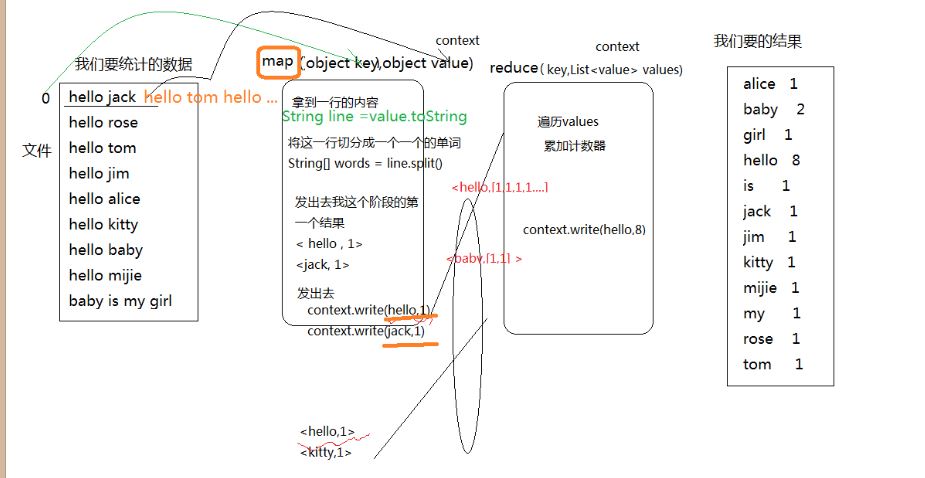
Mapperreduce的wordCount原理
wordcount原理:
1.mapper(Object key,Object value ,Context contex)阶段
2.从数据源读取一行数据传递给mapper函数的value
3.处理数据并将处理结果输出到reduce中去
String line = value.toString();
String[] words = line.split(" ");
context.write(word,1)
4.reduce(Object key ,List<value> values ,Context context)阶段
遍历values累加技术结果,并将数据输出
context.write(word,1)
代码示例:
Mapper类:
package com.hadoop.mr; import java.io.IOException; import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
/**
* Mapper <Long, String, String, Long>
* Mapper<LongWritable, Text, Text, LongWritable>//hadoop对上边的数据类型进行了封装
* LongWritable(Long):偏移量
* Text(String):输入数据的数据类型
* Text(String):输出数据的key的数据类型
* LongWritable(Long):输出数据的key的数据类型
* @author shiwen
*/
public class WordCountMapper extends Mapper<LongWritable, Text, Text, LongWritable>{
@Override
protected void map(LongWritable key, Text value,
Mapper<LongWritable, Text, Text, LongWritable>.Context context)
throws IOException, InterruptedException {
//1.读取一行
String line = value.toString();
//2.分割单词
String[] words = line.split(" ");
//3.统计单词
for(String word : words){
//4.输出统计
context.write(new Text(word), new LongWritable(1));
}
}
}
reduce类
package com.hadoop.mr; import java.io.IOException; import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer; public class WordCountReduce extends Reducer<Text, LongWritable, Text, LongWritable>{
@Override
protected void reduce(Text key, Iterable<LongWritable> values,
Reducer<Text, LongWritable, Text, LongWritable>.Context context)
throws IOException, InterruptedException { long count = 0;
//1.遍历vlues统计数据
for(LongWritable value : values){
count += value.get();
}
//输出统计
context.write(key, new LongWritable(count)); } }
运行类:
package com.hadoop.mr; import java.io.IOException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import com.sun.jersey.core.impl.provider.entity.XMLJAXBElementProvider.Text; public class WordCountRunner {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//1.创建配置对象
Configuration config = new Configuration();
//2.Job对象
Job job = new Job(config); //3.设置mapperreduce所在的jar包
job.setJarByClass(WordCountRunner.class); //4.设置mapper的类
job.setMapOutputKeyClass(WordCountMapper.class);
//5.设置reduce的类
job.setReducerClass(WordCountReduce.class); //6.设置reduce输入的key的数据类型
job.setOutputKeyClass(Text.class);
//7.设置reduce输出的value的数据类型
job.setOutputValueClass(LongWritable.class); //8.设置输入的文件位置
FileInputFormat.setInputPaths(job, new Path("hdfs://192.168.1.10:9000/input"));
//9.设置输出的文件位置
FileOutputFormat.setOutputPath(job, new Path("hdfs://192.168.1.10:9000/input")); //10.将任务提交给集群
job.waitForCompletion(true); } }
Mapperreduce的wordCount原理的更多相关文章
- Hive实现WordCount详解
一.WordCount原理 初学MapReduce编程,WordCount作为入门经典,类似于初学编程时的Hello World.WordCount的逻辑就是给定一个/多个文本,统计出文本中每次单词/ ...
- 4、wordcount程序原理剖析及Spark架构原理
一.wordcount程序原理深度剖析 二.Spark架构原理 1.
- MapReduce本地运行模式wordcount实例(附:MapReduce原理简析)
1. 环境配置 a) 配置系统环境变量HADOOP_HOME b) 把hadoop.dll文件放到c:/windows/System32目录下 c) ...
- Hadoop WordCount单词计数原理
计算文件中出现每个单词的频数 输入结果按照字母顺序进行排序 编写WordCount.java 包含Mapper类和Reducer类 编译WordCount.java javac -classpath ...
- Spark入门实战系列--7.Spark Streaming(上)--实时流计算Spark Streaming原理介绍
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .Spark Streaming简介 1.1 概述 Spark Streaming 是Spa ...
- hadoop运行原理之Job运行(二) Job提交及初始化
本篇主要介绍Job从客户端提交到JobTracker及其被初始化的过程. 以WordCount为例,以前的程序都是通过JobClient.runJob()方法来提交Job,但是现在大多用Job.wai ...
- MapReduce编程job概念原理
在Hadoop中,每个MapReduce任务都被初始化为一个job,每个job又可分为两个阶段:map阶段和reduce阶段.这两个阶段分别用两个函数来表示.Map函数接收一个<key,valu ...
- JStorm第一个程序WordCount详解
一.Strom基本知识(回顾) 1,首先明确Storm各个组件的作用,包括Nimbus,Supervisor,Spout,Bolt,Task,Worker,Tuple nimbus是整个storm任务 ...
- 开源分布式实时计算引擎 Iveely Computing 之 WordCount 详解(3)
WordCount是很多分布式计算中,最常用的例子,例如Hadoop.Storm,Iveely Computing也不例外.明白了WordCount在Iveely Computing上的运行原理,就很 ...
随机推荐
- win10和ubuntu16.04双系统Geom Error
报错信息: Geom Error Reboot and Select proper Boot device or Insert Boot Media in selected Boot device a ...
- ALGO-14_蓝桥杯_算法训练_回文数
问题描述 若一个数(首位不为零)从左向右读与从右向左读都一样,我们就将其称之为回文数. 例如:给定一个10进制数56,将56加65(即把56从右向左读),得到121是一个回文数. 又如:对于10进制数 ...
- Maven编译错误记录:Some Enforcer rules have failed
一.错误信息 添加httpclient与httpcore依赖后编译Maven报错. 错误信息如下: Failed to execute goal org.apache.maven.plugins:ma ...
- 弹性势能,position,min用法,获取元素的宽
弹性势能: 网页div移动的mousemove的次数,跟div移动的距离没有关系,跟鼠标移动的快慢有关,浏览器自身有个计数事件,几毫秒 _this.seed*=0.95 //摩擦系数的写法 posit ...
- k8s服务发现和负载均衡(转)
原文 http://m635674608.iteye.com/blog/2360095 kubernetes中如何发现服务 如何发现pod提供的服务 如何使用kube-dns发现服务 servic ...
- [UE4]定义和使用黑板、使用/赋值黑板变量
黑板,其实就是相当于字典表,一个key对应一个value,key不能重复
- redis作为mysql的缓存服务器(读写分离)
转自:https://www.iyunv.com/thread-52670-1-1.html 一.redis简介Redis是一个key-value存储系统.和Memcached类似,为了保证效率,数据 ...
- sas 日期比较代码备忘
DATA A; SET S.payrecordinfo; YY=DATEPART(AddTime); FORMAT YY MMDDYY10.;RUN; DATA A1; SET ...
- Python的多态、继承与封装
一.多态 不用知道变量所引用的对象类型,还是能对它进行操作,它会根据对象(或类)的类型不同而表现出不同的行为. def run_twice(animal): animal.run() animal.r ...
- Visual Studio 20年
这是一个暴露年龄的话题,如果一个程序员从第一个版本开始使用Visual Studio的话,现在应该是40多岁的中年大叔了.我的程序员生涯是从Visual basic 6.0 (vb6)开始的,一晃就过 ...