Scrapy 爬虫实例教程(一)---简介及资源列表

Scrapy(官网 http://scrapy.org/)是一款功能强大的,用户可定制的网络爬虫软件包。其官方描述称:"
Scrapy is a fast high-level screen scraping and web crawling framework, used to crawl websites and extract structured data from their pages. It can be used for a wide range of purposes, from data mining to monitoring and automated testing
"
Scrapy在github中有源码托管https://github.com/scrapy/scrapy,其安装可以参考github中提供的安装方法(大百度中也提供了很多安装方法的描述)。另外网站1和网站2提供了scrapy的使用方法和简单实例(小编后续随笔也会简单写一个scrapy实例,供大家参考)。
Scrapy的爬虫原理:
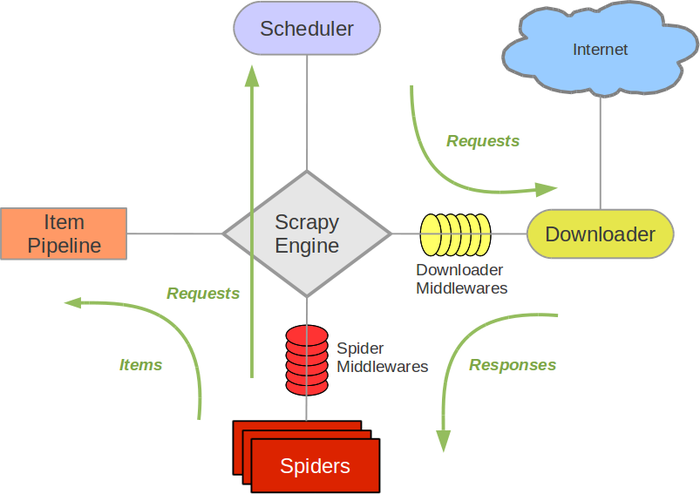
”盗用“的scrapy 官网中的scrapy核心框架图
Scrapy Engine是scrapy软件的核心,他负责各个组件的协调处理
Scheduler是调度器,负责爬去队列的管理,如Request的入队和出队管理
Item Pipeline 是抓取内容的核心组件,用户想要获取的内容可以写入item 然后再pipeline中设计数据的流向比如写入文件或是持久化到数据库中
Downloader 则是scrapy与web site接触的端口,负责根据Request 请求网页然后以response的形式返回用户处理接口(默认是 spider的parse函数)
Spider则是用户定制兴趣内容的模块,在scrapy的spiders中内置了BaseSpider,CSVFeedSpider,CrawlerSpider,用户可以根据情况选择合适spider继承与开发
Spider Middlewares则是Spider与Scrapy Engine 的中间层,用户可以个性化定义Spider向Engine传输过程
Scrpay的运行过程:
(1)Engine从Spider中获取一个需要爬取的URL(从spider中start_url获取),并以Request的形式在Scheduler中列队。
(2)Scheduler根据列队情况,把Request发送给Downloader,Downloader根据Request请求网页,并获取网页内容。
(3)网页内容以Response的形式经过Engine发送给Spider,并根据用户解析生成Item,发送给Pipeline。
(4)Pipeline根据获得的item和settings中的设置,处理item(process_item)把数据输出到文件或是数据库中。
上述过程反复进行,直到没有新的请求为止(此过程是一个异步处理过程)。
个人整理的Scrapy资源列表(望笑纳):
(1)scrapy中文教程
http://scrapy-chs.readthedocs.io/zh_CN/latest/intro/overview.html
(2)一个不错的scrapy学习博客
http://blog.csdn.net/column/details/younghz-scrapy.html
(3)scrapy 官方wiki
https://github.com/scrapy/scrapy/wiki
(4)scrapy实例
https://github.com/jackgitgz/CnblogsSpider
Scrapy 爬虫实例教程(一)---简介及资源列表的更多相关文章
- Scrapy爬虫实例教程(二)---数据存入MySQL
书接上回 实例教程(一) 本文将详细描述使用scrapy爬去左岸读书所有文章并存入本地MySql数据库中,文中所有操作都是建立在scrapy已经配置完毕,并且系统中已经安装了Mysql数据库(有权限操 ...
- scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250
scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250 前言 经过上一篇教程我们已经大致了解了Scrapy的基本情况,并写了一个简单的小demo.这次我会以爬取豆瓣电影TOP250为例进一步为大 ...
- scrapy爬虫框架教程(二)-- 爬取豆瓣电影
前言 经过上一篇教程我们已经大致了解了Scrapy的基本情况,并写了一个简单的小demo.这次我会以爬取豆瓣电影TOP250为例进一步为大家讲解一个完整爬虫的流程. 工具和环境 语言:python 2 ...
- 简单scrapy爬虫实例
简单scrapy爬虫实例 流程分析 抓取内容:网站课程 页面:https://edu.hellobi.com 数据:课程名.课程链接及学习人数 观察页面url变化规律以及页面源代码帮助我们获取所有数据 ...
- scrapy爬虫实例(1)
爬虫实例 对象 阳光问政平台 目标 : 主题,时间,内容 爬取思路 预先设置好items import scrapy class SuperspiderItem(scrapy.Item): title ...
- Scrapy爬虫实例——校花网
学习爬虫有一段时间了,今天使用Scrapy框架将校花网的图片爬取到本地.Scrapy爬虫框架相对于使用requests库进行网页的爬取,拥有更高的性能. Scrapy官方定义:Scrapy是用于抓取网 ...
- Scrapy爬虫框架教程(四)-- 抓取AJAX异步加载网页
欢迎关注博主主页,学习python视频资源,还有大量免费python经典文章 sklearn实战-乳腺癌细胞数据挖掘 https://study.163.com/course/introduction ...
- python scrapy 爬虫实例
1 创建一个项目 scrapy startproject basicbudejie 2 编写爬虫 import scrapy class Basicbudejie(scrapy.Spider): na ...
- scrapy爬虫框架处理流程简介
1.SPIDERS的yeild将request发送给ENGIN2.ENGINE对request不做任何处理发送给SCHEDULER3.SCHEDULER( url调度器),生成request交给ENG ...
随机推荐
- 我总结的常用sql语句
建表: Set sql_mode='strict_trans_tables': 存储引擎启用严格模式,非法数据值被拒绝 Create table t3(id int(4) primary key a ...
- LR11关联问题
LR11关联问题 最近,我在录制一份脚本在回放的时候报错,错误图如下: 很自然地我想到了关联,于是我再录制了一份脚本.我对比了一下ActionID=45322984确实是两个脚本不一样的地 ...
- 020 <one-to-one>、<many-to-one>单端关联上的lazy(懒加载)属性
<one-to-one>.<many-to-one>单端关联上,可以取值:false/proxy/noproxy(false/代理/不代理) 实例一:所有lazy属性默认(支持 ...
- Unity应用架构设计(10)————绕不开的协程和多线程(Part 1)
在进入本章主题之前,我们必须要了解客户端应用程序都是单线程模型,即只有一个主线程(Main Thread),或者叫做UI线程,即所有的UI控件的创建和操作都是在主线程上完成的.而服务器端应用程序,也就 ...
- 移动端页面 iPhone + Safari 页面调试 之 正确查看网络请求的姿势
如题 本文主要将 Safari + iPhone 前端开发调试 之 正确查看网络请求的 姿势 惯例 说下问题场景: 早知道safari(Mac) + iPhone 调试的方便 能解决很多日常调试问题 ...
- 谈一谈Java8的函数式编程 (三) --几道关于流的练习题
为什么要有练习题? 所谓学而不思则罔,思而不学则殆,在系列第一篇就表明我认为写博客,既是分享,也是自己的巩固,我深信"纸上得来终觉浅,绝知此事要躬行"的道理,因此之后的几篇博 ...
- docker安装-centos7
操作系统要求 要安装Docker,您需要64位版本的CentOS 7.步骤: 卸载旧版本 Docker的旧版本被称为docker或docker-engine . 如果这些已安装,请卸载它们以及关联 ...
- java 1.8 动态代理源码分析
JDK8动态代理源码分析 动态代理的基本使用就不详细介绍了: 例子: class proxyed implements pro{ @Override public void text() { Syst ...
- 【毕业设计】基于Android的家校互动平台开发(内含完整代码和所有文档)——爱吖校推(你关注的,我们才推)
☆ 写在前面 之前答应大家的毕业答辩之后把所有文档贡献出来,现在答辩已过,LZ信守承诺,把所有文档开源到了GitHub(这个地址包含所有的代码和文档以及PPT,外层为简单的代码).还望喜欢的朋友们,不 ...
- Spring学习(5)---Bean的定义及作用域的注解实现
Bean管理的注解实现 Classpath扫描与组件管理 类的自动检测与注册Bean <context:annotation-config/> @Component,@Repository ...