探究 encode 和 decode 的使用问题(Python)
很多时候在写Python程序的时候都要在头部添加这样一行代码
#coding: utf-8
或者是这样
# -*- coding:utf-8 -*-
等等
这行代码的意思就是设定同一编码格式为utf-8
计算机中存储数据的编码方式多种多样, 常用的有 unicode, utf-8, gbk, 等等
在Windows系统下,文本文件默认保存的格式应该是gbk
在以一种编码格式保存文件时,应该使用相同的编码进行解析此文件, 不然可能会出现乱码情况
今天就是想记录一下我在写Python程序时,在解析字符串字符串时何时使用decode, 何时使用encode
通常从非unicode编码转换为unicode编码使用decode(解码),相反从unicode编码转换为非unicode编码使用encode(编码)
#coding: utf-8 L = ['你好']
print L
输出
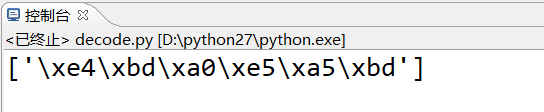
现在是utf-8编码, 一个汉字占3个字节
使用decode进行解码,将 “你好” 的编码转换为unicode
#coding: utf-8 L = ['你好']
print [L[0].decode('utf-8')]
输出

可以看到成功转化为unicode编码, 并且一个汉字占2个字节
那我现在想让utf-8编码的 “你好” 转换为gbk该如何操作呢?
这样试一下
#coding: utf-8 L = ['你好']
print [L[0].encode('gbk')] #错误示例
出现了错误

正确的方式就是先将 utf-8 使用decode转换为 unicode , 在将 unicode 使用encode转换为想要的编码gbk
#coding: utf-8 L = ['你好']
print [L[-1].decode('utf-8').encode('gbk')] # utf-8 -> unicode -> gbk
输出
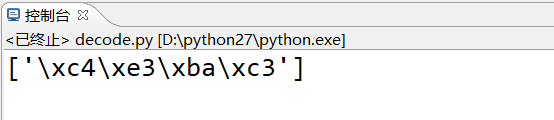
成功转化为gbk编码, 并且一个汉字占2个字节
总结:
(非unicode编码).decode('非unicode') 转换为unicode
(unicode编码).encode('非unicode') 转换为非unicode
如果想要从一种非unicode编码转换为另外一种非unicode编码, 需要借助unicode作为跳板先进行decode, 再进行encode
本节完......
探究 encode 和 decode 的使用问题(Python)的更多相关文章
- 【python】python新手必碰到的问题---encode与decode,中文乱码[转]
转自:http://blog.csdn.net/a921800467b/article/details/8579510 为什么会报错“UnicodeEncodeError:'ascii' codec ...
- 【python】浅谈encode和decode
对于encode和decode,笔者也是根据自己的理解,有不对的地方还请多多指点. 编码的理解: 1.编码:utf-8,utf-16,gbk,gb2312,gb18030等,编码为了便于理解,可以把它 ...
- python encode和decode函数说明【转载】
python encode和decode函数说明 字符串编码常用类型:utf-8,gb2312,cp936,gbk等. python中,我们使用decode()和encode()来进行解码和编码 在p ...
- python的str,unicode对象的encode和decode方法
python的str,unicode对象的encode和decode方法 python中的str对象其实就是"8-bit string" ,字节字符串,本质上类似java中的byt ...
- Python字符串的encode与decode研究心得——解决乱码问题
转~Python字符串的encode与decode研究心得——解决乱码问题 为什么Python使用过程中会出现各式各样的乱码问题,明明是中文字符却显示成“/xe4/xb8/xad/xe6/x96/x8 ...
- Python 关于 encode与decode 中文乱码问题
字符串在Python内部的表示是unicode编码,因此,在做编码转换时,通常需要以unicode作为中间编码,即先将其他编码的字符串解码(decode)成unicode,再从unicode编码(en ...
- [转]python新手必碰到的问题---encode与decode,中文乱码--转载
edu.codepub.com/2009/1029/17037.php 这个问题在python3.0里已经解决了. 这有篇很好的文章,可以明白这个问题: 为什么会报错“UnicodeEncodeErr ...
- python的str,unicode对象的encode和decode方法(转)
python的str,unicode对象的encode和decode方法(转) python的str,unicode对象的encode和decode方法 python中的str对象其实就是" ...
- Python学习-is和==区别, encode和decode
一.is 和 == 介绍 1. is 比较的是两个对象的内存地址是否相同,它们是不是同一个对象. 2. == 比较的是两个对象的内容是否相同. 在使用is前,先介绍Python的一个内置函数id( ...
随机推荐
- bzoj3884上帝与集合的正确用法
Description 根据一些书上的记载,上帝的一次失败的创世经历是这样的: 第一天, 上帝创造了一个世界的基本元素,称做“元”. 第二天, 上帝创造了一个新的元素,称作“α”.“α”被定义为“ ...
- suoi16 随机合并试卷 (dp)
算出来每个数被计算答案的期望次数就可以 考虑这个次数,我们可以把一次合并反过来看,变成把一个数+1然后再复制一个 记f[i][j]为一共n个数时第j个数的期望次数,就可以得到期望的递推公式,最后拿f[ ...
- Python OS模块中的fork方法实现多进程
import os '''使用OS模块中的fork方式实现多进程''' '''fork方法返回两次,分别在父进程和子进程中返回,子进程中永远返回0,父进程返回的是子进程的is''' if __name ...
- java web 验证码-字符变形(推荐)
该文章转载自:http://www.cnblogs.com/jianlun/articles/5553452.html 因为在我做的这个系统中发现验证码有点偏上,整体效果看起来不太好,就做了一些修改. ...
- StratifiedKFold与GridSearchCV版本前后使用方法
首先在sklearn官网上你可以看到: 所以,旧版本import时: from sklearn.cross_validation import GridSearchCV 新版本import时: fro ...
- 个推基于 Apache Pulsar 的优先级队列方案
作者:个推平台研发工程师 祥子 一.业务背景在个推的推送场景中,消息队列在整个系统中占有非常重要的位置.当 APP 有推送需求的时候, 会向个推发送一条推送命令,接到推送需求后,我们会把APP要求推送 ...
- P3932 浮游大陆的68号岛
P3932 浮游大陆的68号岛 妖精仓库的储物点可以看做在一个数轴上.每一个储物点会有一些东西,同时他们之间存在距离. 每次他们会选出一个小妖精,然后剩下的人找到区间[l,r]储物点的所有东西,清点完 ...
- Git与GitHub学习笔记(三).gitignore文件忽略和删除本地以及远程文件
一.Git提供了文件忽略功能.当对工作区某个目录或者某些文件设置了忽略后,git将不会对它们进行追踪 HELP:如何在IntelliJ IDEA中使用.ignore插件忽略不必要提交的文件 问题:最近 ...
- [转载]Frontend Knowledge Structure
https://github.com/JacksonTian/fks http://code.csdn.net/news/2819224 本文为大家整理了一系列关于JavaScript的常用工具,包括 ...
- 20155303 2016-2017-2 《Java程序设计》第五周学习总结
20155303 2016-2017-2 <Java程序设计>第五周学习总结 教材学习中的问题和解决过程 『问题一』:受检异常与非受检异常 『问题一解决』: 受检异常:这种在编译时被强制检 ...