因子分析(Factor analysis)
1.引言
在高斯混合和EM算法中,我们运用EM算法拟合混合模型,但是我们得考虑得需要多少的样本数据才能准确识别出数据中的多个高斯模型!看下面两种情况的分析:
- 第一种情况假如有 m 个样本,每个样本的维度是 n, 如果 n » m, 这时哪怕拟合出一个高斯模型都很困难,更不用说高斯混合, 为什么呢?
这和解多元线性方程组是一样的道理,就是自变量的个数多于非线性相关的方程的个数,这必然导致解的不唯一,虽然在解方程的时候可以随便选一个解满足方程组,但是对于某一实际数据集,往往样本对应的概率分布在客观上都是唯一的,只是我们无法简单地用概率论中的几个典型的分布准确表示出来罢了!
- 另一种情况是 m 个样本的维度都较低,用高斯分布对数据建模,用最大似然估计去估计均值(期望)和方差:
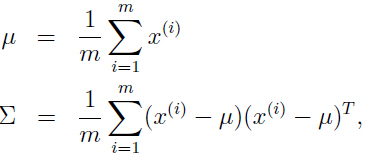
我们会发现,协方差矩阵 Σ 是奇异的,即 Σ 不可逆,Σ-1 不存在,且 但是这两项在计算多元高斯分布时,又都是必不可少的。
但是这两项在计算多元高斯分布时,又都是必不可少的。
所以,除非 m 比 n 大一定较合适的数值,否则对方差和均值的最大似然估计将会很难找到正确的值。
然而,我们仍然能够拟合出关于数据的合理的高斯分布,并且或许还能挖掘出数据的一些有趣的变化结构。如何做到的呢?
2.对 Σ 的约束
如果没有充足的数据拟合出完全的协方差矩阵,就要对协方差矩阵的空间作出一些限制。
- 例如,我们要拟合出一个协方差矩阵使得该矩阵为对角矩阵,在最大似然估计中,对角协方差矩阵满足:
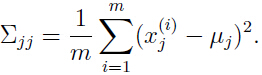
- 有时,要限制这个对角矩阵的元素必须相等,即
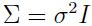 ,其中 I 是单位矩阵,
,其中 I 是单位矩阵,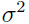 是可以调整元素大小的参数,可以推导出:
是可以调整元素大小的参数,可以推导出:

如果拟合数据的一个无约束的,非稀疏的协方差矩阵,为了保证最大似然估计得出的协方差矩阵Σ 非奇异,必须要求 m ≥ n+1.
但是,要求 Σ 是对角矩阵就意味着所有数据样本的坐标 是独立且非相关的(具体原因回顾概率论有关协方差的知识,参考机器学习中有关概率论知识的小结),
是独立且非相关的(具体原因回顾概率论有关协方差的知识,参考机器学习中有关概率论知识的小结),
通常情况下,如果能捕获出数据中内在的一些感兴趣的相关结构就更好了!如果按照上述的两种约束,做不到这一点。
后面会介绍一种因子分析模型(factor analysis model), 将会使用更多参数而不仅仅是协方差矩阵Σ,捕获出数据中的一些关联,同时不用必须拟合一个全协方差矩阵.
3.高斯分布的边缘分布和条件分布
在讨论因子分析模型之前,先回顾下概率论中的一些知识,就是如何求出多元高斯分布的条件分布和边缘分布。
- 假设一个向量随见变量:
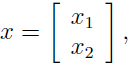
其中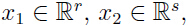
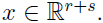 即 x1, x2 都是向量.
即 x1, x2 都是向量.
- 假设
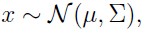 其中:
其中:
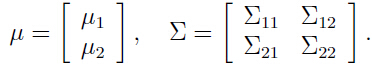
其中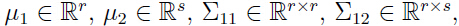 等等。注意由于协方差矩阵式对称矩阵,所以
等等。注意由于协方差矩阵式对称矩阵,所以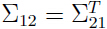
在我们的假设下,x1, x2 服从多元高斯分布,那么什么是x1 的边缘分布呢?
容易看出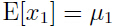 ,
,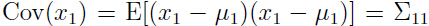
关于 x 的协方差,即 x1, x2 的联合协方差:
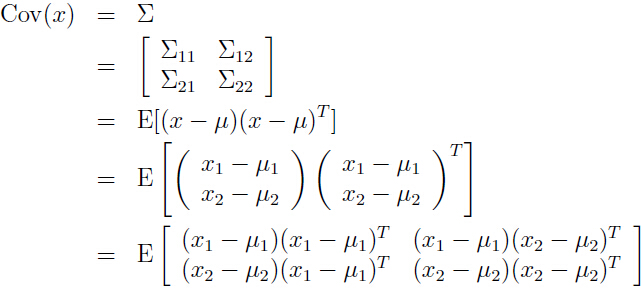
可以看出左上角的分块是与我们计算的 x1 的协方差相一致。
由于高斯分布的边缘分布还是高斯分布,于是 x1 的边缘分(把x2 看成是常量)布写作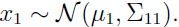
那什么是在给定 x2 时,x1 的条件分布呢?通常被写为: ,其中:
,其中:
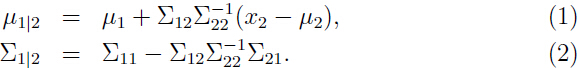
在讨论因此分析模型的时候,这些计算边缘分布和条件分布的式子将会很有用。
4.因子分析模型
在因子分析模型中,假设一个关于 联合分布,其中
联合分布,其中 是隐变量:
是隐变量:
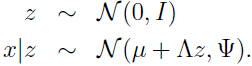
模型中的参数 μ 是向量: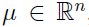 ,矩阵
,矩阵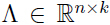 ,矩阵
,矩阵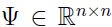 ,k 的取值通常比 n 小.
,k 的取值通常比 n 小.
因此,可以把每一个数据点  看作是从一个 k 维的多元高斯分布
看作是从一个 k 维的多元高斯分布 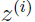 采样得到的.
采样得到的.
可以把上面的因子模型假设等效写成下面的形式(这种等效的意义和目的请看本文最后的总结):
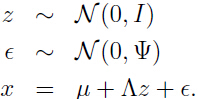
其中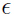 和
和 相互独立。
相互独立。
下面看看我们模型到底定义出了什么样的分布。
由上面的式子可以看出,我们的随机变量 z 和 x 服从联合高斯分布 :
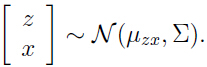
现在来找出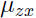 和
和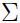 .
.
由上面的条件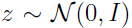 知道:
知道: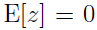 ,所以:
,所以:
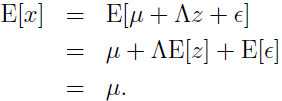
注意上面推理中 矩阵 Λ 不是随机变量,里面的所有元素都是常量,所以 Λ 的期望仍是本身。
因此可以得出:

为了得出,需要计算:
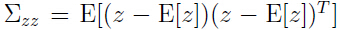
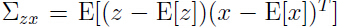
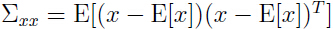
由于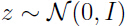 ,所以
,所以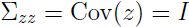
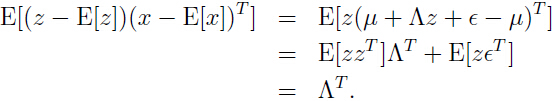
在对后一步中 ,
,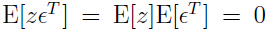
同样有:
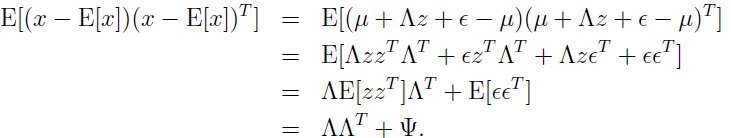
综上所述有:
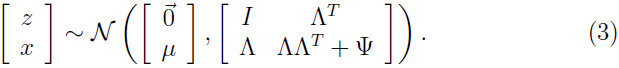
因此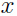 的边缘分布:
的边缘分布: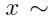
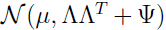
给定一个训练集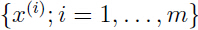 ,那么参数的的对数似然函数为:
,那么参数的的对数似然函数为:
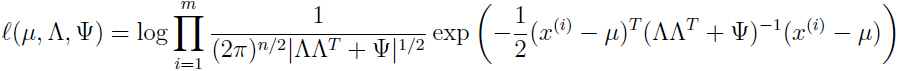
对这个似然函数最大化看上去就很麻烦,确实也很麻烦,但是有稍微简单点的方法,那就是EM算法(EM算法参考EM算法原理详解)
5.EM算法运用于因子分析
- E步:计算
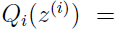
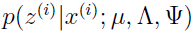
把上面式子(3)的结果代入式子(1)(2),得到:
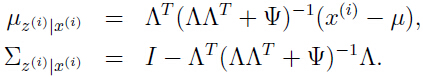
有这两个参数,即数学期望和协方差,可以写出要求的条件高斯分布:

- M步:需要最大化上面分布的关于参数
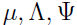 的对数似然函数:
的对数似然函数:

这里以如何优化参数 为例详解,首先把上面的式子简化为:
为例详解,首先把上面的式子简化为:
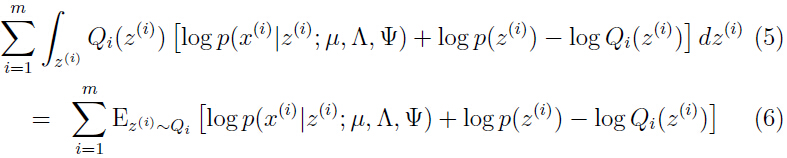
下标 表示
表示 是服从分布
是服从分布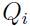 .
.
因为现在要优化参数,所以把与无关的项去掉,因为无关项此时就是常数,没有优化的必要,只需与参数有关的项最大化即可,而我们需要最大化:
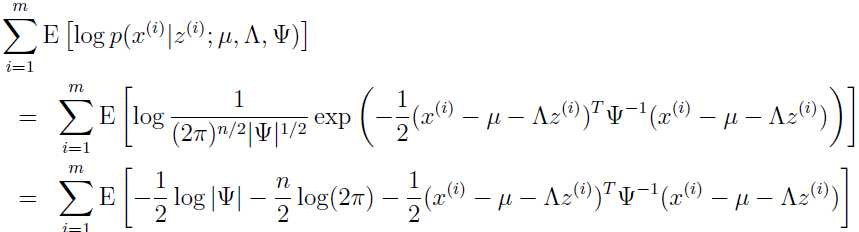
可以发现只有最后一项与参数有关,利用(注意 tr 是线性代数中的“迹”):

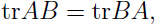
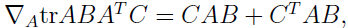
可以得到关于的偏导:

令这个偏导数为0,可以得到:

解出参数:

由的定义知道是一个均值为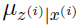 ,方差为
,方差为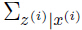 的高斯分布,很容易得到:
的高斯分布,很容易得到:
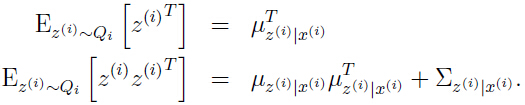
注意后面的一个等式是如何得到的:对于一个随机变量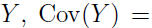
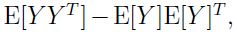 因此
因此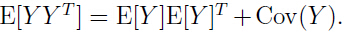
把上面连个等式的结果代入式子(7),可以得到:
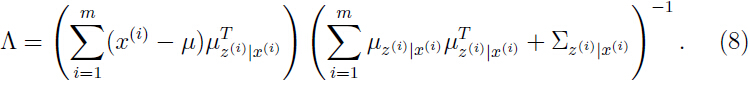
类似地,我们可以优化参数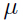 和
和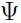 :
:
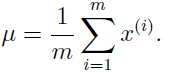
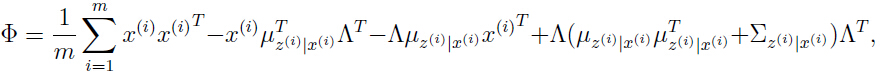
令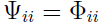 ,即只取矩阵
,即只取矩阵 对角线上的元素.
对角线上的元素.
6.总结
在因子分析模型的讨论中可以发现,因子分析模型就是一种降维的概率模型。可以这么想:
- 要对数据
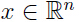 进行建模,而由于维度太高,即 n 太大,处理起来很棘手,那么就想办法对 x 进行线性变换,映射到一个较低维的空间,维度设为 k, k 要远远小于 n, 设每一个数据点
进行建模,而由于维度太高,即 n 太大,处理起来很棘手,那么就想办法对 x 进行线性变换,映射到一个较低维的空间,维度设为 k, k 要远远小于 n, 设每一个数据点 在 k 维空间中对应的数据点是
在 k 维空间中对应的数据点是 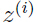 ,由上面讨论可知 数据 z 服从高斯分布
,由上面讨论可知 数据 z 服从高斯分布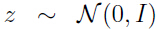 ,且维度较低,就以高斯分布建模很方便。
,且维度较低,就以高斯分布建模很方便。 - 但是 z 毕竟不是我们要建模的数据,于是通过在通过高斯采样得到 之后,运用
 进行线性变换(严格来说叫做仿射变换,这里为了容易理解),将数据 z 由 k 维空间映射到 n 维空间,由于原始数据常常存在噪声,所以我们同样假设了噪声也服从高斯分布,即
进行线性变换(严格来说叫做仿射变换,这里为了容易理解),将数据 z 由 k 维空间映射到 n 维空间,由于原始数据常常存在噪声,所以我们同样假设了噪声也服从高斯分布,即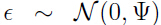 ,所以就得到了原始数据
,所以就得到了原始数据
- 因为每一个都是由相应的经过变换,再加上噪声得来,所以是关于的后验分布,即一开始模型假设中的:
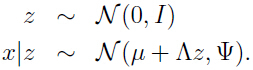
这样建模就避免直接处理高维数据,而是先建模较低维数据,然后通过一定的简单的映射,加上噪声就很容易得出原始数据分布参数,即期望和协方差,且模型假设原始数据服从 高斯分布,所以这个分布就和容易写出来,然后通过高斯采样就可以得到原始数据的非常近似的数据了。
因子分析(Factor analysis)的更多相关文章
- 因子分析(Factor Analysis)
原文地址:http://www.cnblogs.com/jerrylead/archive/2011/05/11/2043317.html 1 问题 之前我们考虑的训练数据中样例的个数m都远远大于其特 ...
- Stat3—因子分析(Factor Analysis)
题注:主成分分析分析与因子分析也有不同,主成分分析仅仅是变量变换,而因子分析需要构造因子模型.主成分分析:原始变量的线性组合表示新的综合变量,即主成分:因子分析:潜在的假想变量和随机影响变量的线性组合 ...
- Andrew Ng机器学习公开课笔记 – Factor Analysis
网易公开课,第13,14课 notes,9 本质上因子分析是一种降维算法 参考,http://www.douban.com/note/225942377/,浅谈主成分分析和因子分析 把大量的原始变量, ...
- 因子分析factor analysis_spss运用_python建模(推荐AAA)
sklearn实战-乳腺癌细胞数据挖掘(博主亲自录制视频) https://study.163.com/course/introduction.htm?courseId=1005269003& ...
- [Scikit-learn] 2.5 Dimensionality reduction - Probabilistic PCA & Factor Analysis
2.5.4. Factor Analysis PPCA的基本性质以及人肉推导: 以上假设z是标准正态分布的情况.以下是对z的分布的扩展,为general normal distribution. Fr ...
- Principal components analysis(PCA):主元分析
在因子分析(Factor analysis)中,介绍了一种降维概率模型,用EM算法(EM算法原理详解)估计参数.在这里讨论另外一种降维方法:主元分析法(PCA),这种算法更加直接,只需要进行特征向量的 ...
- R Language
向量定义:x1 = c(1,2,3); x2 = c(1:100) 类型显示:mode(x1) 向量长度:length(x2) 向量元素显示:x1[c(1,2,3)] 多维向量:multi-dimen ...
- 【机器学习实战】第13章 利用 PCA 来简化数据
第13章 利用 PCA 来简化数据 降维技术 场景 我们正通过电视观看体育比赛,在电视的显示器上有一个球. 显示器大概包含了100万像素点,而球则可能是由较少的像素点组成,例如说一千个像素点. 人们实 ...
- 一步步教你轻松学主成分分析PCA降维算法
一步步教你轻松学主成分分析PCA降维算法 (白宁超 2018年10月22日10:14:18) 摘要:主成分分析(英语:Principal components analysis,PCA)是一种分析.简 ...
随机推荐
- 使用HTTP协议向服务器传参的方式及django中获取参数的方式
使用HTTP协议向服务器传参的四种方式 URL路径携带参数,形如/weather/beijing/2018; 查询字符串(query string),形如key1=value1&key2=va ...
- 使用redis防止抢购商品超卖
前言: redis不仅仅是单纯的缓存,它还有一些特殊的功能,在一些特殊场景上很好用. 本篇博文用来测试下使用redis来防止抢购商品超卖问题. 内容: 使用redis的list进行测试 思路是设置一个 ...
- Final发布点评
1. 约跑App——nice!:为改进演示效果,本组使用摄像头实时采集投影的方式展示其作品,是一种演示的创新.本组重点放在了修改上次来着其他组发现的bug,不过新功能上好像没有加入多少,可能是保证软 ...
- PAT 甲级 1022 Digital Library
https://pintia.cn/problem-sets/994805342720868352/problems/994805480801550336 A Digital Library cont ...
- Ubuntu16解锁root
administrator@rgqancy:~$ sudo passwd -u root [sudo] administrator 的密码: 对不起,请重试. [sudo] administrator ...
- 前端学PHP之会话Session
前面的话 Session技术和Cookie相似,都是用来储存使用者的相关资料.但最大的不同之处在于Cookie是将数据存放在客户端的计算机之中,而Session则是将数据存放于服务器系统之下.Sess ...
- 【设计模式】——抽象工厂Abstract Factory
模式意图 提供对象的使用接口,隐藏对象的创建过程. 模式结构 AbstractFactory 提供创建对象的接口. ConcreteFactory 提供真正创建对象的实现类,用于组合并创建不同的对象, ...
- nginx “403 Forbidden” 错误的原因及解决办法
nginx 的 403 Forbidden errors 表示你在请求一个资源文件但是nginx不允许你查看. 403 Forbidden 只是一个HTTP状态码,像404,200一样不是技术上的错误 ...
- 【刷题】LOJ 6010 「网络流 24 题」数字梯形
题目描述 给定一个由 \(n\) 行数字组成的数字梯形如下图所示.梯形的第一行有 \(m\) 个数字.从梯形的顶部的 \(m\) 个数字开始,在每个数字处可以沿左下或右下方向移动,形成一条从梯形的顶至 ...
- 洛谷 P2146 [NOI2015]软件包管理器 解题报告
P2146 [NOI2015]软件包管理器 题目描述 Linux用户和OSX用户一定对软件包管理器不会陌生.通过软件包管理器,你可以通过一行命令安装某一个软件包,然后软件包管理器会帮助你从软件源下载软 ...