学习Spark——环境搭建(Mac版)
大数据情结
还记得上次跳槽期间,与很多猎头都有聊过,其中有一个猎头告诉我,整个IT跳槽都比较频繁,但是相对来说,做大数据的比较“懒”一些,不太愿意动。后来在一篇文中中也证实了这一观点,分析说大数据领域从业者普遍认为这是一个有前景,有潜力的方向,大多数希望有所积累,所以跳槽意愿不是很强烈。
14年的时候开始接触Hadoop,在Windows下搭了好几次环境,单机版、伪分布式和分布式都搭建过。那时候需要在Windows下装个虚拟机,在虚拟机中再装个Ubuntu,之后在Ubuntu上开始装jdk,hadoop等等,虽然麻烦了点,但是乐此不疲。一般环境搭建好了,再远程连接到Windows下的Eclipse然后开始把玩自带的10来个example,看着控制台齐刷刷的打印各种信息,那一刻,仿佛我已经深得大数据的要领。再到后来就是看看Hadoop的部分源码,因为功力不够,很多也是看的稀里糊涂的,现在残留在脑瓜子里的大概只有HDFS和MapReduce了。
转眼三年了,开始瞄上了Spark,与Hadoop的离线计算不同,Spark基于内存计算要比Hadoop更快,更高效。而且Spark是用Scala写的,这同样是一门简洁高效的语言,早在15年同事在研究Spark的时候就说过,Scala刚用的时候蹩手蹩脚,用习惯了,就爱不释手了。当然了,开发Spark也是支持Java和Python的。
环境搭建
想必之前搭建Hadoop环境的Windows系统的相对繁琐步骤,Mac下显得简单不少。
虽然我们需要搭建的是Sppark环境,但是因为Spark依赖了Hadoop的HDFS以及YARN计算框架,当然还有类似软件包管理软件。
安装前必备
操作系统:Mac OS X
JDK:1.8.0_121
命令终端:iTerm2(Mac自带的命令终端也一样,只是配置环境参数需要到~/.bash_profile下添加,对于iTerm2需要到~/.zshrc中添加)
软件包管理工具:brew(能够方便的安装和卸载软件,使用brew cash还可以安装图形化的软件,类似于Ubuntu下的apt-get以及前端里的npm)
安装Hadoop
上面步骤和条件如果都具备的话,就可以安装Hadoop了,这也是我唯一遇到坑的地方。
1. 配置ssh
配置ssh就是为了能够实现免密登录,这样方便远程管理Hadoop并无需登录密码在Hadoop集群上共享文件资源。
如果你的机子没有配置ssh的话,在命令终端输入ssh localhost是需要输入你的电脑登录密码的。配置好ssh后,就无需输入密码了。
第一步就是在终端执行ssh-keygen -t rsa,之后一路enter键,当然如果你之前已经执行过这样的语句,那过程中会提示是否要覆盖原有的key,输入y即可。
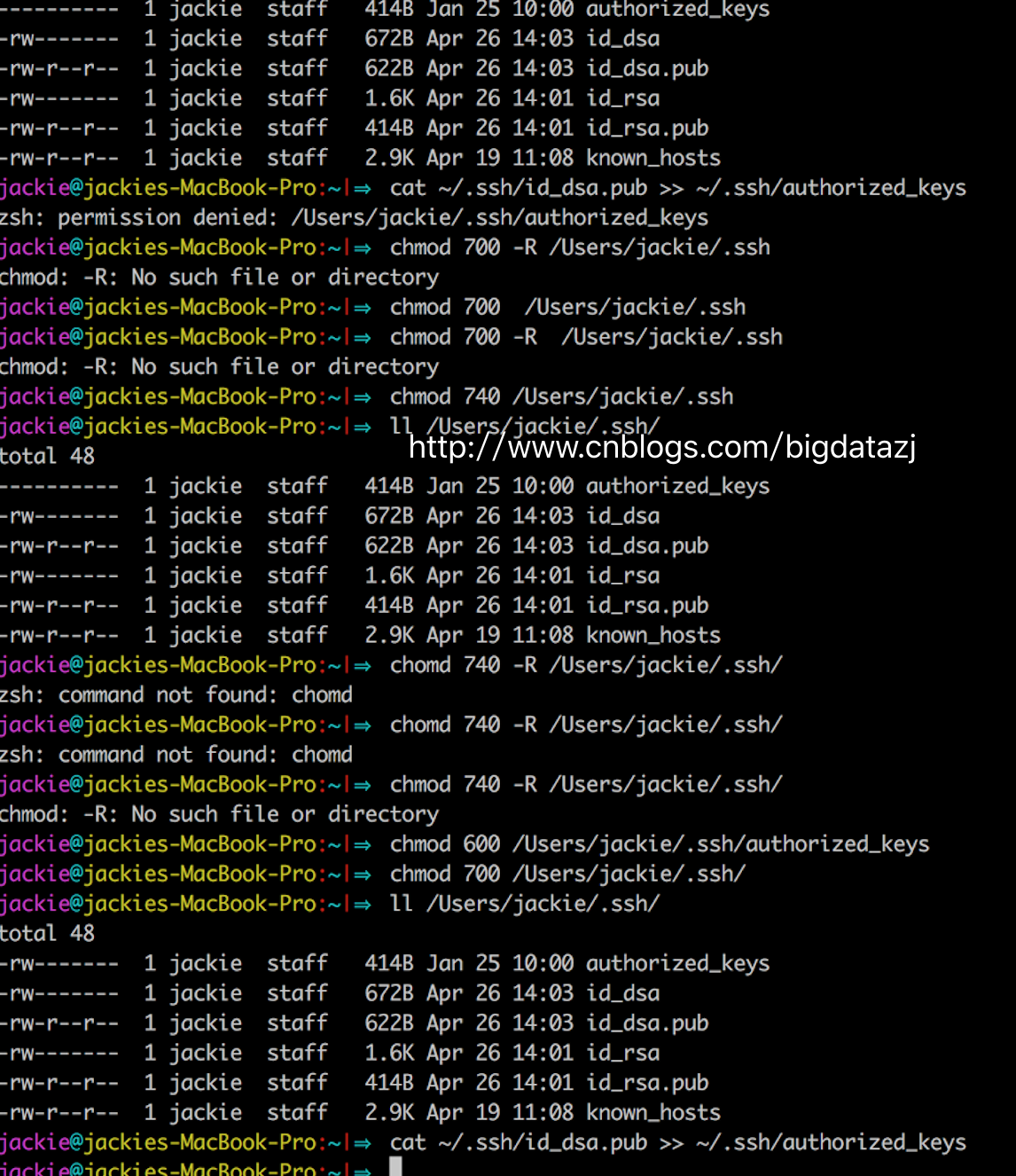
第二步执行语句cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys用于授权你的公钥到本地可以无需密码实现登录。
理论上这时候,你在终端输入ssh lcoalhost就能够免密登录了。
但是,我在这里遇到了个问题,折腾了我蛮久。当我执行cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys的时候,总是出现如下警告zsh: permission denied: /Users/jackie/.ssh/authorized_keys。
显然这是权限问题,我直接为ssh目录赋予777、740和700都无效,还是报同样的错。于是查了下资料在这里看到了解决方案。
设置authorized_keys权限——$ chmod 600 authorized_keys
设置.ssh目录权限——$ chmod 700 -R .ssh
参考资料给出的解释是:文件和目录的权限千万别设置成chmod 777.这个权限太大了,不安全,数字签名也不支持--!。
2. 下载安装Hadoop
这时候brew的好处就体现出来了,你无需到Hadoop官网去找下载链接,只要在命令终端输入brew install hadoop等命令执行完,你就可以看到在/usr/lcoal/Cellar目录下就有了hadoop目录,表示安装成功。(当然命令执行过程中会因为网络或其他原因中断,这时候你只需要重新执行一次brew install hadoop即可)
3. 配置Hadoop
3.1 进入安装目录/usr/local/Cellar/hadoop/2.8.0/libexec/etc/hadoop,找到并打开hadoop-env.sh文件,将
export HADOOP_OPTS="$HADOOP_OPTS -Djava.net.preferIPv4Stack=true"
改为
export HADOOP_OPTS="$HADOOP_OPTS -Djava.net.preferIPv4Stack=true -Djava.security.krb5.realm= -Djava.security.krb5.kdc="
export JAVA_HOME="/Library/Java/JavaVirtualMachines/jdk1.8.0_121.jdk/Contents/Home"
(java_home请写上你本机上jdk安装的位置)
3.2 配置hdfs地址和端口
进入目录/usr/local/Cellar/hadoop/2.8.0/libexec/etc/hadoop,打开core-site.xml将<configuration></configuration>替换为
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/Cellar/hadoop/hdfs/tmp</value>
<description>A base for other temporary directories.</description>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:8020</value>
</property>
</configuration>
3.3 配置mapreduce中jobtracker的地址和端口
在相同的目录下,你可以看到一个mapred-site.xml.template首先将文件重命名为mapred-site.xml,同样将<configuration></configuration>替换为
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>localhost:8021</value>
</property>
</configuration>
3.4 修改hdfs备份数
相同目录下,打开hdfs-site.xml加上
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
4. 格式化HDFS
这个操作相当于一个文件系统的初始化,执行命令hdfs namenode -format
在终端最终会显示成功
17/05/06 15:51:29 INFO namenode.FSImageFormatProtobuf: Saving image file /usr/local/Cellar/hadoop/hdfs/tmp/dfs/name/current/fsimage.ckpt_0000000000000000000 using no compression
17/05/06 15:51:29 INFO namenode.FSImageFormatProtobuf: Image file /usr/local/Cellar/hadoop/hdfs/tmp/dfs/name/current/fsimage.ckpt_0000000000000000000 of size 322 bytes saved in 0 seconds.
17/05/06 15:51:29 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
17/05/06 15:51:29 INFO util.ExitUtil: Exiting with status 0
17/05/06 15:51:29 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at jackies-macbook-pro.local/192.168.*.*
************************************************************/
5. 配置Hadoop环境变量
因为我用的是iTerm2,所以打开~/.zshrc添加
export HADOOP_HOME=/usr/local/Cellar/hadoop/2.8.0
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
再执行source ~/.zhsrac以确保配置生效
配置这个是方便在任意目录下全局开启关闭hadoop相关服务,而不需要到/usr/local/Cellar/hadoop/2.8.0/sbin下执行。
6. 启动关闭Hadoop服务
启动/关闭HDSF服务
./start-dfs.sh
./stop-dfs.sh
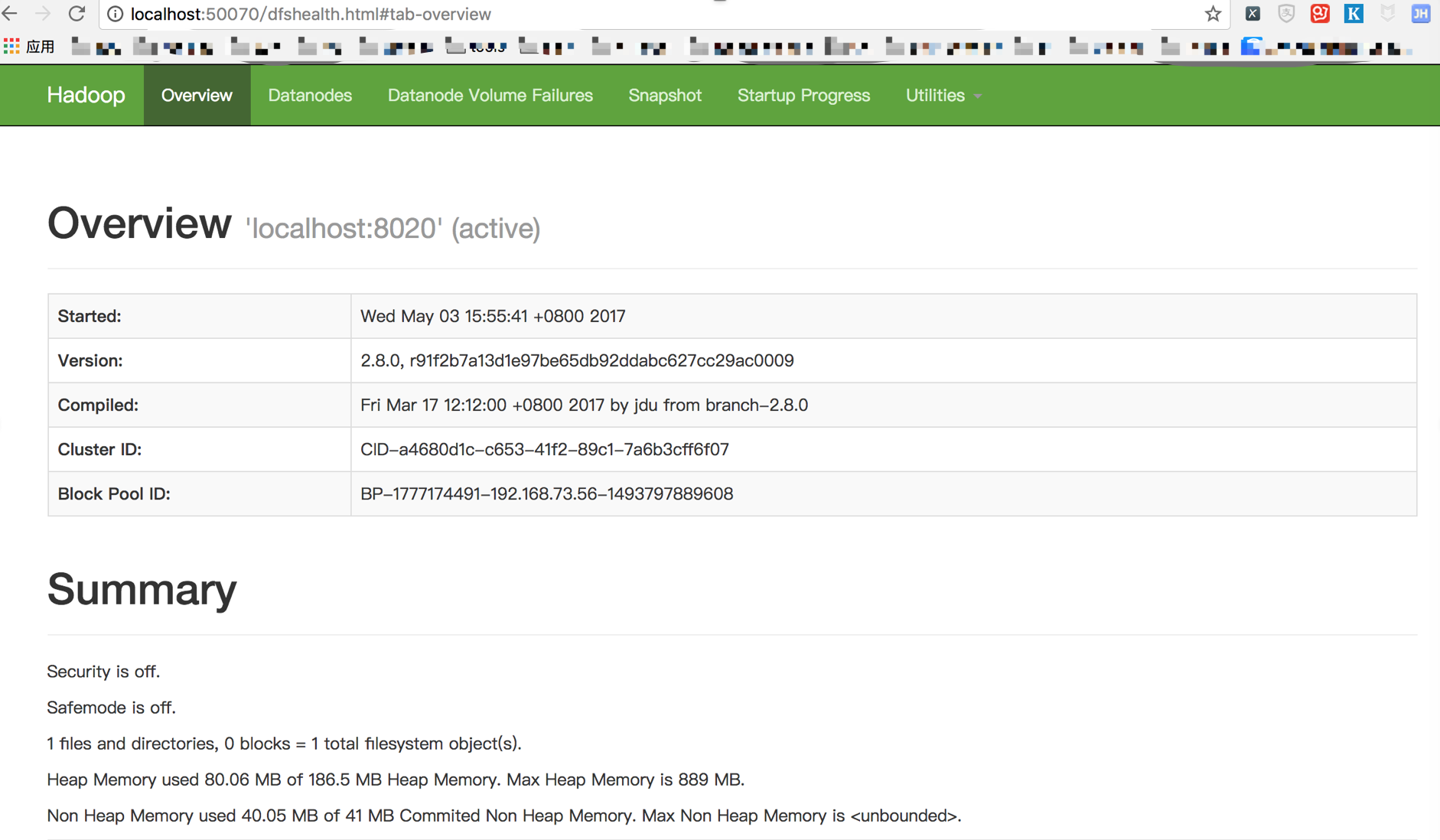
启动成功后,我们在浏览器中输入http://localhost:50070可以看到
启动/关闭YARN服务
./start-yarn.sh
./stop-yarn.sh
启动成功后,我们在浏览器中输入http://localhost:8088可以看到

启动/关闭Hadoop服务(等效上面两个)
./start-all.sh
./stop-all.sh
安装Scala
同样的配方,执行brew install scala你就可以拥有Scala。
在终端执行scala -version,如果出现类似Scala code runner version 2.12.2 -- Copyright 2002-2017, LAMP/EPFL and Lightbend, Inc.说明你安装成功了。
同样,不要忘了配置Scala的环境变量,打开~/.zshrc添加
export SCALA_HOME=/usr/local/Cellar/scala/2.12.2
export PATH=$PATH:$SCALA_HOME/bin
安装Spark
有了前面这么多的准备工作,终于可以安装Spark了。也是比较简单,起码我没有遇到坑。
到Spark官网下载你需要的Spark版本,注意这里我们看到需要有依赖的Hadoop,而且还让你选择Hadoop的版本。
下载完直接双击压缩包就会解压(建议安装一个解压软件),将其重命名为spark放到/usr/local下面。
毫无例外,我们还需要一个环境参数配置,打开~/.zshrc添加
export SPARK_HOME=/usr/local/spark
export PATH=$PATH:$SPARK_HOME/bin
走到这一步,我们终于可以启动spark了,打开终端,输入spark-shell,这时候会看到
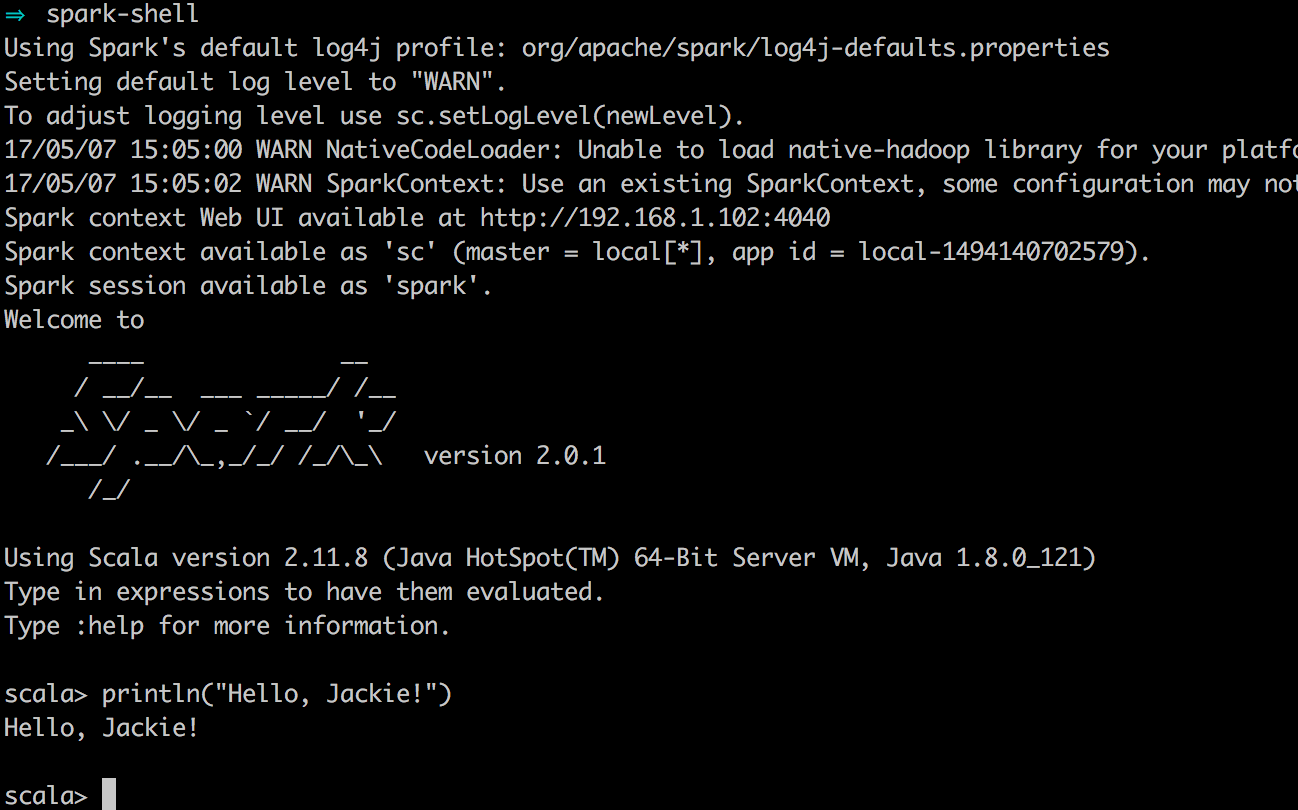
妥了!虽然整个安装过程没有遇到什么大坑,但是还是比较耗时间。
如果您觉得阅读本文对您有帮助,请点一下“推荐”按钮,您的“推荐”将是我最大的写作动力!如果您想持续关注我的文章,请扫描二维码,关注JackieZheng的微信公众号,我会将我的文章推送给您,并和您一起分享我日常阅读过的优质文章。

学习Spark——环境搭建(Mac版)的更多相关文章
- vue开发环境搭建Mac版
一.前言 要做一个移动端app,面对webapp最流行的三个技术React,angular,vue,三选一,如何选,可参考blog移动app技术选型,react,angular, vue, 下面是对 ...
- quick-cocos2d-x 系列之——环境搭建(Mac版)
quick-cocos2d-x简单介绍 何为quick-cocos2d-x? ? 简单一句话:quick-cocos2d-x是採用lua语言,通过tolua++工具对cocos2d-x进一步封装, ...
- 最详细的JavaWeb开发基础之java环境搭建(Mac版)
阅读文本大概需要 5 分钟. 我之前分享过在 Windows 下面配置 Java 环境,这次给大家带来的是 Mac 下面安装配置 Java 环境.首先 Mac 系统已经带有默认的 Java,但是由于使 ...
- Spark学习进度-Spark环境搭建&Spark shell
Spark环境搭建 下载包 所需Spark包:我选择的是2.2.0的对应Hadoop2.7版本的,下载地址:https://archive.apache.org/dist/spark/spark-2. ...
- 人工智能之深度学习-初始环境搭建(安装Anaconda3和TensorFlow2步骤详解)
前言: 本篇文章主要讲解的是在学习人工智能之深度学习时所学到的知识和需要的环境配置(安装Anaconda3和TensorFlow2步骤详解),以及个人的心得体会,汇集成本篇文章,作为自己深度学习的总结 ...
- hive_学习_01_hive环境搭建(单机)
一.前言 本文承接上一篇:hbase_学习_01_HBase环境搭建(单机),主要是搭建 hive 的单机环境 二.环境准备 1.说明 hive 的下载来源有: 官方版本:http://archive ...
- Hive On Spark环境搭建
Spark源码编译与环境搭建 Note that you must have a version of Spark which does not include the Hive jars; Spar ...
- (一)Hololens Unity 开发环境搭建(Mac BOOTCAMP WIN10)
(一)Hololens Unity 开发环境搭建(Mac BOOTCAMP WIN10) 系统要求 64位 Windows 10 除了家庭版的 都支持 ~ 64位CPU CPU至少是四核心以上~ 至少 ...
- Python之Django环境搭建(MAC+pycharm+Django++postgreSQL)
Python之Django环境搭建(MAC+pycharm+Django++postgreSQL) 转载请注明地址:http://www.cnblogs.com/funnyzpc/p/7828614. ...
随机推荐
- java中 "==" 和 ".equels"的区别
起初接触java的时候这个问题还是比较迷茫的,最近上班之余刷博客的时候看了一些大神写的文章,自己也来总结一下,直接贴代码: package string; public class demo1 { p ...
- WebX框架学习笔记之二----框架搭建及请求的发起和处理
框架搭建 执行环境:windows.maven 执行步骤: 1.新建一个目录,例如:D:\workspace.注意在盘符目录下是无法执行成功的. 2.执行如下命令: mvn archetype:gen ...
- JavaScript复习之--javascript数据类型隐式转换
JavaScript数据类型隐式转换.一,函数类 isNaN() 该函数会对参数进行隐式的Number()转换,如果转换不成功则返回true. alert() 输出的内容隐式的 ...
- 老李分享:adb发送的指令都有哪些
老李分享:adb发送的指令都有哪些 这两天在poptest上课的时候,我们邀请了业内技术牛人为我们的学员讲解手机自动化方面的知识,每天大家都很踊跃,要学习到晚上11点多才能,有的学员跟我说都累傻了 ...
- 大数据测试之hadoop系统生态
poptest是国内唯一一家培养测试开发工程师的培训机构,以学员能胜任自动化测试,性能测试,测试工具开发等工作为目标,也是国内最早探索大数据测试培训的机构,开发了独有的课程体系.如果对课程感兴趣,请大 ...
- dotnet Core 调用HTTP接口,系统大量CLOSE_WAIT连接问题的分析,尚未解决。
环境: dotnet core 1.0.1 CentOS 7.2 今天在服务器巡检的时候,发现一个服务大量抛出异常 异常信息为: LockStatusPushError&&Messag ...
- (iOS)开发中收集的小方法
1.颜色转变成图片 - (UIImage *)createImageWithColor:(UIColor *)color { CGRect rect = CGRectMake(0.0f, 0. ...
- js根据条件json生成随机json:randomjson
前端开发中,在做前后端分离的时候,经常需要手写json数据,有3个问题特别揪心: 1,数据是写死的,不能按一定的条件随机生成长度不一,内容不一的数据 2,写数组的时候,如果有很多条,需要一条一条地写, ...
- 使用SQL存储过程有什么好处 用视图有什么好处
随便胡乱说几点,大家补充一下.1.预编译,已优化,效率较高.避免了SQL语句在网络中传输然后再解释的低效率.2.如果公司有专门的DBA,写存储过程可以他来做,程序员只要按他提供的接口调用就好了.这样分 ...
- MySQL存储过程--带参数报错1064
DELIMITER $$ USE `student`$$ DROP PROCEDURE IF EXISTS `sync_student`$$ CREATE DEFINER=`student`@`%` ...