在Scala IDEA for Eclipse或IDEA里程序编译实现与在Spark Shell下的对比(其实就是那么一回事)
不多说,直接上干货!
比如,我这里拿主成分分析(PCA)。
1、主成分分析(PCA)的概念介绍
主成分分析(PCA) 是一种对数据进行旋转变换的统计学方法,其本质是在线性空间中进行一个基变换,使得变换后的数据投影在一组新的“坐标轴”上的方差最大化,随后,裁剪掉变换后方差很小的“坐标轴”,剩下的新“坐标轴”即被称为 主成分(Principal Component) ,它们可以在一个较低维度的子空间中尽可能地表示原有数据的性质。主成分分析被广泛应用在各种统计学、机器学习问题中,是最常见的降维方法之一。PCA有许多具体的实现方法,可以通过计算协方差矩阵,甚至是通过上文提到的SVD分解来进行PCA变换。
2、主成分分析(PCA)的变换
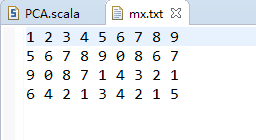
MLlib提供了两种进行PCA变换的方法,第一种与上文提到的SVD分解类似,位于org.apache.spark.mllib.linalg包下的RowMatrix中,这里,我们同样读入上文中提到的mx.txt文件,对其进行PCA变换:
在Spark Shell里
scala> import org.apache.spark.mllib.linalg.Vectors
scala> import org.apache.spark.mllib.linalg.distributed.RowMatrix
scala> val data = sc.textFile("mx.txt").map(_.split(" ").map(_.toDouble)).map(line => Vectors.dense(line))
data: org.apache.spark.rdd.RDD[org.apache.spark.mllib.linalg.Vector] = MapPartitionsRDD[] at map at :
//通过RDD[Vectors]创建行矩阵
scala> val rm = new RowMatrix(data)
rm: org.apache.spark.mllib.linalg.distributed.RowMatrix = org.apache.spark.mllib.linalg.distributed.RowMatrix@4397952a
//保留前3个主成分
scala> val pc = rm.computePrincipalComponents()
pc: org.apache.spark.mllib.linalg.Matrix =
-0.41267731212833847 -0.3096216957951525 0.1822187433607524
0.22357946922702987 -0.08150768817940773 0.5905947537762997
-0.08813803143909382 -0.5339474873283436 -0.2258410886711858
0.07580492185074224 -0.56869017430423 -0.28981327663106565
0.4399389896865264 -0.23105821586820194 0.3185548657550075
-0.08276152212493619 0.3798283369681188 -0.4216195003799105
0.3952116027336311 -0.19598446496556066 -0.17237034054712738
0.43580231831608096 -0.023441639969444372 -0.4151661847170216
0.468703853681766 0.2288352748369381 0.04103087747663084
可以看到,主成分矩阵是一个尺寸为(9,3)的矩阵,其中每一列代表一个主成分(新坐标轴),每一行代表原有的一个特征,而a.mat矩阵可以看成是一个有4个样本,9个特征的数据集,那么,主成分矩阵相当于把原有的9维特征空间投影到一个3维的空间中,从而达到降维的效果。可以通过矩阵乘法来完成对原矩阵的PCA变换,可以看到原有的(4,9)矩阵被变换成新的(4,3)矩阵。
scala> val projected = rm.multiply(pc)
projected: org.apache.spark.mllib.linalg.distributed.RowMatrix = org.apache.spark.mllib.linalg.distributed.RowMatrix@2a805829
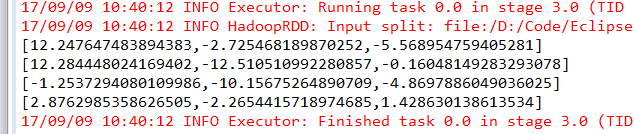
scala> projected.rows.foreach(println)
[12.247647483894383,-2.725468189870252,-5.568954759405281]
[2.8762985358626505,-2.2654415718974685,1.428630138613534]
[12.284448024169402,-12.510510992280857,-0.16048149283293078]
[-1.2537294080109986,-10.15675264890709,-4.8697886049036025]
需要注意的是,MLlib提供的PCA变换方法最多只能处理65535维的数据。
在Scala IDEA for Eclipse或IDEA里程序编译实现

参考
http://mocom.xmu.edu.cn/article/show/58627a2faa2c3f280956e7ae/0/1
在Scala IDEA for Eclipse或IDEA里程序编译实现与在Spark Shell下的对比(其实就是那么一回事)的更多相关文章
- Eclipse \ MyEclipse \Scala IDEA for Eclipse里如何将控制台console输出的过程记录全程保存到指定的文本文件(图文详解)
不多说,直接上干货! 问题详情 运行Java程序的时候,控制台输出过多,或者同时运行多个Java程序,输出结果一闪而过的时候,可以考虑将将控制台输出,改为输出到文本文件.无须修改Java代码,引入流这 ...
- Scala IDEA for Eclipse里用maven来创建scala和java项目代码环境(图文详解)
这篇博客 是在Scala IDEA for Eclipse里手动创建scala代码编写环境. Scala IDE for Eclipse的下载.安装和WordCount的初步使用(本地模式和集群模式) ...
- Scala IDE for Eclipse的下载、安装和WordCount的初步使用(本地模式和集群模式)
包括: Scala IDE for Eclipse的下载 Scala IDE for Eclipse的安装 本地模式或集群模式 我们知道,对于开发而言,IDE是有很多个选择的版本.如我们大部分人经常 ...
- spark最新源码下载并导入到开发环境下助推高质量代码(Scala IDEA for Eclipse和IntelliJ IDEA皆适用)(以spark2.2.0源码包为例)(图文详解)
不多说,直接上干货! 前言 其实啊,无论你是初学者还是具备了有一定spark编程经验,都需要对spark源码足够重视起来. 本人,肺腑之己见,想要成为大数据的大牛和顶尖专家,多结合源码和操练编程. ...
- 用maven来创建scala和java项目代码环境(图文详解)(Intellij IDEA(Ultimate版本)、Intellij IDEA(Community版本)和Scala IDEA for Eclipse皆适用)(博主推荐)
不多说,直接上干货! 为什么要写这篇博客? 首先,对于spark项目,强烈建议搭建,用Intellij IDEA(Ultimate版本),如果你还有另所爱好尝试Scala IDEA for Eclip ...
- 如何在Eclipse/Myeclipse/Scala IDEA for Eclipse 中正确删除已经下载过的插件(图文详解)
不多说,直接上干货! 见 Eclipse/Myeclipse/Scala IDEA for Eclipse里两种添加插件的方法(在线和离线) 第一步 :在菜单栏中,找到help-------insta ...
- CentOS6.5下如何正确下载、安装Intellij IDEA、Scala、Scala-intellij-bin插件、Scala IDE for Eclipse助推大数据开发(图文详解)
不多说,直接上干货! 第一步:卸载CentOS中自带openjdk Centos 6.5下的OPENJDK卸载和SUN的JDK安装.环境变量配置 第二步:安装Intellij IDEA 若是3节点 ...
- jdk1.8源码包下载并导入到开发环境下助推高质量代码(Eclipse、MyEclipse和Scala IDEA for Eclipse皆适用)(图文详解)
不多说,直接上干货! jdk1.8 源码, Linux的同学可以用的上. 由于源码JDK是前版本的超集, 所以1.4, 1.5, 1.6, 1.7都可以用的上. 其实大家安装的jdk路径下,这 ...
- ubuntu下eclipse scala开发插件(Scala IDE for Eclipse)安装
1. 环境介绍 系统:ubuntu16.04(不过和系统版本关系不大) elipse:Neon.1aRelease (4.6.1) 2. 插件介绍 Scala IDE for eclipse是elip ...
随机推荐
- 杂项:BI(商业智能)
ylbtech-杂项:BI(商业智能) 商业智能(BI,Business Intelligence). BI(Business Intelligence)即商务智能,它是一套完整的解决方案,用来将企业 ...
- VisualGDB系列1:VisualGDB总体概述
根据VisualGDB官网(https://visualgdb.com)的帮助文档大致翻译而成.主要是作为个人学习记录.有错误的地方,Robin欢迎大家指正. 本文总体介绍VisualGDB能给你带来 ...
- ES6学习之Promise
详见之前文章:Promise详解
- Ubuntu 切换root用户是时出现su Authentication failure
su root 时出现错误su Authentication failure 原因是没有给root用户设置密码 sudo passwd root
- .net之特性(Attribute)
看了一些关于这方面的文档,自我总结: 特性(Attribute)就是对一个方法或类做的一个额外的属性说明,也就是附加说明 下面是我自己抄的一个实例程序: using System; using Sys ...
- Ubuntu W: GPG 错误:下列签名无效: BADSIG 84DBCE2DCEC45805 Launchpad PPA fo
Ubuntu12.04 安装R语言的时候出现的报错. 研究了两个晚上,解决办法如下,跟参考贴有点出入: ############################################### ...
- WHAT is CPU负载?
WHAT?? 1.CPU负载都有哪些? cpu负载的定义:在一般情况下可以将单核心cpu的负载看成是一条单行的桥,数字1代表cpu刚好能够处理过来,即桥上能够顺利通过所有的车辆,桥外没有等待的车辆,桥 ...
- Centos下添加/删除用户
useradd具体参数 [root@yhwang ~] useradd -h Usage: useradd [options] LOGIN useradd -D useradd -D [options ...
- 【Qt文档阅读】事件系统
在Qt中,事件对象都继承于QEvent类,它表示应用程序内部或由于应用程序需要了解的外部活动而发生的事情.事件可以由QObject子类的任何实例接收和处理,尤其是widget.本文档描述如何在典型应用 ...
- UML——前两章
前言 软件开发过程中,在生命周期中,我们大都知道要写文档,但是针对这种团队集体完成的事情,如果中间出现了人员流动问题,这时侯有文档仅仅是不够的.为了让大多数开发人员和用户能直观的了解软件开发的进度和流 ...