Qt+Python开发百度图片下载器
一、资源下载地址
https://www.aliyundrive.com/s/jBU2wBS8poH
本项目路径:项目->收费->百度图片下载器(可试用5分钟)
安装包直接下载地址:http://139.9.165.1/media/BaiduPicDown.exe
二、项目介绍
1、本项目使用Vs2019+Qt库+Python库来开发一个百度图片播放下载器(支持Gif)。
Qt播放Gif图片参考文章:
https://www.cnblogs.com/liangqin/p/15161809.html
本文主要描述Qt调用Python库来获取百度图片。
2、本项目完成的功能如下:
(1)、支持通过搜索关键词及图片张数来获取百度图片进行循环播放及保存原文件。
(2)、支持设置播放图片窗口大小。
(3)、支持Gif图片。
3、效果展示:
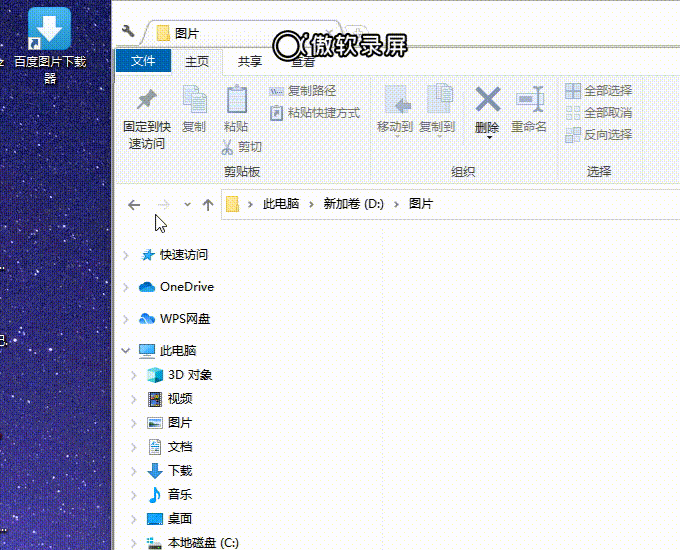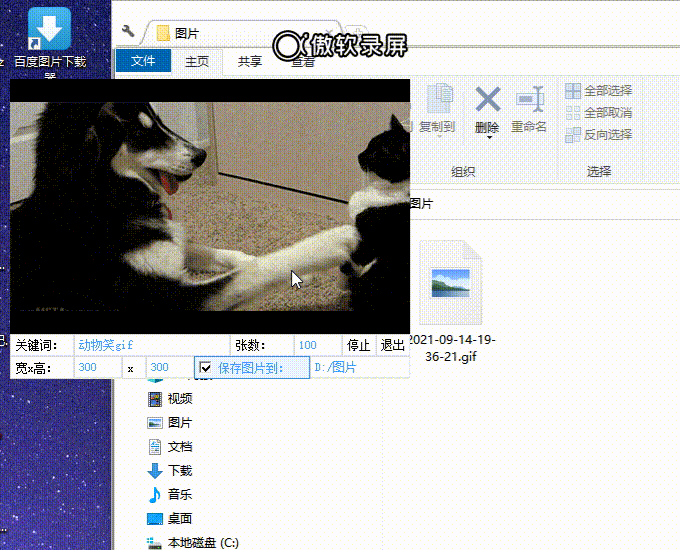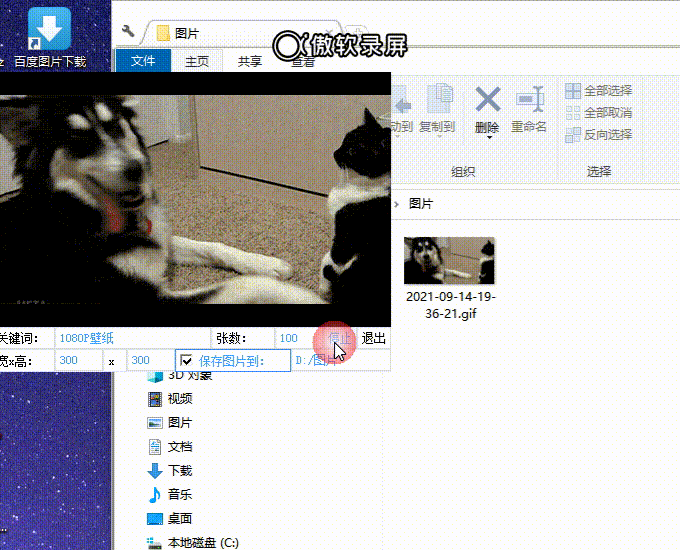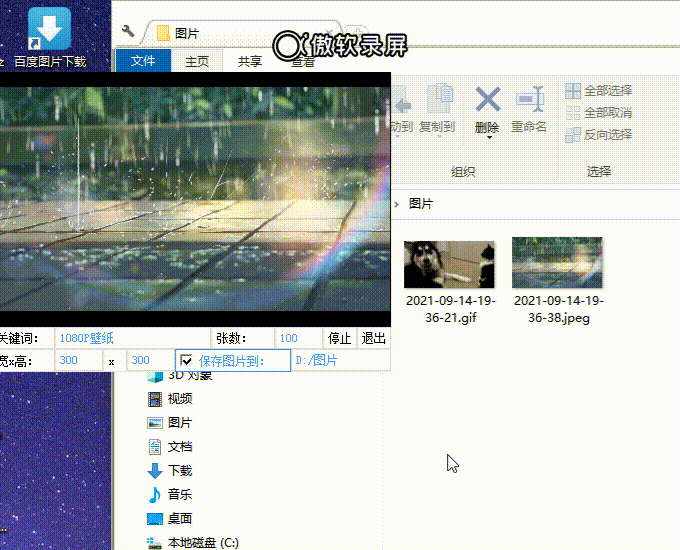
三、项目开始
1、准备工作
搭建一份Qt播放Gif图片的工程环境。然后获取python对应平台的头文件及库:
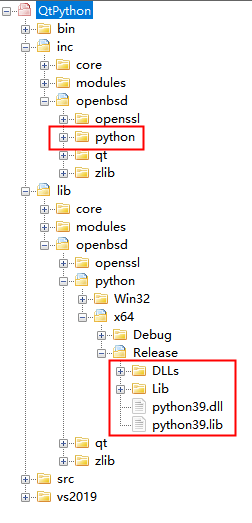
注意:安装的python的Lib目录下有很多文件,整个目录比较大,不便于我们程序发布。我们只需要保留程序所需要的文件即可,找到本程序的安装路径即可看到基本所需的Lib文件。
2、写python程序来爬取百度图片
这里参考文章:
https://blog.csdn.net/xiligey1/article/details/73321152
然后进行简单修改,提供一个getImgUrls(key,num)接口给C++调用获取当前关键词多少张urls,提供一个getImg()接口给C++调用循环获取爬取到的图片,该接口返回给C++的是图片的base64编码。
修改后的内容如下:
baidu_photo_spider.py:
1 """根据搜索词下载百度图片"""
2 import os
3 import re
4 import base64
5 import time
6 from typing import List, Tuple
7 from urllib.parse import quote
8
9 import requests
10
11 from conf import *
12
13 # 关键词, 改为你想输入的词即可, 相当于在百度图片里搜索一样
14 keyword = '治愈系柴犬'
15
16 # 最大下载数量
17 max_download_images = 100
18
19 all_pic_urls = []
20 count = 0
21
22 def get_page_urls(page_url: str, headers: dict) -> Tuple[List[str], str]:
23 """获取当前翻页的所有图片的链接
24 Args:
25 page_url: 当前翻页的链接
26 headers: 请求表头
27 Returns:
28 当前翻页下的所有图片的链接, 当前翻页的下一翻页的链接
29 """
30 if not page_url:
31 return [], ''
32 try:
33 html = requests.get(page_url, headers=headers)
34 html.encoding = 'utf-8'
35 html = html.text
36 except IOError as e:
37 print(e)
38 return [], ''
39 pic_urls = re.findall('"objURL":"(.*?)",', html, re.S)
40 next_page_url = re.findall(re.compile(r'<a href="(.*)" class="n">下一页</a>'), html, flags=0)
41 next_page_url = 'http://image.baidu.com' + next_page_url[0] if next_page_url else ''
42 return pic_urls, next_page_url
43
44 def getImgUrls(key,num):
45 global keyword
46 global max_download_images
47 global all_pic_urls
48 keyword = key
49 max_download_images = num
50 url_init = url_init_first + quote(keyword, safe='/')
51 page_urls, next_page_url = get_page_urls(url_init, headers)
52 all_pic_urls.extend(page_urls)
53 page_count = 0
54 while 1:
55 page_urls, next_page_url = get_page_urls(next_page_url, headers)
56 page_count += 1
57 print('正在获取第%s个翻页的所有图片链接' % str(page_count))
58 if next_page_url == '' and page_urls == []:
59 print('已到最后一页,共计%s个翻页' % page_count)
60 return
61 all_pic_urls.extend(page_urls)
62 if len(all_pic_urls) >= max_download_images:
63 print('已达到设置的最大下载数量%s' % max_download_images)
64 return
65
66 def down_pic(i,pic_url):
67 try:
68 pic = requests.get(pic_url, timeout=15)
69 image_output_path = './images/' + str(i + 1) + '.jpg'
70 with open(image_output_path, 'wb') as f:
71 f.write(pic.content)
72 print('成功下载第%s张图片: %s' % (str(i + 1), str(pic_url)))
73 except IOError as e:
74 print('下载第%s张图片时失败: %s' % (str(i + 1), str(pic_url)))
75 print(e)
76 return
77
78 def getImg():
79 global all_pic_urls
80 global count
81 global max_download_images
82 none='none'
83 try:
84 pic = requests.get(list(set(all_pic_urls))[count], timeout=15)
85 imgbase64 = base64.b64encode(pic.content).decode()
86 #print(count)
87 count += 1
88 if count == max_download_images:
89 count = 0
90 return imgbase64,none
91 except IOError as e:
92 print(e)
93 return none,none
94
95 if __name__ == '__main__':
96 if not os.path.exists('./images'):
97 os.mkdir('./images')
98
99 getImgUrls('猫', 2)
100
101 #下载图片
102 for i, pic_url in enumerate(list(set(all_pic_urls))[:max_download_images]):
103 down_pic(i, pic_url)
104
105 #循环读取列表中的图片
106 while 1:
107 print(getImg())
108 time.sleep(5)
3、封装C++调用python库的接口
直接上代码:
1 #include "PythonDevApi.h"
2 #include "Python.h"
3
4 void initPython()
5 {
6 Py_Initialize();//加载Python解释器
7 PyRun_SimpleString("import sys");
8 PyRun_SimpleString("sys.path.append('Dlls/')");
9 }
10
11 void unInitPython()
12 {
13 Py_Finalize();//卸载Python解释器
14 }
15
16 static PyObject* pBaiduModule = NULL;
17
18 int pyGetBaiduImgInit(const char* key, int num)
19 {
20 pBaiduModule = PyImport_ImportModule("baidu_photo_spider");//Python py文件名
21 PyImport_ReloadModule(pBaiduModule);
22 if (pBaiduModule == nullptr)
23 return -1;
24
25 PyObject* pFunc = NULL;
26 PyObject* pArgs = NULL;
27 PyObject* pResult = NULL;
28 pFunc = PyObject_GetAttrString(pBaiduModule, "getImgUrls");//py文件内函数名
29 //执行函数
30 pArgs = Py_BuildValue("si", key, num);
31 pResult = PyObject_CallObject(pFunc, pArgs);
32
33 return 0;
34 }
35
36 int pyGetBaiduImgWork(char* img, int imgSize)
37 {
38 //执行函数
39 PyObject* pBaiduFunc = PyObject_GetAttrString(pBaiduModule, "getImg");//py文件内函数名
40 if (pBaiduFunc == NULL)
41 return -1;
42
43 PyObject* pArgs = NULL;
44 PyObject* pResult = PyObject_CallObject(pBaiduFunc, pArgs);
45 if (pResult == NULL)
46 return -1;
47
48 char* imgbase64, * none;
49 int ret = PyArg_ParseTuple(pResult, "s|s", &imgbase64, &none);
50 if (ret == 1)
51 {
52 if (memcmp(imgbase64, none, strlen(none)) != 0 && img != NULL && strlen(imgbase64) < imgSize)
53 {
54 memcpy(img, imgbase64, strlen(imgbase64));
55 return 0;
56 }
57 }
58 else
59 {
60 printf("ret:%d\n", ret);
61 }
62
63 return -1;
64 }
65
66 int pyGetBaiduImgUninit()
67 {
68 return 0;
69 }
4、调用封装好的python接口来进行图片获取与保存文件:
1 void GuiQtDevThread::run()
2 {
3 int count = 0;
4
5 pyGetBaiduImgInit(m_key.toStdString().c_str(), m_num);
6
7 while (1)
8 {
9 //程序退出时终止线程
10 if (m_gui->getGetImgThreadState() == THREAD_STATE_E_PrepareStop)
11 {
12 m_gui->setGetImgThreadState(THREAD_STATE_E_Stop);
13 pyGetBaiduImgUninit();
14 return ;
15 }
16 count++;
17 if (count == 50)
18 {
19 count = 0;
20 //只能使用emit方式操作控件,直接操作控件会死机,这里会等待槽函数结束才继续运行(Qt::BlockingQueuedConnection)
21 memset(m_img, 0, m_img_size);
22 int ret = pyGetBaiduImgWork(m_img, m_img_size);
23 if (ret != 0)
24 {
25 QThread::msleep(100);
26 continue;
27 }
28
29 QByteArray decodeimg = QByteArray::fromBase64(m_img);
30
31 CQVString filenamet;
32 filenamet.Append("%s%d", "imgtmp", _getpid());
33 QFile file(filenamet.GetBuffer());
34 file.open(QIODevice::WriteOnly);
35 file.write(decodeimg);
36 file.close();
37 QThread::msleep(50);
38
39 QString saveFileName = m_gui->getSaveDir();
40 if (saveFileName.length() > 1)
41 {
42 bool dirExist = true;
43 QDir dir;
44 if (!dir.exists(saveFileName))
45 {
46 dirExist = dir.mkdir(saveFileName);
47 }
48
49 if (dirExist)
50 {
51 CQVString filenamet;
52 filenamet.Append("%s%d", "imgtmp", _getpid());
53 QImageReader reader(filenamet.GetBuffer());
54 reader.setDecideFormatFromContent(true);
55 int nCount = reader.imageCount();
56 if (nCount > 0 && reader.canRead())
57 {
58 QString fileFomate(QImageReader::imageFormat(filenamet.GetBuffer()));
59
60 saveFileName += "/";
61 QDateTime current_date_time = QDateTime::currentDateTime();
62 QString current_date = current_date_time.toString("yyyy-MM-dd-hh-mm-ss");
63 saveFileName += current_date;
64 saveFileName += ".";
65 saveFileName += fileFomate;
66 QFile saveFile(saveFileName);
67 saveFile.open(QIODevice::WriteOnly);
68 saveFile.write(decodeimg);
69 saveFile.close();
70 QThread::msleep(50);
71
72 }
73 }
74 }
75
76 m_gui->setFileChange();
77 }
78 QThread::msleep(100);
79 }
80 }
5、项目生成后事件需要把python的dll拷贝到exe目录下,并且把python的DLLs和Lib目录以及我们写的py程序拷贝到主工程和exe目录下。这样才能保证vs2019和双击exe正常运行程序,如图:
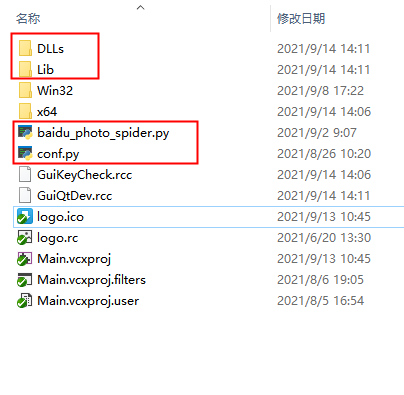
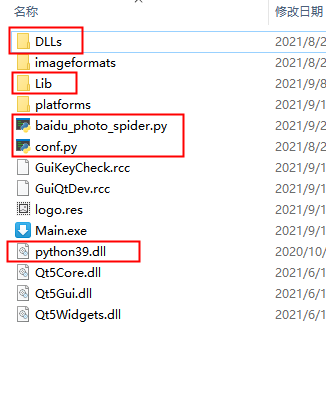
Qt+Python开发百度图片下载器的更多相关文章
- Python实战:美女图片下载器,海量图片任你下载
Python应用现在如火如荼,应用范围很广.因其效率高开发迅速的优势,快速进入编程语言排行榜前几名.本系列文章致力于可以全面系统的介绍Python语言开发知识和相关知识总结.希望大家能够快速入门并学习 ...
- 第三百四十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—编写spiders爬虫文件循环抓取内容—meta属性返回指定值给回调函数—Scrapy内置图片下载器
第三百四十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—编写spiders爬虫文件循环抓取内容—meta属性返回指定值给回调函数—Scrapy内置图片下载器 编写spiders爬虫文件循环 ...
- Bing图片下载器(Python实现)
分享一个Python实现的Bing图片下载器.下载首页图片并保存到到当前目录.其中用到了正则库re以及Request库. 大致流程如下: 1.Request抓取首页数据 2.re正则匹配首页图片URL ...
- 二十 Python分布式爬虫打造搜索引擎Scrapy精讲—编写spiders爬虫文件循环抓取内容—meta属性返回指定值给回调函数—Scrapy内置图片下载器
编写spiders爬虫文件循环抓取内容 Request()方法,将指定的url地址添加到下载器下载页面,两个必须参数, 参数: url='url' callback=页面处理函数 使用时需要yield ...
- QT--HTTP图片下载器
QT--HTTP图片下载器 1.http使用前提 QT += core gui network //必须加上network 2.必须头文件 #include <QNetwork ...
- 用python做youtube自动化下载器 代码
目录 项目地址 思路 流程 1. post i. 先把post中的headers格式化 ii.然后把参数也格式化 iii. 最后再执行requests库的post请求 iv. 封装成一个函数 2. 调 ...
- .NET破解之图片下载器
自去年五月加入吾爱后,学习了三个月,对逆向破解产生了深厚的兴趣,尤其是对.NET方面的分析:但由于这一年,项目比较忙,事情比较多,破解这方面又停滞了许久,不知道还要好久. 前些天,帮忙批量下载QQ相册 ...
- python多进程断点续传分片下载器
python多进程断点续传分片下载器 标签:python 下载器 多进程 因为爬虫要用到下载器,但是直接用urllib下载很慢,所以找了很久终于找到一个让我欣喜的下载器.他能够断点续传分片下载,极大提 ...
- Python实现多线程HTTP下载器
本文将介绍使用Python编写多线程HTTP下载器,并生成.exe可执行文件. 环境:windows/Linux + Python2.7.x 单线程 在介绍多线程之前首先介绍单线程.编写单线程的思路为 ...
随机推荐
- 中高级Android大厂面试秘籍,为你保驾护航金三银四,直通大厂(上)
前言 当下,正面临着近几年来的最严重的互联网寒冬,听得最多的一句话便是:相见于江湖~.缩减HC.裁员不绝于耳,大家都是人心惶惶,年前如此,年后想必肯定又是一场更为惨烈的江湖厮杀.但博主始终相信,寒冬之 ...
- Android:Camera2的简单使用
以前用的是Camera,但是现在Camera已经被官方弃用了,所以这里使用的是Camera2进行演示 使用Camera需要注意的就是权限的获取,必须有权限 类图介绍 Camera2跟Camera1不一 ...
- 【javaFX学习】(三) 控件手册
移至http://blog.csdn.net/qq_37837828/article/details/78732605 更新 这里写的控件可能不是所有的控件,但是应该是比较齐全并足够用的了,后面还有图 ...
- 《Python Cookbook v3.0.0》Chapter2 字符串、文本
感谢: https://github.com/yidao620c/python3-cookbook 如有侵权,请联系我整改. 本文章节会严格按照原书(以便和原书对照,章节标题可能会略有修改),内容会有 ...
- SpringBoot开发二十-私信列表
私信列表功能开发. 发送私信功能开发 首先创建一个实体类:Message package com.nowcoder.community.entity; import java.util.Date; p ...
- 深入理解-dl_runtime_resolve
深入理解-dl_runtime_resolve 概要 目前大部分漏洞利用常包含两个阶段: 首先通过信息泄露获取程序内存布局 第二步才进行实际的漏洞利用 然而信息泄露的方法并不总是可行的,且获取的内存信 ...
- pikachu 不安全的url跳转
不安全的url跳转问题可能发生在一切执行了url地址跳转的地方.如果后端采用了前端传进来的(可能是用户传参,或者之前预埋在前端页面的url地址)参数作为了跳转的目的地,而又没有做判断的话就可能发生&q ...
- 从 FFmpeg 性能加速到端云一体媒体系统优化
7 月 31 日,阿里云视频云受邀参加由开放原子开源基金会.Linux 基金会亚太区.开源中国共同举办的全球开源技术峰会 GOTC 2021 ,在大会的音视频性能优化专场上,分享了开源 FFmpeg ...
- spring-cloud-sleuth+zipkin追踪服务
1, 父Maven pom 文件 <parent> <groupId>org.springframework.boot</groupId> <artifact ...
- 如何修改leaflet的marker图标
1. 从官网中查看对应文档:https://leafletjs.com/ 2. 3. var greenIcon = L.icon({ iconUrl: 'leaf-green.png', shado ...