【慕课网实战】Spark Streaming实时流处理项目实战笔记三之铭文升级版
铭文一级:
Flume概述
Flume is a distributed, reliable,
and available service for efficiently collecting(收集),
aggregating(聚合), and moving(移动) large amounts of log data
webserver(源端) ===> flume ===> hdfs(目的地)
设计目标:
可靠性
扩展性
管理性
业界同类产品的对比
(***)Flume: Cloudera/Apache Java
Scribe: Facebook C/C++ 不再维护
Chukwa: Yahoo/Apache Java 不再维护
Kafka:
Fluentd: Ruby
(***)Logstash: ELK(ElasticSearch,Kibana)
Flume发展史
Cloudera 0.9.2 Flume-OG
flume-728 Flume-NG ==> Apache
2012.7 1.0
2015.5 1.6 (*** + )
~ 1.7
Flume架构及核心组件
1) Source 收集
2) Channel 聚集
3) Sink 输出
Flume安装前置条件
Java Runtime Environment - Java 1.7 or later
Memory - Sufficient memory for configurations used by sources, channels or sinks
Disk Space - Sufficient disk space for configurations used by channels or sinks
Directory Permissions - Read/Write permissions for directories used by agent
安装jdk
下载
解压到~/app
将java配置系统环境变量中: ~/.bash_profile
export JAVA_HOME=/home/hadoop/app/jdk1.8.0_144
export PATH=$JAVA_HOME/bin:$PATH
source下让其配置生效
检测: java -version
安装Flume
下载
解压到~/app
将java配置系统环境变量中: ~/.bash_profile
export FLUME_HOME=/home/hadoop/app/apache-flume-1.6.0-cdh5.7.0-bin
export PATH=$FLUME_HOME/bin:$PATH
source下让其配置生效
flume-env.sh的配置:export JAVA_HOME=/home/hadoop/app/jdk1.8.0_144
检测: flume-ng version
example.conf: A single-node Flume configuration
使用Flume的关键就是写配置文件
A) 配置Source
B) 配置Channel
C) 配置Sink
D) 把以上三个组件串起来
a1: agent名称
r1: source的名称
k1: sink的名称
c1: channel的名称
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = hadoop000
a1.sources.r1.port = 44444
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
启动agent
flume-ng agent \
--name a1 \
--conf $FLUME_HOME/conf \
--conf-file $FLUME_HOME/conf/example.conf \
-Dflume.root.logger=INFO,console
使用telnet进行测试: telnet hadoop000 44444
Event: { headers:{} body: 68 65 6C 6C 6F 0D hello. }
Event是FLume数据传输的基本单元
Event = 可选的header + byte array
铭文二级:
Flume设计目标:可靠性,扩展性,管理性
官网:flume.apache.org -> Documentation(左栏目) -> Flume User Guide
左栏为目录,较常用的有:
Flume Sources:avro、exec、kafka、netcat
Flume Channels:memory、file、kafka
Flume Sinks:HDFS、Hive、logger、avro、ElasticSearch、Hbase、kafka
注意:每个source、channel、sink都有custom自定义类型
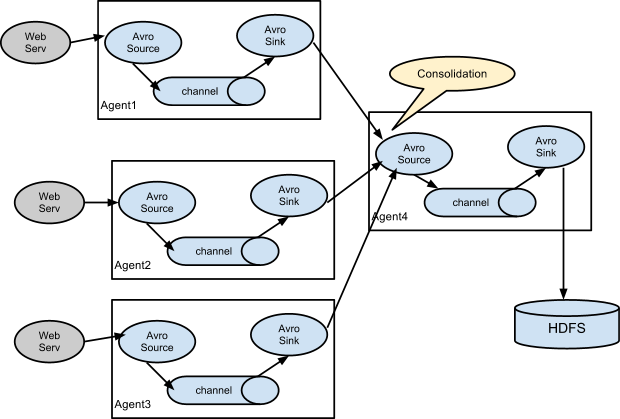
Setting multi-agent flow

Consolidation
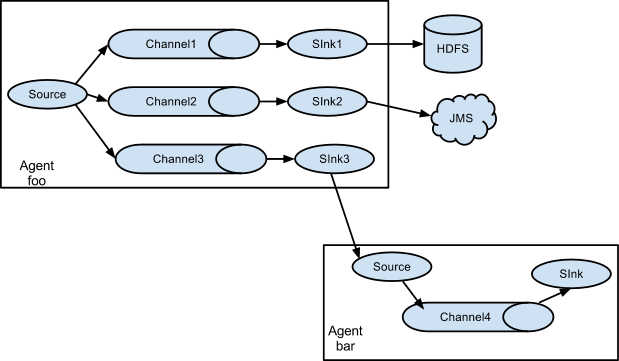
Multiplexing the flow
实战准备=>
1.前置要求为以上铭文一4点,Flume的下载可以在cdh5里wget下来
wget http://archive.cloudera.com/cdh5/cdh/5/flume-ng-1.6.0-cdh5.5.0.tar.gz
2.安装jdk,指令:tar -zxvf * -C ~/app/ ,最后勿忘:source ~/.bash_profile
配置cp flume-env.sh.template flume-env.sh ,export JAVA_HOME=/home/hadoop/app/jdk1.8.0_144
3.检测是否安装成功:flume-ng version
实战步骤=>
实战需求:从指定的网络端口采集数据输出到控制台
配置文件(创建example.conf于conf文件夹中,主要是看官网!):
1、a1.后面的source、channel、sink、均有"s"
2、后面连接是,sources后面的channel有"s",sink后面的chanel无"s"
启动agent=>
flume-ng agent \
--name a1 \
--conf $FLUME_HOME/conf \
--conf-file $FLUME_HOME/conf/example.conf \
-Dflume.root.logger=INFO,console
启动另一终端ssh上,使用telnet进行监听: telnet hadoop000 44444
原本的终端输入内容,可以在此终端接受到
【慕课网实战】Spark Streaming实时流处理项目实战笔记三之铭文升级版的更多相关文章
- 【慕课网实战】Spark Streaming实时流处理项目实战笔记十之铭文升级版
铭文一级: 第八章:Spark Streaming进阶与案例实战 updateStateByKey算子需求:统计到目前为止累积出现的单词的个数(需要保持住以前的状态) java.lang.Illega ...
- 【慕课网实战】Spark Streaming实时流处理项目实战笔记七之铭文升级版
铭文一级: 第五章:实战环境搭建 Spark源码编译命令:./dev/make-distribution.sh \--name 2.6.0-cdh5.7.0 \--tgz \-Pyarn -Phado ...
- 【慕课网实战】Spark Streaming实时流处理项目实战笔记十四之铭文升级版
铭文一级: 第11章 Spark Streaming整合Flume&Kafka打造通用流处理基础 streaming.conf agent1.sources=avro-sourceagent1 ...
- 【慕课网实战】Spark Streaming实时流处理项目实战笔记二之铭文升级版
铭文一级: 第二章:初识实时流处理 需求:统计主站每个(指定)课程访问的客户端.地域信息分布 地域:ip转换 Spark SQL项目实战 客户端:useragent获取 Hadoop基础课程 ==&g ...
- 【慕课网实战】Spark Streaming实时流处理项目实战笔记十六之铭文升级版
铭文一级: linux crontab 网站:http://tool.lu/crontab 每一分钟执行一次的crontab表达式: */1 * * * * crontab -e */1 * * * ...
- 【慕课网实战】Spark Streaming实时流处理项目实战笔记十五之铭文升级版
铭文一级:[木有笔记] 铭文二级: 第12章 Spark Streaming项目实战 行为日志分析: 1.访问量的统计 2.网站黏性 3.推荐 Python实时产生数据 访问URL->IP信息- ...
- 【慕课网实战】Spark Streaming实时流处理项目实战笔记十二之铭文升级版
铭文一级: ======Pull方式整合 Flume Agent的编写: flume_pull_streaming.conf simple-agent.sources = netcat-sources ...
- 【慕课网实战】Spark Streaming实时流处理项目实战笔记十一之铭文升级版
铭文一级: 第8章 Spark Streaming进阶与案例实战 黑名单过滤 访问日志 ==> DStream20180808,zs20180808,ls20180808,ww ==> ( ...
- 【慕课网实战】Spark Streaming实时流处理项目实战笔记九之铭文升级版
铭文一级: 核心概念:StreamingContext def this(sparkContext: SparkContext, batchDuration: Duration) = { this(s ...
- 【慕课网实战】Spark Streaming实时流处理项目实战笔记八之铭文升级版
铭文一级: Spark Streaming is an extension of the core Spark API that enables scalable, high-throughput, ...
随机推荐
- AngularJS——第1章 简介
第1章 简介 由谷歌公司开发维护的前端MVC框架,克服了HTML在构建应用上的诸多不足,降低了开发成本,提高了效率. 一个框架 以数据和逻辑作为驱动 AngularJS核心特性:模块化,双数据绑定,语 ...
- 已经卸载了hyper-v 仍然提示 vmware 与 hyper-v 不兼容;天天模拟器,提示VT模式没有开启,BIOS里面已经设置过了
环境win10,vm的失败和模拟器的失败都是hyper-v冲突导致的...网上看了很多千篇一律的都只是提到了卸载hyper-v,实际上我电脑仅仅卸载hyper-v是不够的. 解决办法: 卸载 hype ...
- An enumerable sequence of parameters (arrays, lists, etc) is not allo
环境:dapper asp.net core 出错代码如下: public Task<IEnumerable<dynamic>> GetList(string query, p ...
- TotoiseSVN 使用参考文章
SVN使用教程总结 http://www.cnblogs.com/armyfai/p/3985660.html TotoiseSVN的基本使用方法 http://www.cnblogs.com/xil ...
- JavaScript 中 如何判断一个元素是否在一个数组中
<script type="text/javascript"> var arrList=['12','qw','q','v','d','t']; console.log ...
- 19.Mysql优化数据库对象
19.优化数据库对象19.1 优化表的数据类型应用设计时需要考虑字段的类型和长度,并留有一定长度冗余.procedure analyse()函数可以对表中列的数据类型提出优化建议.procedure ...
- 4.Mysql中的运算符
4.Mysql中的运算符运算符用来连接表达式.运算符包括:算术运算符.比较运算符.逻辑运算符.位运算符. 4.1 算术运算符算术运算符包括加(+).减(-).乘(*).除(/).取模(%,MOD) 5 ...
- hdu 1539 & poj 1416 某某公司
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=1539 大意是输入n和m,把m按顺序拆分成若干个数,问这些数和的在小于n的前提下最大为多少 注意必须m的 ...
- 洛谷1993 小K的农场
原题链接 裸的差分约束. \(X_a-X_b\geqslant C\) \(X_a-X_b\leqslant C\Rightarrow X_b-X_a\geqslant -C\) \(X_a-X_b\ ...
- socket 长连接
实现: 长连接的维持,是要客户端程序,定时向服务端程序,发送一个维持连接包的. 如果,长时间未发送维持连接包,服务端程序将断开连接. 服务端: 由于客户端会定时(keepAliveDelay毫秒)发送 ...