Python实现多线程HTTP下载器
本文将介绍使用Python编写多线程HTTP下载器,并生成.exe可执行文件。
环境:windows/Linux + Python2.7.x
单线程
在介绍多线程之前首先介绍单线程。编写单线程的思路为:
- 解析url;
- 连接web服务器;
- 构造http请求包;
- 下载文件。
接下来通过代码进行说明。
解析url
通过用户输入url进行解析。如果解析的路径为空,则赋值为'/';如果端口号为空,则赋值为"80”;下载文件的文件名可根据用户的意愿进行更改(输入'y'表示更改,输入其它表示不需要更改)。
下面列出几个解析函数:
#解析host和path
def analyHostAndPath(totalUrl):
protocol,s1 = urllib.splittype(totalUrl)
host, path = urllib.splithost(s1)
if path == '':
path = '/'
return host, path
#解析port
def analysisPort(host):
host, port = urllib.splitport(host)
if port is None:
return 80
return port
#解析filename
def analysisFilename(path):
filename = path.split('/')[-1]
if '.' not in filename:
return None
return filename
连接web服务器
使用socket模块,根据解析url得到的host和port连接web服务器,代码如下:
import socket from analysisUrl import port,host ip = socket.gethostbyname(host) s = socket.socket(socket.AF_INET,socket.SOCK_STREAM) s.connect((ip, port)) print "success connected webServer!!"
构造http请求包
根据解析url得到的path, host, port构造一个HTTP请求包。
from analysisUrl import path, host, port packet = 'GET ' + path + ' HTTP/1.1\r\nHost: ' + host + '\r\n\r\n'
下载文件
根据构造的http请求包,向服务器发送文件,抓取响应报文头部的"Content-Length"。
def getLength(self):
s.send(packet)
print "send success!"
buf = s.recv(1024)
print buf
p = re.compile(r'Content-Length: (\d*)')
length = int(p.findall(buf)[0])
return length, buf
下载文件并计算下载所用的时间。
def download(self):
file = open(self.filename,'wb')
length,buf = self.getLength()
packetIndex = buf.index('\r\n\r\n')
buf = buf[packetIndex+4:]
file.write(buf)
sum = len(buf)
while 1:
buf = s.recv(1024)
file.write(buf)
sum = sum + len(buf)
if sum >= length:
break
print "Success!!"
if __name__ == "__main__":
start = time.time()
down = downloader()
down.download()
end = time.time()
print "The time spent on this program is %f s"%(end - start)
运行结果示意图:
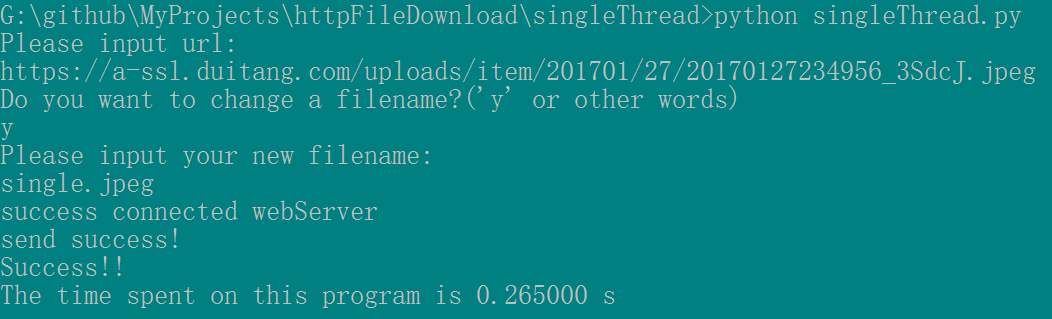
多线程
抓取响应报文头部的"Content-Length"字段,结合线程个数,加锁分段下载。与单线程的不同,这里将所有代码整合为一个文件,代码中使用更多的Python自带模块。
得到"Content-Length":
def getLength(self):
opener = urllib2.build_opener()
req = opener.open(self.url)
meta = req.info()
length = int(meta.getheaders("Content-Length")[0])
return length
根据得到的Length,结合线程个数划分范围:
def get_range(self):
ranges = []
length = self.getLength()
offset = int(int(length) / self.threadNum)
for i in range(self.threadNum):
if i == (self.threadNum - 1):
ranges.append((i*offset,''))
else:
ranges.append((i*offset,(i+1)*offset))
return ranges
实现多线程下载,在向文件写入内容时,向线程加锁,并使用with lock代替lock.acquire( )...lock.release( );使用file.seek( )设置文件偏移地址,保证写入文件的准确性。
def downloadThread(self,start,end):
req = urllib2.Request(self.url)
req.headers['Range'] = 'bytes=%s-%s' % (start, end)
f = urllib2.urlopen(req)
offset = start
buffer = 1024
while 1:
block = f.read(buffer)
if not block:
break
with lock:
self.file.seek(offset)
self.file.write(block)
offset = offset + len(block)
def download(self):
filename = self.getFilename()
self.file = open(filename, 'wb')
thread_list = []
n = 1
for ran in self.get_range():
start, end = ran
print 'starting:%d thread '% n
n += 1
thread = threading.Thread(target=self.downloadThread,args=(start,end))
thread.start()
thread_list.append(thread)
for i in thread_list:
i.join()
print 'Download %s Success!'%(self.file)
self.file.close()
运行结果:
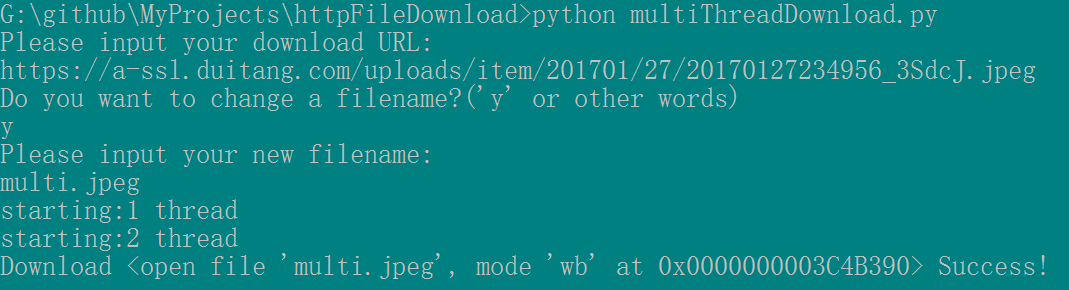
将(*.py)文件转化为(*.exe)可执行文件
当写好了一个工具,如何让那些没有安装Python的人使用这个工具呢?这就需要将.py文件转化为.exe文件。
这里用到Python的py2exe模块,初次使用,所以对其进行介绍:
py2exe是一个将Python脚本转换成windows上可独立执行的可执行文件(*.exe)的工具,这样,就可以不用装Python在windows上运行这个可执行程序。可在下载地址中下载对应的版本。
接下来,在multiThreadDownload.py的同目录下,创建mysetup.py文件,编写:
from distutils.core import setup import py2exe setup(console=["multiThreadDownload.py"])
接着执行命令:Python mysetup.py py2exe
生成dist文件夹,multiTjhreadDownload.exe文件位于其中,点击运行即可。
上面就是我使用Python实现多线程HTTP下载器的过程,各位有什么好的想法意见,还望不吝赐教!
该项目的链接:https://github.com/Yabea/HttpFileDownload
我的github:https://github.com/Yabea
Python实现多线程HTTP下载器的更多相关文章
- 用 python 实现一个多线程网页下载器
今天上来分享一下昨天实现的一个多线程网页下载器. 这是一个有着真实需求的实现,我的用途是拿它来通过 HTTP 方式向服务器提交游戏数据.把它放上来也是想大家帮忙挑刺,找找 bug,让它工作得更好. k ...
- python多进程断点续传分片下载器
python多进程断点续传分片下载器 标签:python 下载器 多进程 因为爬虫要用到下载器,但是直接用urllib下载很慢,所以找了很久终于找到一个让我欣喜的下载器.他能够断点续传分片下载,极大提 ...
- Android开发多线程断点续传下载器
使用多线程断点续传下载器在下载的时候多个线程并发可以占用服务器端更多资源,从而加快下载速度,在下载过程中记录每个线程已拷贝数据的数量,如果下载中断,比如无信号断线.电量不足等情况下,这就需要使用到断点 ...
- Java多线程的下载器(1)
实现了一个基于Java多线程的下载器,可提供的功能有: 1. 对文件使用多线程下载,并显示每时刻的下载速度. 2. 对多个下载进行管理,包括线程调度,内存管理等. 一:单个文件下载的管理 1. 单文件 ...
- 我的Android进阶之旅------>Android基于HTTP协议的多线程断点下载器的实现
一.首先写这篇文章之前,要了解实现该Android多线程断点下载器的几个知识点 1.多线程下载的原理,如下图所示 注意:由于Android移动设备和PC机的处理器还是不能相比,所以开辟的子线程建议不要 ...
- 用python做youtube自动化下载器 代码
目录 项目地址 思路 流程 1. post i. 先把post中的headers格式化 ii.然后把参数也格式化 iii. 最后再执行requests库的post请求 iv. 封装成一个函数 2. 调 ...
- python的内置下载器
python有个内置下载器,有时候在内部提供文件下载很好用. 进入提供下载的目录 # ls abc.aaa chpw.py finance.py lsdir.py ping.py u2d-partia ...
- Qt+Python开发百度图片下载器
一.资源下载地址 https://www.aliyundrive.com/s/jBU2wBS8poH 本项目路径:项目->收费->百度图片下载器(可试用5分钟) 安装包直接下载地址:htt ...
- 实现android支持多线程断点续传下载器功能
多线程断点下载流程图: 多线程断点续传下载原理介绍: 在下载的时候多个线程并发可以占用服务器端更多资源,从而加快下载速度手机端下载数据时难免会出现无信号断线.电量不足等情况,所以需要断点续传功能根据下 ...
随机推荐
- 结对编程--Goldpoint Game
黄金点游戏 黄金点游戏描述: N个同学(N通常大于10),每人写一个0~100之间的有理数 (不包括0或100),交给裁判,裁判算出所有数字的平均值,然后乘以0.618(所谓黄金分割常数),得到G值. ...
- Python字符串的encode与decode研究心得——解决乱码问题
转~Python字符串的encode与decode研究心得——解决乱码问题 为什么Python使用过程中会出现各式各样的乱码问题,明明是中文字符却显示成“/xe4/xb8/xad/xe6/x96/x8 ...
- MySQL协议分析2
MySQL协议分析 议程 协议头 协议类型 网络协议相关函数 NET缓冲 VIO缓冲 MySQL API 协议头 ● 数据变成在网络里传输的数据,需要额外的在头部添加4 个字节的包头. . packe ...
- Servlet中的过滤器Filter用法
1.过滤器的概念 Java中的Filter 并不是一个标准的Servlet ,它不能处理用户请求,也不能对客户端生成响应. 主要用于对HttpServletRequest 进行预处理,也可以对Http ...
- iOS中UITextField 使用全面解析 分类: ios技术 2015-04-10 14:37 153人阅读 评论(0) 收藏
//初始化textfield并设置位置及大小 UITextField *text = [[UITextField alloc]initWithFrame:CGRectMake(20, 20, 13 ...
- 分布式事务 & 两阶段提交 & 三阶段提交
可以参考这篇文章: http://blog.csdn.net/whycold/article/details/47702133 两阶段提交保证了分布式事务的原子性,这些子事务要么都做,要么都不做. 而 ...
- 【转】安卓布局:layout_weight的理解
android:layout_weight详细分析介绍: 布局文件是:<?xml version="1.0" encoding="utf-8"?>& ...
- CentOS标准目录结构
原博:http://www.centoscn.com/CentOS/2014/0424/2861.html/ 最高层root --- 启动Linux时使用的一些核心文件.如操作系统内核.引导程序Gru ...
- CodeForces 755C PolandBall and Forest (并查集)
题意:给定每一点离他最远的点,问是这个森林里有多少棵树. 析:并查集,最后统计不同根结点的数目即可. 代码如下: #pragma comment(linker, "/STACK:102400 ...
- 笔记整理--玩转robots协议
玩转robots协议 -- 其他 -- IT技术博客大学习 -- 共学习 共进步! - Google Chrome (2013/7/14 20:24:07) 玩转robots协议 2013年2月8日北 ...