Scrapy 爬虫实例教程(一)---简介及资源列表

Scrapy(官网 http://scrapy.org/)是一款功能强大的,用户可定制的网络爬虫软件包。其官方描述称:"
Scrapy is a fast high-level screen scraping and web crawling framework, used to crawl websites and extract structured data from their pages. It can be used for a wide range of purposes, from data mining to monitoring and automated testing
"
Scrapy在github中有源码托管https://github.com/scrapy/scrapy,其安装可以参考github中提供的安装方法(大百度中也提供了很多安装方法的描述)。另外网站1和网站2提供了scrapy的使用方法和简单实例(小编后续随笔也会简单写一个scrapy实例,供大家参考)。
Scrapy的爬虫原理:
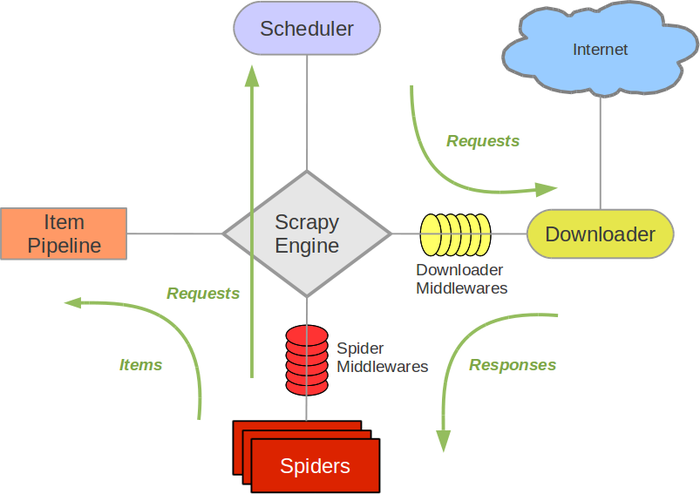
”盗用“的scrapy 官网中的scrapy核心框架图
Scrapy Engine是scrapy软件的核心,他负责各个组件的协调处理
Scheduler是调度器,负责爬去队列的管理,如Request的入队和出队管理
Item Pipeline 是抓取内容的核心组件,用户想要获取的内容可以写入item 然后再pipeline中设计数据的流向比如写入文件或是持久化到数据库中
Downloader 则是scrapy与web site接触的端口,负责根据Request 请求网页然后以response的形式返回用户处理接口(默认是 spider的parse函数)
Spider则是用户定制兴趣内容的模块,在scrapy的spiders中内置了BaseSpider,CSVFeedSpider,CrawlerSpider,用户可以根据情况选择合适spider继承与开发
Spider Middlewares则是Spider与Scrapy Engine 的中间层,用户可以个性化定义Spider向Engine传输过程
Scrpay的运行过程:
(1)Engine从Spider中获取一个需要爬取的URL(从spider中start_url获取),并以Request的形式在Scheduler中列队。
(2)Scheduler根据列队情况,把Request发送给Downloader,Downloader根据Request请求网页,并获取网页内容。
(3)网页内容以Response的形式经过Engine发送给Spider,并根据用户解析生成Item,发送给Pipeline。
(4)Pipeline根据获得的item和settings中的设置,处理item(process_item)把数据输出到文件或是数据库中。
上述过程反复进行,直到没有新的请求为止(此过程是一个异步处理过程)。
个人整理的Scrapy资源列表(望笑纳):
(1)scrapy中文教程
http://scrapy-chs.readthedocs.io/zh_CN/latest/intro/overview.html
(2)一个不错的scrapy学习博客
http://blog.csdn.net/column/details/younghz-scrapy.html
(3)scrapy 官方wiki
https://github.com/scrapy/scrapy/wiki
(4)scrapy实例
https://github.com/jackgitgz/CnblogsSpider
Scrapy 爬虫实例教程(一)---简介及资源列表的更多相关文章
- Scrapy爬虫实例教程(二)---数据存入MySQL
书接上回 实例教程(一) 本文将详细描述使用scrapy爬去左岸读书所有文章并存入本地MySql数据库中,文中所有操作都是建立在scrapy已经配置完毕,并且系统中已经安装了Mysql数据库(有权限操 ...
- scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250
scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250 前言 经过上一篇教程我们已经大致了解了Scrapy的基本情况,并写了一个简单的小demo.这次我会以爬取豆瓣电影TOP250为例进一步为大 ...
- scrapy爬虫框架教程(二)-- 爬取豆瓣电影
前言 经过上一篇教程我们已经大致了解了Scrapy的基本情况,并写了一个简单的小demo.这次我会以爬取豆瓣电影TOP250为例进一步为大家讲解一个完整爬虫的流程. 工具和环境 语言:python 2 ...
- 简单scrapy爬虫实例
简单scrapy爬虫实例 流程分析 抓取内容:网站课程 页面:https://edu.hellobi.com 数据:课程名.课程链接及学习人数 观察页面url变化规律以及页面源代码帮助我们获取所有数据 ...
- scrapy爬虫实例(1)
爬虫实例 对象 阳光问政平台 目标 : 主题,时间,内容 爬取思路 预先设置好items import scrapy class SuperspiderItem(scrapy.Item): title ...
- Scrapy爬虫实例——校花网
学习爬虫有一段时间了,今天使用Scrapy框架将校花网的图片爬取到本地.Scrapy爬虫框架相对于使用requests库进行网页的爬取,拥有更高的性能. Scrapy官方定义:Scrapy是用于抓取网 ...
- Scrapy爬虫框架教程(四)-- 抓取AJAX异步加载网页
欢迎关注博主主页,学习python视频资源,还有大量免费python经典文章 sklearn实战-乳腺癌细胞数据挖掘 https://study.163.com/course/introduction ...
- python scrapy 爬虫实例
1 创建一个项目 scrapy startproject basicbudejie 2 编写爬虫 import scrapy class Basicbudejie(scrapy.Spider): na ...
- scrapy爬虫框架处理流程简介
1.SPIDERS的yeild将request发送给ENGIN2.ENGINE对request不做任何处理发送给SCHEDULER3.SCHEDULER( url调度器),生成request交给ENG ...
随机推荐
- PHP 工厂模式 实例讲解
简单工厂模式:①抽象基类:类中定义抽象一些方法,用以在子类中实现②继承自抽象基类的子类:实现基类中的抽象方法③工厂类:用以实例化对象 看完文章再回头来看下这张图,效果会比较好 1 采用封装方式 2 3 ...
- Ultimus BPM 金融与证券行业应用解决方案
Ultimus BPM 金融与证券行业应用解决方案 行业应用需求 金融服务业的整合与全球化发展,带来高度竞争的国际市场,所牵涉的产业包括了商业.贷款.投资银行,以及保险公司和许多其它为企业和消费者提供 ...
- 详解Linux进程(作业)的查看和杀死
目录: 引入进程 进程 线程 PS命令 TOP命令 其他查看进程命令 进程的优先级 作业控制机制 kill命令 一.引入进程 1.内存划分为:用户空间和内核空间 1.在用户空间里运行的进程,就是用户进 ...
- neutron flat和vxlan网络访问外网流量走向
OpenStack版本:Mitaka 物理节点: Hostname Management IP Tunnel IP Role test-ctrl-01 192.168.100.11 192.168.1 ...
- vue-动手做个选择城市
查看完整的代码请到 我的github地址 https://github.com/qianyinghuanmie/vue2.0-demos 一.结果展示 二.前期准备: 1.引入汉字转拼音的插件, ...
- VR全景智慧城市--2017年VR项目加盟将是一个机遇
全景智慧城市项目是河南艺境空间文化传播有限公司自主开发的国内第一家商业全景平台, 旨在构建全景城市,实现智慧生活,让人们随时随地身临其境拥有全世界,享受快捷.真实.趣味.优质生活. 以VR虚拟现实技术 ...
- CSS小技巧-煎蛋的画法~
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title> ...
- 关于bootstrap中cropper的截图上传问题
之前做一个关于截图的东东,搞了好久终于弄好了,其主要关键是把前端截图的数据(x坐标,y坐标,宽度,高度和旋转角度)传到后台,然后在后台对图片做相关处理,记录一下方便以后查看. 后台配置为ssm. Ja ...
- 第一天上午——HTML网页基础知识以及相关内容
今天上午学习了HTML基础知识以及相关内容,还有DW的基本使用方法. HTML(HyperText Markup Language):超文本标记语言,超文本:网页中除了包含文本文字之外,还包含了图片, ...
- Linux命令不熟悉(记录)
1.回到上一次操作的目录 cd - 2.rz打开上传文件 rz 3.下载某个文件 wget httpdownload 4.根据名字查找文件 find / -name mysql 5.通配符删除 rm ...