caffe做训练mnist数据集,步骤编号延用上一篇 <实践详细篇-Windows下 ...
- 使用py-faster-rcnn训练VOC2007数据集时遇到问题
使用py-faster-rcnn训练VOC2007数据集时遇到如下问题: 1. KeyError: 'chair' File "/home/sai/py-faster-rcnn/tools/ ...
- YOLOV4在linux下训练自己数据集(亲测成功)
最近推出了yolo-v4我也准备试着跑跑实验看看效果,看看大神的最新操作 这里不做打标签工作和配置cuda工作,需要的可以分别百度搜索 VOC格式数据集制作,cuda和cudnn配置 我们直接利用 ...
- Scaled-YOLOv4 快速开始,训练自定义数据集
代码: https://github.com/ikuokuo/start-scaled-yolov4 Scaled-YOLOv4 代码: https://github.com/WongKinYiu/S ...
- 转载:Centos7 从零编译配置Memcached
序言 Memcached 是一个高性能的分布式内存对象缓存系统,用于动态Web应用以减轻数据库负载.它通过在内存中缓存数据和对象来减少读取数据库的次数,从而提高动态.数据库驱动网站的速度. Memca ...
- [原创]Centos7 从零编译配置Memcached
序言 Memcached 是一个高性能的分布式内存对象缓存系统,用于动态Web应用以减轻数据库负载.它通过在内存中缓存数据和对象来减少读取数据库的次数,从而提高动态.数据库驱动网站的速度. Memca ...
- 大型项目使用Automake/Autoconf完成编译配置
http://www.cnblogs.com/xf-linux-arm-java-android/p/3590770.htmlhttp://blog.csdn.net/zengraoli/articl ...
- CentOS6.5 Nginx优化编译配置[续]
继续上文CentOS6.5 Nginx优化编译配置本文记录有关Nginx系统环境的一些细节设置,有关Nginx性能调整除了配置文件吻合服务器硬件之前就是关闭不必要的服务.磁盘操作.文件描述符.内核调整 ...
随机推荐
- 效率工具(fswatch,rsync)
mac 安装 brew: ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/in ...
- Django权限1
1.权限,说白了就是你有资格访问这个网址,而别人每一资格:你有资格进行增删改查,而别人只有查的权限 2.新建是3张表: #用户表 class User(models.Model): name = mo ...
- mysql 8 修改root 密码
主要参考:https://dev.mysql.com/doc/refman/8.0/en/resetting-permissions.html 需要注意的是创建文件的时候需要保存为 utf-8 无 B ...
- Host 'XXX' is not allowed to connect to this MySQL server解决方案
如何允许远程连接mysql数据库呢,操作如下: 首先登录账号 mysql -uroot -p 使用mysql用户 use mysql 如果报此类错:ERROR 1820 (HY000): You mu ...
- python3.4 x86_64-linux-gnu-gcc Error
running install running build running build_py creating build creating build/lib.linux-x ...
- redis要注意的一些知识
除了存取数据,redis还可以支持mq等操作,这里面有些小细节,需要注意一下: ---------------------------------------- 1.事务处理 大家都说redis支持事 ...
- Spring核心-IOC-AOP-模版
1. POM- 1.1 中央仓库 1.2 各包作用 spring-core.jar 核心工具类 spring-beans.jar 是所有应用都要用到的,它包含访问配置文件.创建和管理bean 以及进行 ...
- TP扩展Xxtea.class.php加密解密函数用法
http://www.coolcode.org/?action=show&id=128这里可以查到一个相关文章. 附上xiunobbs里的代码,自己加了点注释,欢迎大牛批评指正 //将数值数组 ...
- Devexpress Xtrareports 创建多栏报表
根据官方回答:多列或多行(取决于当前的多栏设置)呈现数据的报表 这种报表是有用的,例如,当每个明细区都只显示少量数据.并且需要在一列的右侧打印下一个明细区时,这样就能充分利用整个页面的宽度,此外,当创 ...
- 如何在eclipse查看jdk源码(src.zip)
在eclipse编写代码的过程中,有时候想点进去看看jdk的源码,了解下里面具体的实现.在没有任何配置的情况下,应该是看不到源码的. 其实只需要把jdk安装目录下的src.zip压缩包添加到eclip ...